
Exploring San Francisco police incident data and visualizing the density distribution of incidents involving mentally ill individuals using Pivot Billions and Tableau.
With a population of over 800,000 people within approximately 47 square miles, San Francisco is one of the most densely populated cities in the United States. Cities with this level of population density must contend with a high level of policing activity to ensure safety. I wanted to explore just how safe it actually is so I decided to analyze the SF Police Calls for Services and Incidents dataset from Kaggle which covers many years (2003-2017) of policing data and contains a variety of useful information about each record.
Starting with the police-department-incidents.csv file and loading it into Pivot Billions, I quickly renamed the x and y fields to what they truly were (longitude and latitude) and started to view the whole data. Getting a quick distribution of the Resolution column I was able to see the different ways each police incident was resolved and get an idea for how common each resolution was.
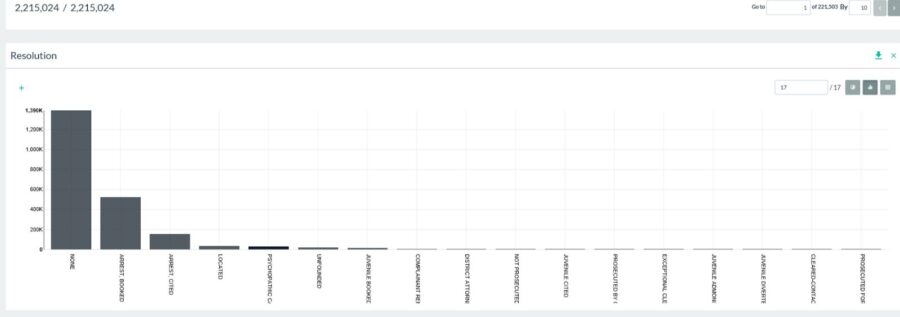
I was surprised to discover that a resolution of “Psychopathic Cases” occurred nearly 30,000 times across the data! What the heck?! Is San Francisco a city of psychopaths? Sure San Francisco has had its share of famous serial killers, but this hardly seemed likely.
To investigate this further, I simply applied a filter on the Resolution column in Pivot Billions to show only the data that ended up classified as a “Psychopathic Case” by the San Francisco PD. I then downloaded this filtered data to visualize in Tableau, choosing to also drop the Location column since Tableau has trouble interpreting it.
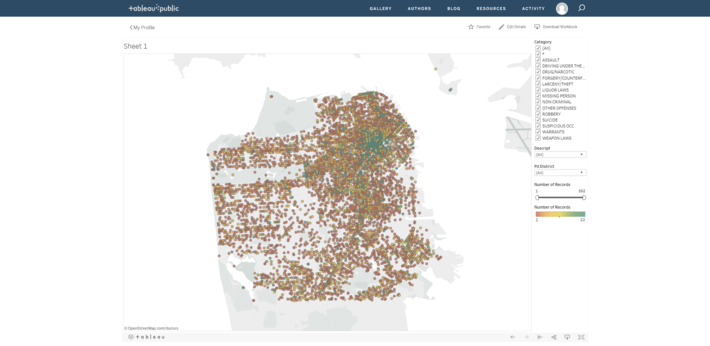
Now that my data was in a size and format manageable for Tableau, I loaded the data into Tableau as a Text file and graphed the data by the latitude and longitude columns. By adding the Address and Number of Rows data to the visualization and quickly integrating some interactive filters and highlighters, I ended up with a useful and informative visualization of my Policing data.
This interactive map shows where each “Psychopathic Case” police incident occurred and how many incidents were recorded at that location. We can clearly see that there is a high concentration of these cases in Northeast San Francisco. By using the interactive filters in my visualization it was easy to determine that the Central, Northern, Southern, and Tenderloin districts are the main districts where such incidents were recorded the most.
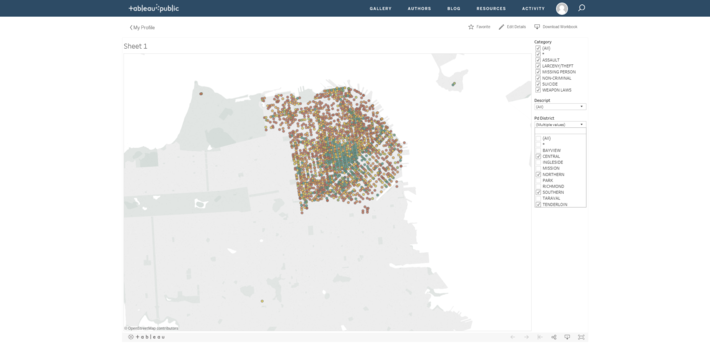
So is San Francisco a city overrun by psychopaths? Hardly.
