
Summary: Advances in very low cost compute and Model Based Reinforcement Learning make this modeling technique that much closer to adoption in the practical world.
 We keep asking if this is the year for reinforcement learning (RL) to finally make good on its many promises. Like flying cars and jet packs the answer always seems to be at least a couple of years away.
We keep asking if this is the year for reinforcement learning (RL) to finally make good on its many promises. Like flying cars and jet packs the answer always seems to be at least a couple of years away.
If your history with data science goes back to late-aughts you may remember a time when there were only two basic types of models, supervised and unsupervised. Then, quite overnight, reinforcement learning was added as a third leg to this new stool.
For a technique that had only just become technologically feasible the future looked bright. It’s foundations in trial-and-error search for an optimal reward based on its evolving policy (RL speak for model) looked a lot like human learning. Some thought and still do that the evolution of RL is the most likely path to AGI (artificial general intelligence).
Fast forward a decade and a half and RL is still a child full of promise. It’s reached some limited renown in game play (AlphaGo) and in self-driving vehicles and autonomous flying vehicles. Those have certainly grabbed our attention.
But the fact remains that RL has needed gobs of data and equally large gobs of compute limiting its utility to projects where that was both physically and financially feasible. Recently however there are at least two areas in which RL has made significant leaps making that jet pack era a little closer.
Compute Efficiency
One of the unfortunate realities of requiring huge amounts of compute to make RL work is cost. Yes cloud compute costs keep coming down. Yes, new mega-AI-chips like Cerebras Wafer Scale Engine can replace racks of computers with a single AI-optimized chip. Neither of these solutions is cheap and the result has been to foreclose many research paths in RL to universities and lesser funded labs simply due to cost.
In a paper just presented at the ICML conference a joint team from the University of Southern California and Intel Labs demonstrated using a single machine with a 36 core CPU and just one GPU to effectively train an RL on Atari videogames at 140,000 frames per second. That level of performance on a machine not much different from our home computers is orders of magnitude faster than previous attempts and puts RL research well within the practical and financial means of a host of new investigators.
Model-Based Reinforcement Learning
The other major evolution is Model-Based RL. Just as with faster, cheaper compute, the goal is data efficiency and by extension much faster training times. This isn’t brand new but has been coming on strong for about the last two years.
Think of any RL problems as solved in a sequential series of steps, almost always time steps. This is also called the Markov Decision Process. Whether this is a game of checkers, Go, a robotics operation, or the many decisions needed to safely navigate an autonomous vehicle they all follow this time-step-wise process.
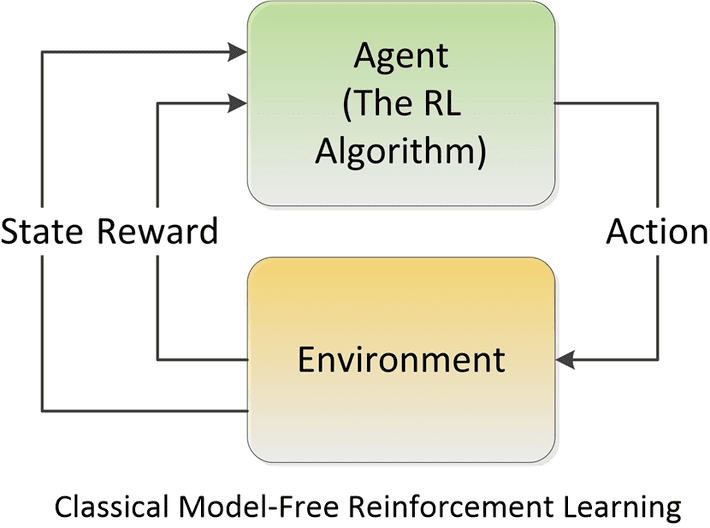 The original Model Free RL exemplified by Q-Learning and Policy Optimization techniques retains its original trial-and-error structure. At each time step RL evaluates both the ‘state’ and the ‘action’ to move forward to the next state and action pair. In Q-Learning for example The Q value predicts the sum of discounted rewards (total return) based on its initially random exploration of each sequential state/action pair.
The original Model Free RL exemplified by Q-Learning and Policy Optimization techniques retains its original trial-and-error structure. At each time step RL evaluates both the ‘state’ and the ‘action’ to move forward to the next state and action pair. In Q-Learning for example The Q value predicts the sum of discounted rewards (total return) based on its initially random exploration of each sequential state/action pair.
What can be confusing is that a deep neural net can be used to learn and generalize the Q value from previous iterations guiding future attempts along the SGD path leading to optimum reward. The fact that a DNN has been used does not however make this Model-Based. Partially to clarify this language ambiguity, in RL-speak what we would call a ‘model’ (the DNN) is called a ‘function approximator’.
