
This article was written by Liang-Chieh Chen and Yukun Zhu.
Semantic image segmentation, the task of assigning a semantic label, such as “road”, “sky”, “person”, “dog”, to every pixel in an image enables numerous new applications, such as the synthetic shallow depth-of-field effect shipped in the portrait mode of the Pixel 2 and Pixel 2 XL smartphones and mobile real-time video segmentation. Assigning these semantic labels requires pinpointing the outline of objects, and thus imposes much stricter localization accuracy requirements than other visual entity recognition tasks such as image-level classification or bounding box-level detection.
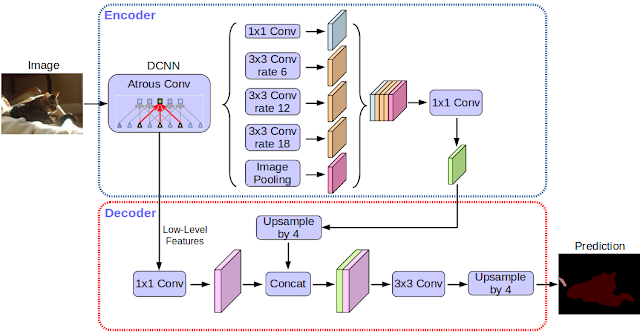
Today, we are excited to announce the open source release of our latest and best performing semantic image segmentation model, DeepLab-v3+ [1]*, implemented in TensorFlow. This release includes DeepLab-v3+ models built on top of a powerful convolutional neural network (CNN) backbone architecture [2, 3] for the most accurate results, intended for server-side deployment. As part of this release, we are additionally sharing our TensorFlow model training and evaluation code, as well as models already pre-trained on the Pascal VOC 2012 and Cityscapes benchmark semantic segmentation tasks.
To read the rest of the article, with illustrations, click here.
{kind=link}