A little further digging reveals that the vast majority of these so called psychopathic resolutions were in fact “non-criminal – aided cases” where a mentally ill person was involved.
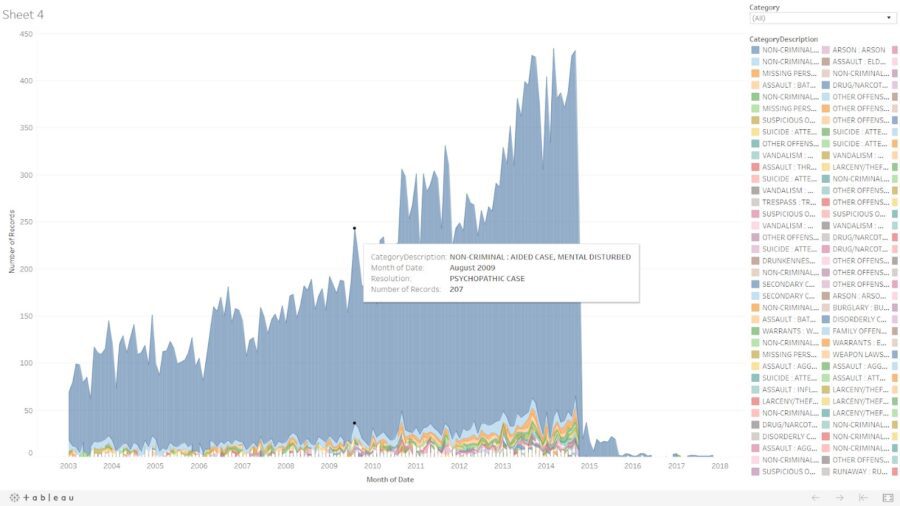
In fact if you look at the Psychopathic Case designation over time, you notice that it disappears almost entirely after 2014.
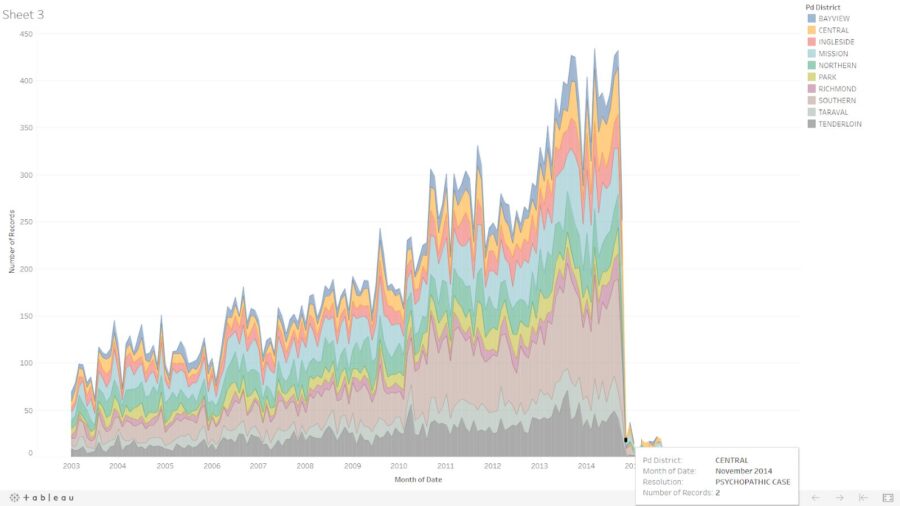
It looks like this is a case of poor classification of a very serious problem that police in all major cities have to deal with, and that is the rise of mental health related incident calls. It is a promising sign that despite the slew of high profile incidents between law enforcement and the mentally ill in San Francisco, the SFPD are moving in the right direction and starting to limit the use of the “Psychopathic Case” designation.
If you want to explore more of this data please feel free to go through my workbook on Tableau Public.

{kind=link}