
Most of the literature we find on machine learning talks about two types of learning techniques – supervised and unsupervised. Supervised learning is where we have a labelled dataset. This means we already have data from which to develop models using algorithms such as Linear Regression, Logistic Regression, and others. With this model, we can make further predictions like given data on housing prices, what will the cost of a house with a given set of features be. Unsupervised learning, on the other hand, doesn’t have a labelled dataset, but still, we do have abundant data. The model we create in this setting just needs to derive a pattern amongst the data available. We do this with algorithms such as K Means Clustering, K Nearest Neighbors, etc. to solve problems like grouping a set of users according to their behaviour in an online shopping portal. But what if we don’t have so much of data? What if we are dealing with a dynamic environment and the model needs to gather data and learn in real time? Enters reinforcement learning. In this article, we look at the basics of what reinforcement learning is, how it works and some of its practical applications.
Reinforcement Learning through Super Mario
We all have experienced reinforcement learning, quite possibly very early in our lives. We just didn’t know it by its name. Okay, so we’ve all played Super Mario when we were younger right? Just in case you didn’t or have forgotten, this is how it looked like:
 https://dimensionless.in/wp-content/uploads/2018/09/super-mario-bros-1-1-i20783-300×200.jpg 300w” sizes=”(max-width: 709px) 100vw, 709px” />
https://dimensionless.in/wp-content/uploads/2018/09/super-mario-bros-1-1-i20783-300×200.jpg 300w” sizes=”(max-width: 709px) 100vw, 709px” />
You might not be able to totally recall the first time you ever played Mario, but just like any other game, you might have started with a clean slate, not knowing what to do. You see an environment in which you as Mario, the agent, have been placed that consists of bricks, coins, mystery boxes, pipes, sentient mushrooms called Goomba, and other elements. You begin taking actions in this environment by pressing a few keys before you realized then you can move Mario with the arrow keys to the left and right. Every action you take changes the state of Mario. You moved to the extreme left at the beginning but nothing happened so you started moving right. You tried jumping onto the mystery box after which you got a reward in the form of coins. Now, you learned that every time you see a mystery box, you can jump and earn coins. You continued moving right and then you collided with a Goomba after which you got a negative reward (also called a punishment) in the form of death. You could start all over again, but by now you’ve learned that you must not get too close to the Goomba; you should try something else. In other words, you have been “reinforced”. Next, you try to jump and go over the Goomba using the bricks but then you’d miss a reward from the mystery box. So you need to formulate a new policy, one that’ll give you the maximum benefit – gives you the reward and doesn’t get you killed. So you wait for the perfect moment to go under the bricks and jump over the Goomba. After many attempts, you take one such action that causes Mario to step over the Goomba and it gets killed. And then you have an ‘Aha’ moment; you’ve learned how to kill the threat and now you can also get your reward. You jump and this time, it’s not a coin, it’s a mushroom. You again go over the bricks and eat the mushroom. You get an even bigger reward; Mario’s stronger now. This is the whole idea of reinforcement learning. It is a goal-oriented algorithm, which learns techniques to maximize the chances of attaining the goal over many iterations. Using trial and error, reinforcement learning learns much like how humans do.
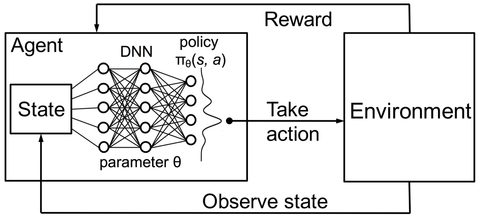
Comparison with other Machine Learning Techniques
There are a few differences in RL as compared to other machine learning techniques. These include:
- There is no supervisor to tell you if you did right or wrong. If you did well, you get a reward, else you would not. If you did terrible, you might even get a negative reward.
- Reinforcement learning adds in another dimension – time. It can be thought of being in between supervised and unsupervised learning. Whereas in supervised learning, we have labelled data and unsupervised learning we don’t, in reinforcement learning, we have time delayed labels, which we call rewards.
- RL has the concept of delayed rewards. So, the reward we just received may not be dependent on the last action we took. It is entirely possible that the reward came because of something we did 20 iterations ago. As you move through Super Mario, you’ll find instances where you hit a mystery box and keep moving forward and the mushroom also moves and finds you. It is the series of actions that started with Mario hitting the mystery box that resulted in him getting stronger after a certain time delay.