By contrast Model-Based RL starts with the logical question, if we knew that the possible state/action responses were constrained by some sort of universal model, wouldn’t it be faster and more ‘data efficient’ to try to predict what the next state/reward would be, eliminating a lot of non-productive random exploration. Well yes. And that is exactly what differentiates Model-Based from Model-Free, that at each step a separate learned or coded model is consulted to guide a more limited number of potentially productive moves.
A number of different architectures are available, all consulting a separate model at each step. 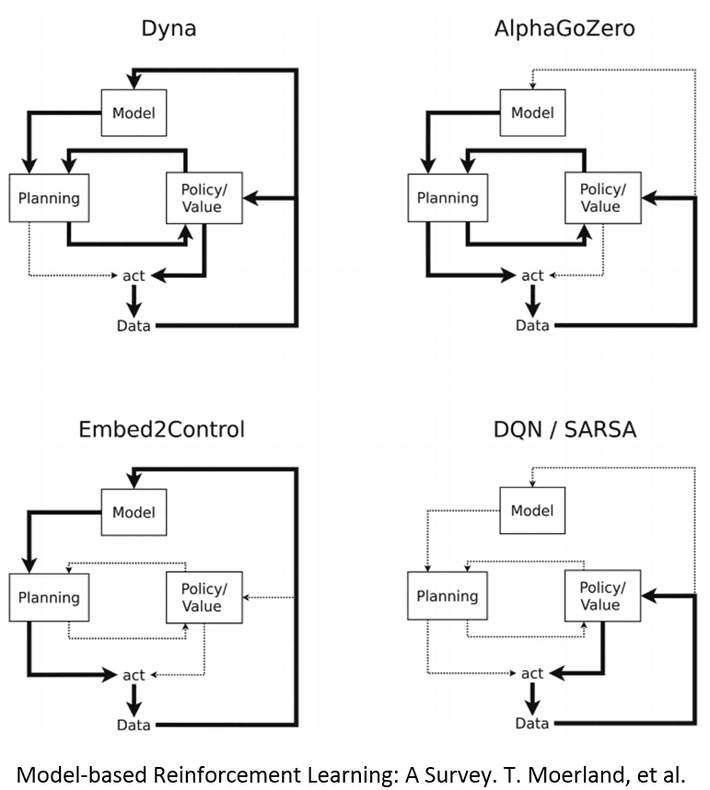
Time for Some Examples
The game of checkers can be reduced to a few dozen hard coded lines of rules that limit the moves that can be made. On a more complex level, essentially all games that have a deterministic outcome (someone wins) can be reduced to rules that limit the available choices of an RL even if the ‘rules’ are derived by a separate supervised model and expressed as a distribution of probabilities rather than a single best choice.
Another simple example is in using Model-Based RL to predict movements that are controlled by the rules of physics. Predicting the next state in a decaying pendulum swing problem, or the much more complex but still physics bound orbits of two or three objects in space (the famous three-body problem). A model simply written in code or discovered using a supervised model like a DNN can inform the Model-Based RL the next most likely high-reward move.
In robotics, especially where the movements of the robot are constrained, like the use of a manipulator arm to select items from a bin and perform an operation an external given or learned model can be used to dramatically shortcut training.
Where Model-Based RL does not shine are in high dimensionality environments with few constraints, or in which the universal model is simply too difficult to discover. Self-driving cars and autonomous aircraft are good examples.
It is at times possible to determine local rules as opposed to global rules and these can be used to speed up learning. The drawback of local rules is determining how they should be limited in the state space and the risk that if applied outside the valid local domain they would result in a clearly wrong choice.
Sequenced events to be predicted can also be too stochastic (noisy and random), non-stationary (change over time to different rules), or can be bound by uncertainty resulting from not being able to see all, or even a sufficient amount of the total state space to be confident that the resulting RL model represents ground truth. All of these are limitations on Model-Based RL and frequently on Model-Free as well.
Future Promise
More data efficient models and much less expensive compute should quickly increase that pace of RL innovation. The one additional feature of Model Based RL still mostly in the works is the potential for transfer learning. In the same way that transfer learning accelerated the adoption of natural language processing literally overnight, the same might soon be true of RL. Research and some examples exist in which some elements of the control model with the in-tact learned RL model can be transferred to similar previously unseen state spaces provided the dynamics are sufficiently similar.
This would take us down the road to rapidly reusable complete or partial RLs and make the potential for adoption in the practical world that much closer.
Other articles by Bill Vorhies.
About the author: Bill is Contributing Editor for Data Science Central. Bill is also President & Chief Data Scientist at Data-Magnum and has practiced as a data scientist since 2001. His articles have been read more than 2.1 million times.
{kind=link}