
How good is a certain soccer player? Let’s find out applying Machine Learning to Fifa 18!
I’m sure you’ve probably heard about the 2018 FIFA Football World Cup in Russia everywhere during the last few months. And, if you are a techy too, I guess you also have realized that Machine Learning and Artificial Intelligence are buzzwords too. So, what better way to get ready for the World Cup than by practicing in a project that combines these two hot topics? In order to do that, we’re going to leverage a dataset of the Fifa 2018 video game. My goal is to show you how to create a predictive model that is able to forecast how good a soccer player is based on their game statistics (using Python in a Jupyter Notebook).
Fifa is one of the most well-known video games around the world. You’ve probably played it at least once, right? Although I’m not a fan of video games, when I saw this dataset collected by Aman Srivastava, I immediately thought that it was great for practicing some of the basics of any Machine Learning Project.
The Fifa 18 dataset was scraped from the website sofifa.com containing statistics and more than 70 attributes for each player in the Full version of FIFA 18. In this Github Project, you can access the CSV files that compose the dataset and some Jupyter notebooks with the python code used to collect the data.
Having said this, now let’s start!
Getting started with the machine learning tutorial
We explained most of the basic concepts related to smart systems and how machine learning techniques could add smart capabilities to many kinds of systems in almost any domain that you can imagine. Among other things, we learned that a typical workflow for a Machine Learning Project usually looks like the one shown in the image below:
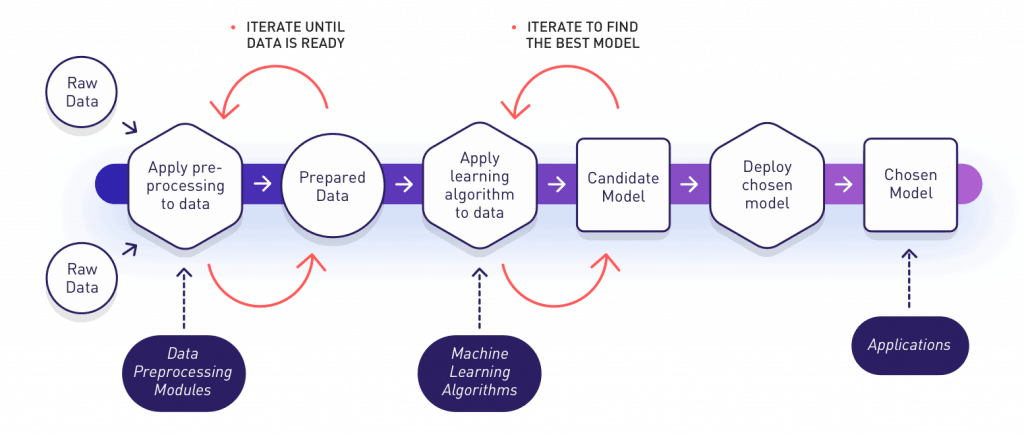
In this post we’ll go through a simplified view of this whole process, with a practical implementation of each phase. The main objective is to show most of the common steps performed during any machine learning project. Therefore, you could use it as a start point in case you need to address a machine learning project from scratch.
In what follows, we will:
- Apply some preprocessing steps to prepare the data.
- Then, we will perform a descriptive analysis of the data to better understand the main characteristics that they have.
- We will continue by practicing how to train different machine learning models using scikit-learn. It is one of the most
popular python libraries for machine learning. We will also use a subset of the dataset for training purposes. - Then, we will iterate and evaluate the learned models by using unseen data. Later, we will compare them until we find a
good model that meets our expectations. - Once we have chosen the candidate model, we will use it to perform predictions and to create a simple web application that
consumes this predictive model.
At the end we will arrive at a funny smart app like the one below. It will be able to predict how good a soccer player is based on their game statistics. Sounds cool, yeah? Well, let’s dive in!
1. Preparing the Data
Generally any machine learning project has an initial stage known as data prepapration, data cleaning or the preprocessing phase.
Its main objective is to collect and prepare the data that the learning algorithms will use during the training phase. In our practical and concrete example, an important part of this was already addressed by Aman Srivastava when he scraped different pages from the website sofifa.com. In his Github Project you can access some of the jupyter notebooks with the python code that acts as the data preprocessing modules that were applied to get and generate the original dataset for our project. Below, as an example, we can see the module that does the web scraping of the raw data (html format) and how it transforms the data into a Pandas dataframe (Pandas is a famous Python library for data processing). Finally it generates a csv file with the results. In some way, this data preparation step can be seen like something similar to the old ETLs (extract, transform, load) database processes.
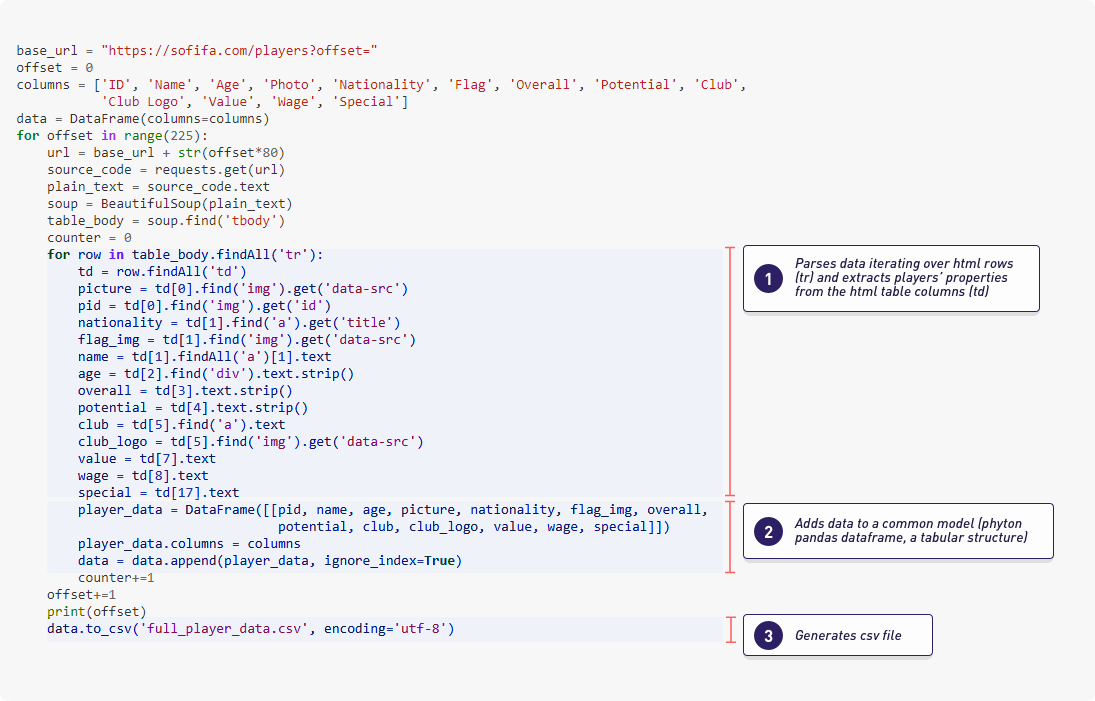
{kind=link}