- The choice we make now affects the set of choices we have in the future. If we choose a different set of actions, we will be in a completely different state and the inputs to that state and where we can go from there differs. If Mario hit the mystery box but chose not to move forward when the mushroom began to move, he’ll miss the mushroom and he won’t get stronger. The agent is now in a different state than he would have been had he moved forward.
Doesn’t RL feel like life in general?
AlphaGo

Reinforcement learning broke into the scene in March 2016 when DeepMind’s AlphaGo, trained using RL,defeated 18-time world champion Go player Lee Sedol 4-1. It turns out the game of Go was really hard to master for the machine, more so than games like Chess simply because there are just too many possible moves and too many numbers of states the game can be in. But how did AlphaGo beat the world champion?
Just like Mario, AlphaGo learned through trial and error, over many iterations. AlphaGo doesn’t know the best strategy, but it knows whether it won or lost. AlphaGo uses a tree search to check every possible move it can make and see which is better. On a 19×19 Go board, there are 361 possible moves. For each of these 361 moves, there are 359 possible second moves and so on. In all, there are about 4.67×10^385 possible moves; that’s way too much. Even with its advanced hardware, AlphaGo cannot try every single move there is. So, it uses another kind of tree search called the Monte Carlo Tree Search. In this search, only those moves that are most promising are tried out. Each time AlphaGo finishes a game, it updates the record of how many games each move won. After multiple iterations, AlphaGo has a rough idea of which moves maximizes its chance of winning.
AlphaGo first trained itself by imitating historic games played between real players. After this, it started playing against itself and after many iterations, it learned the best moves to win a Go match. Before playing against Lee Sedol, AlphaGo played against and defeated professional Go player Fan Hui 5-0 in 2015. At that moment, people didn’t consider it a big deal as AlphaGo hadn’t reached world champion level. But what they didn’t realize was AlphaGo was learning from humans while beating them. So by the time AlphaGo played against Lee Sedol, it had surpassed world champion level. AlphaGo played 60 online matches against top players and world champions and it won all 60. AlphaGo retired in 2017 while DeepMind continues AI research in other areas.
Applications
It’s all fun and games, but where can RL be actually useful? What are some of the real world application? We’ll see some of these below:
- Robotics and Manufacturing
One of the largest field of research and now beginning to show real promise is the field of Robotics. Teaching a robot to act similar to humans has been a major research area and also part of several sci-fi movies. With reinforcement learning, robots can learn similar to how humans do. Using this, industrial automation has been simplified. An example is Tesla’s factory that consists of more than 160 robots that do a large part of the work on cars to reduce the risk of defects.
- Inventory Management
RL can be used to reduce transit time for stocking and retrieving products in the warehouse for optimizing space utilization and warehouse operations.
- Power Systems And Energy Consumption
RL and optimization techniques can be utilized to assess the security of electric power systems and to enhance Microgrid performance. Adaptive learning methods are employed to develop control and protection schemes, which can effectively help to reduce transmission losses and CO2 emissions. Also, Google has used DeepMind’s RL technologies to significantly reduce the energy consumption in its own data centers.
- Text, Speech and Dialog Systems
AI researches at SalesForce used deep RL for automatically generating summaries from text based on content abstracted from some original text document. This demonstrated an approach for text mining solution for companies to unlock unstructured text. RL is also being used to allow dialog systems (chatbots) to learn from user interactions and help them improve over time.
- Finance
Pit.AI used RL for evaluating trading strategies. RL has immense applications in the stock market. Q-Learning algorithm can be used by anyone to potentially gain income without worrying about market price or risks involved. The algorithm is smart enough to take all these under considerations while making a trade.
- Data Science and Machine Learning
A lot of machine learning libraries have been made available in recent times to help data scientists, but choosing a proper model or architecture can still be challenging. Several research groups have proposed using RL to simplify the process of designing neural network architectures. AutoML from Google uses RL to produce state-of-the-art machine-generated neural network architectures for language modelling and computer vision.
Orginal Article Published on Dimensionless.in
{kind=link}