
Here I am writing my first post, I posponed it for a long time… In this article I would like to share my experience installing and testing basic Apache Kafka features. If you are new in the Big Data ecosystem let me give you some short concepts.
Kafka is a distributed streaming platform which means is intended for publish and subscribe to streams of records, similar to a message queue or enterprise messaging system [1]
Kafka has four core APIs but in this post I will test 2 of them:
- The Producer API allows an application to publish a stream of records to one or more Kafka topics. [2]
- The Consumer API allows an application to subscribe to one or more topics and process the stream of records produced to them. [3]
Another important concept necessary for this article is Topic. A topic is a category or feed name to which records are published. Topics in Kafka are always multi-subscriber; that is, a topic can have zero, one, or many consumers that subscribe to the data written to it. [4]
[Kafka schema] 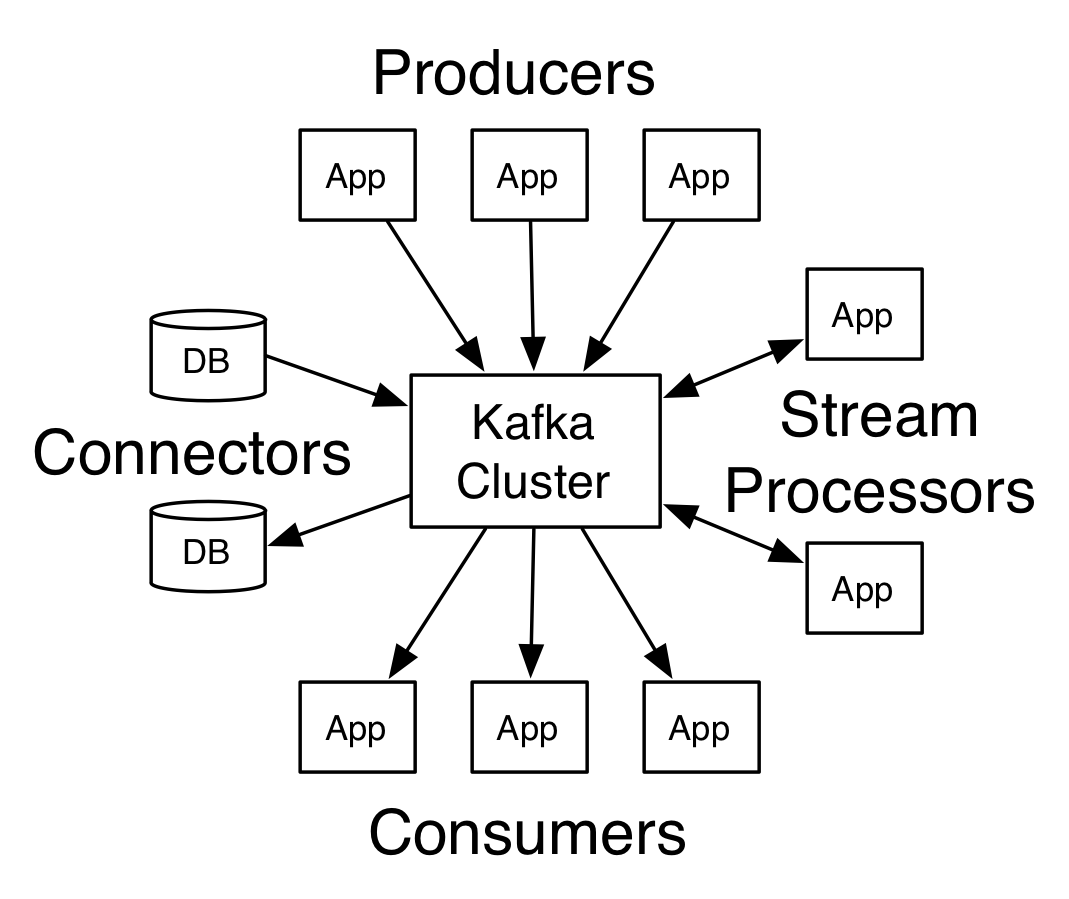
After this brief introduction we can start the tutorial.
1. Google Cloud account: create a google cloud account is free and you will get $300 of credit to try any of their products for one year.
[Google Cloud account]
2. Creating a project : a project is necessary to create the VM
[Image Creating a project]
3. Creating VM instance : in this occasion I used Debian OS and the default parameters, then we need to connect using the web SSH.
[Creating VM instante 1]
[Creating VM instante 2]
[Starting SSH]

4. Installing Java 8
sudo apt-get install software-properties-common
sudo add-apt-repository “deb http://ppa.launchpad.net/webupd8team/java/ubuntu xenial main”
sudo apt-get update
sudo apt-get install oracle-java8-installer
javac -version
[Oracle will prompt some terms and conditions to install ]

5. Installing and starting Zookeeper
wget http://www-eu.apache.org/dist/zookeeper/zookeeper-3.4.10/zookeeper-…
tar -zxf zookeeper-3.4.10.tar.gz
sudo mv zookeeper-3.4.10 /usr/local/zookeeper
sudo mkdir -p /var/lib/zookeeper
cat > /usr/local/zookeeper/conf/zoo.cfg EOF
> tickTime=2000
> dataDir=/var/lib/zookeeper
> clientPort=2181
> EOF
export JAVA_HOME=/usr/java/jdk1.8.0_181
sudo /usr/local/zookeeper/bin/zkServer.sh start
[Installing]

[Starting]

6. Installing and starting Kafka
wget http://www-eu.apache.org/dist/kafka/2.0.0/kafka_2.12-2.0.0.tgz
tar -zxf kafka_2.12-2.0.0.tgz
sudo mv kafka_2.12-2.0.0 /usr/local/kafka
sudo mkdir /tmp/kafka-logs
export JAVA_HOME=/usr/java/jdk1.8.0_181
sudo /usr/local/kafka/bin/kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties
[Installing]

7. Creating a topic
sudo /usr/local/kafka/bin/kafka-topics.sh –create –zookeeper localhost:2181 –replication-factor 1 –partitions 1 –topic llamada

8. Verifying a topic
sudo /usr/local/kafka/bin/kafka-topics.sh –zookeeper localhost:2181 –describe –topic llamada

9. Producing a message (ctrl+c to end producing messages)
sudo /usr/local/kafka/bin/kafka-console-producer.sh –broker-list localhost:9092 –topic llamada
>hello kafka
>second message

10. Consuming messages
sudo /usr/local/kafka/bin/kafka-console-consumer.sh –bootstrap-server localhost:9092 –topic llamada –from-beginning

11. Listing topics
sudo /usr/local/kafka/bin/kafka-topics.sh –list –zookeeper localhost:2181

12. Getting details about a topic
sudo /usr/local/kafka/bin/kafka-topics.sh –zookeeper localhost:2181 –describe –topic llamada

*If you get error about replication factor, please try starting Kafka
sudo /usr/local/kafka/bin/kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties
Finally I encourage to check the web https://kafka.apache.org/ there you will find excellent information about other Kafka’s capabilities to go further. Also I recommend you to read Kafka: The Definitive Guide by Neha Narkhede; Gwen Shapira; Todd Palino.
See you in the next article!
[1] https://kafka.apache.org/intro
[2] https://kafka.apache.org/documentation.html#producerapi
[3] https://kafka.apache.org/documentation.html#consumerapi
[4] https://kafka.apache.org/intro#intro_topics
[5] https://www.safaribooksonline.com/library/view/kafka-the-definitive/9781491936153/ch11.html
{kind=link}