
This article was written by Jean-Marc Valin.
This demo presents the RNNoise project, showing how deep learning can be applied to noise suppression. The main idea is to combine classic signal processing with deep learning to create a real-time noise suppression algorithm that’s small and fast. No expensive GPUs required — it runs easily on a Raspberry Pi. The result is much simpler (easier to tune) and sounds better than traditional noise suppression systems (been there!).
Noise Suppression
Noise suppression is a pretty old topic in speech processing, dating back to at least the 70s. As the name implies, the idea is to take a noisy signal and remove as much noise as possible while causing minimum distortion to the speech of interest.
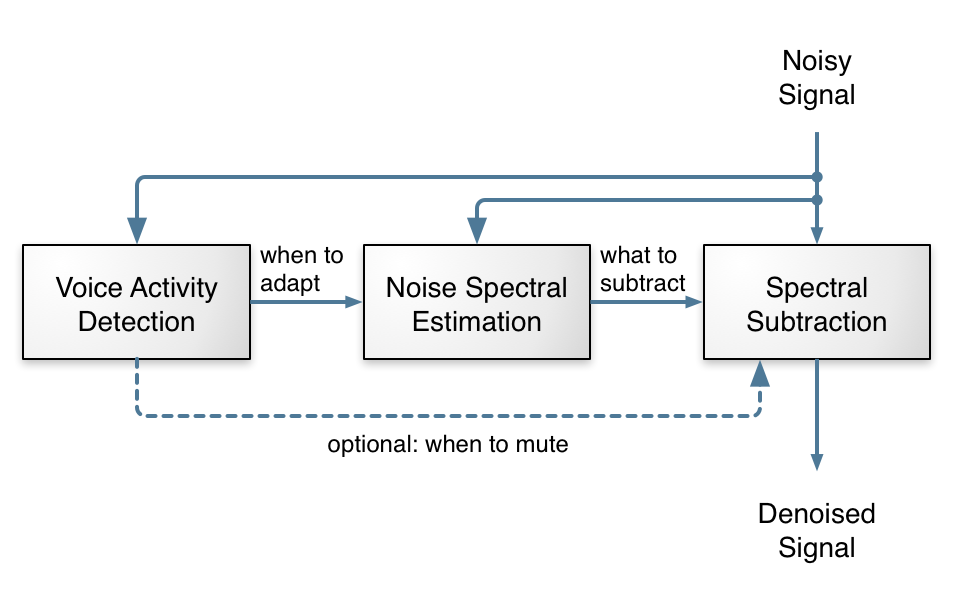
From looking at the figure above, noise suppression looks simple enough: just three conceptually simple tasks and we’re done, right? Right — and wrong! Any undergrad EE student can write a noise suppression algorithm that works… kinda… sometimes. The hard part is to make it work well, all the time, for all kinds of noise. That requires very careful tuning of every knob in the algorithm, many special cases for strange signals and lots of testing. There’s always some weird signal that will cause problems and require more tuning and it’s very easy to break more things than you fix. It’s 50% science, 50% art. I’ve been there before with the noise suppressor in the speexdsp library. It kinda works, but it’s not great.
Deep Learning and Recurrent Neural Networks
Deep learning is the new version of an old idea: artificial neural networks. Although those have been around since the 60s, what’s new in recent years is that:
- We now know how to make them deeper than two hidden layers
- We know how to make recurrent networks remember patterns long in the past
- We have the computational resources to actually train them
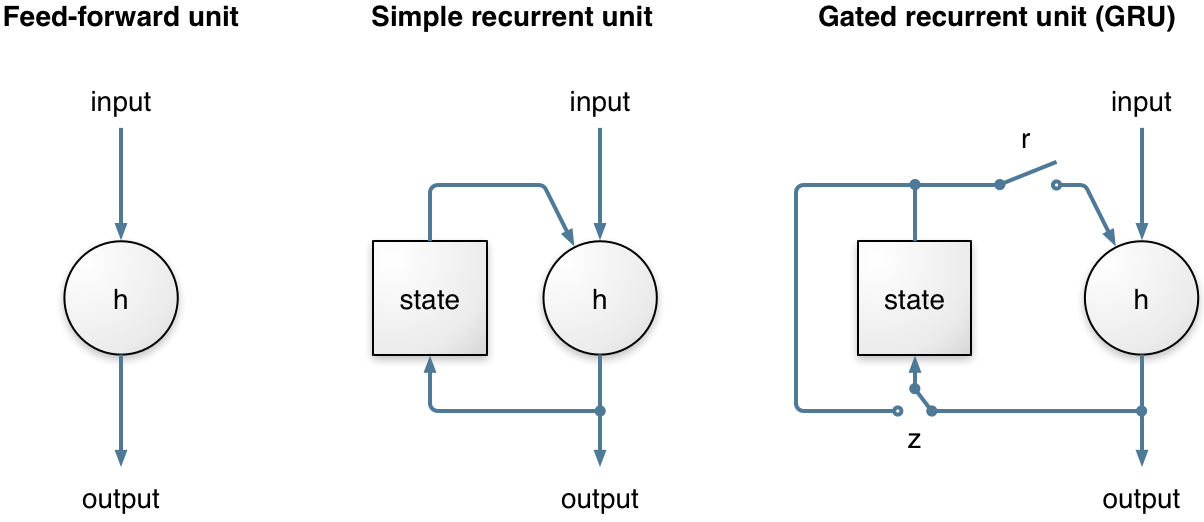
Recurrent neural networks (RNN) are very important here because they make it possible to model time sequences instead of just considering input and output frames independently. This is especially important for noise suppression because we need time to get a good estimate of the noise. For a long time, RNNs were heavily limited in their ability because they could not hold information for a long period of time and because the gradient descent process involved when back-propagating through time was very inefficient (the vanishing gradient problem). Both problems were solved by the invention of gated units, such as the Long Short-Term Memory (LSTM), the Gated Recurrent Unit (GRU), and their many variants.
RNNoise uses the Gated Recurrent Unit (GRU) because it performs slightly better than LSTM on this task and requires fewer resources (both CPU and memory for weights). Compared to simple recurrent units, GRUs have two extra gates. The reset gate controls whether the state (memory) is used in computing the new state, whereas the update gate controls how much the state will change based on the new input. This update gate (when off) makes it possible (and easy) for the GRU to remember information for a long period of time and is the reason GRUs (and LSTMs) perform much better than simple recurrent units.
To read the full original article, including the hybrid approach, click here. For more noise suppression related articles on DSC click here.
DSC Resources
- Services: Hire a Data Scientist | Search DSC | Classifieds | Find a Job
- Contributors: Post a Blog | Ask a Question
- Follow us: @DataScienceCtrl | @AnalyticBridge
Popular Articles
{kind=link}