
This article was written by Anejati.
For the past few days I’ve been working on how to implement recursive neural networks in TensorFlow. Recursive neural networks (which I’ll call TreeNets from now on to avoid confusion with recurrent neural nets) can be used for learning tree-like structures (more generally, directed acyclic graph structures). They are highly useful for parsing natural scenes and language; see the work of Richard Socher (2011) for examples. More recently, in 2014, Ozan İrsoy used a deep variant of TreeNets to obtain some interesting NLP results.
The best way to explain TreeNet architecture is, I think, to compare with other kinds of architectures, for example with RNNs:
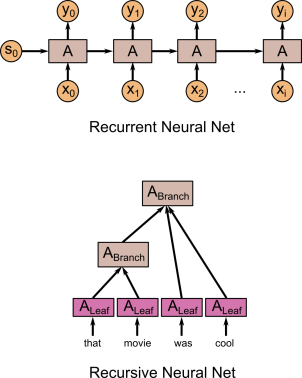
In RNNs, at each time step the network takes as input its previous state s(t-1) and its current input x(t) and produces an output y(t) and a new hidden state s(t). TreeNets, on the other hand, don’t have a simple linear structure like that. With RNNs, you can ‘unroll’ the net and think of it as a large feedforward net with inputs x(0), x(1), …, x(T), initial state s(0), and outputs y(0),y(1),…,y(T), with T varying depending on the input data stream, and the weights in each of the cells tied with each other. You can also think of TreeNets by unrolling them – the weights in each branch node are tied with each other, and the weights in each leaf node are tied with each other. The TreeNet illustrated above has different numbers of inputs in the branch nodes. Usually, we just restrict the TreeNet to be a binary tree – each node either has one or two input nodes. There may be different types of branch nodes, but branch nodes of the same type have tied weights.
The advantage of TreeNets is that they can be very powerful in learning hierarchical, tree-like structure. The disadvantages are, firstly, that the tree structure of every input sample must be known at training time.
To read the full original article click here. For more TensorFlow related articles on DSC click here.
DSC Resources
- Services: Hire a Data Scientist | Search DSC | Classifieds | Find a Job
- Contributors: Post a Blog | Ask a Question
- Follow us: @DataScienceCtrl | @AnalyticBridge
Popular Articles