
Naming conventions are often quite different in statistics and data science, which causes quite a bit of confusion. Part of the problem with naming conventions is that “…data science is the child of statistics and computer science” (Blei & Symth, 2017) . In essence, data science then is the child of two parents who speak different languages. In one sense, this makes the job of the data scientist not only to apply the knowledge from both “parents”, but to also act as a translator between the two, which is where a dictionary comes in handy.
Of, course, many terms are universal. For example, regression analysis and Bayesian Inference mean the same thing no matter what field you’re working in. Others are completely different, like the Xi‘s in data: if you’re a statistician, those are covariates. A data scientist would call those features, a name borrowed from computer science.
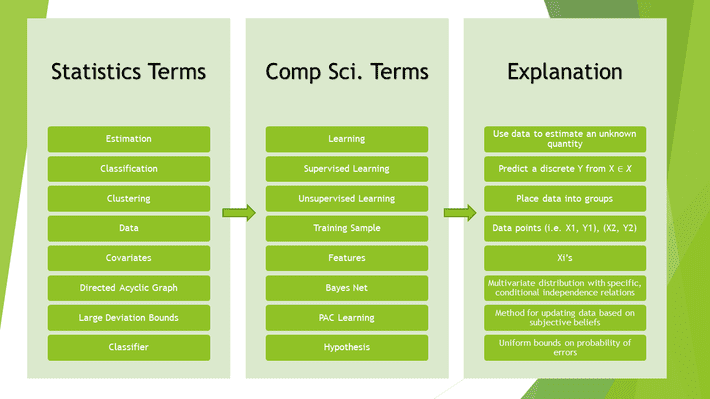
So, let’s clear up a few of the more common mismatches. The following picture is adapted from Larry Wasserman’s All of Statistics. His dictionary was an eye opener for me when I first started studying data science; Hopefully it will clear up some of those fuzzy definitions for you as well.
References
Blei, D. and Symth, P. “Science and Data Science,” Proceedings of the National Academies of Sciences, vol. 114, no. 33, June 2017, pp. 8689-8692.
Wasserman, L. (2004). All of Statistics: A Concise Course in Statistical Inference. Springer.
){kind=link}