
In this Blog 3 – We will see what is Apache Spark’s History and Unified Platform for Big Data, and like to have quick read on blog 1 and blog 2.
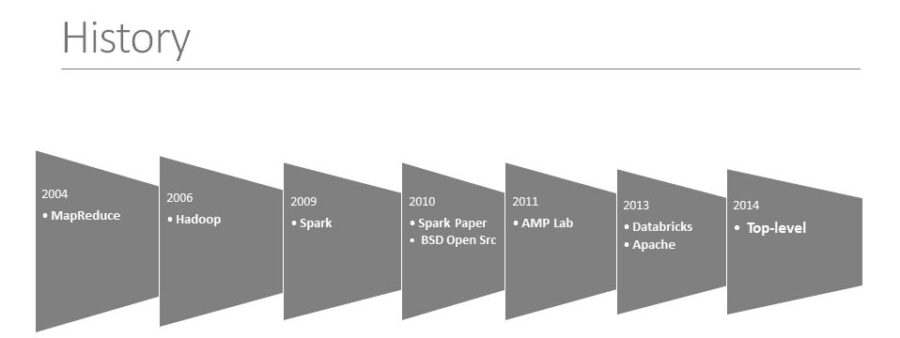
Spark was initially started by Matei at UC Berkeley AMPLab in 2009, and open sourced in 2010 under a BSD license. In 2013, the project was donated to the Apache Software foundation and switched its license to Apache 2.0. In February 2014, Spark became a Top level Apache Project. And in November 2014, the engineering team at Databricks used Spark and set a new world record in large scale sorting. And latest version of Apache Spark is 1.6, with many new features.
Many of the ideas behind the system are presented in various research papers.
And now how does Spark related to Hadoop, Spark is a fast and general processing engine compatible with Hadoop data which can run in Hadoop clusters through YARN or Spark’s standalone mode. It can process the data from HDFS, HBase, Cassandra, Hive, and any Hadoop InputFormat. It is designed to perform both batch processing similar to MapReduce and new workloads like streaming, interactive queries, and machine learning.
But before Apache Spark how we solved the big data problem, and what are the tools we have used. And we have to use 20+ tools to deploy big data application in production.

But how Apache Spark, a unified big data platform helps to solve the big data problem,

And to conclude Apache Spark is best fit for parallel in-memory processing across platform, multiple data sources, applications and users. Few of the Apache Spark’s use cases are OLAP Analytics, Operational Analytics, Complex Data Pipelining, and more.
In Blog 4 – We will share on Apache Spark’s First Step – AWS, Apache Spark.
Originally posted here.
{kind=link}