
Summary: Bias in modeling has long been a public concern that is now amplified and focused on the disparate treatment models may cause for African Americans. Defining and correcting the bias presents difficult issues for data scientists that need to be carefully thought through before reaching conclusions.
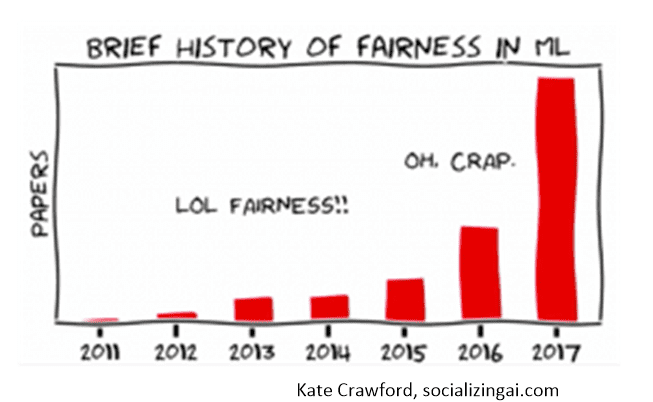 The hue and cry over potential bias in modeling is not new news. We first wrote about it in 2018 when there was broad based concern over individuals being impacted unfairly by the results of our models. The academic field of ethical inquiry into AI/ML has existed since at least 2008. What has changed this time around is the specific focus on its potential impact on a specific race, African Americans.
The hue and cry over potential bias in modeling is not new news. We first wrote about it in 2018 when there was broad based concern over individuals being impacted unfairly by the results of our models. The academic field of ethical inquiry into AI/ML has existed since at least 2008. What has changed this time around is the specific focus on its potential impact on a specific race, African Americans.
It looks like many are doing the ready-fire-aim routine of rushing to conclusions before the reasons are fully understood, and most importantly giving us data scientists a chance to make repairs if in fact they’re required.
Note that I am only talking about the realm of data science and the impact of models. Choke holds, excessive police use of force, or other clearly objectionable behavior by members of the public toward any racial minority should be addressed directly outside of this conversation about data science.
The models most in the news are facial recognition and predictive policing. Yes, police recently falsely arrested an African American man based on facial recognition and held him for 30 hours before realizing they had they wrong person. From a data science perspective this is a false positive problem and probably also a training set problem. Did anyone educate the police users?
The city of Santa Cruz, California recently banned predictive policing. Yes predictive policing wants to allocate resources to where crime is most likely to occur based on historical data.
I am not advocating for or against either of these actions. I would like to see a little more balanced conversation including the data science community about how to make things better.
On the topic of balance in that conversation, what is particularly concerning is that our own professional organizations and researchers are hopping on this bandwagon and attempting to shut down lines of research that they regard as unethical.
Major AI conferences are the true gatekeepers for publishing research. As reported by Quartz, the Annual Conference on Neural Information Processing Systems just announced they will now require a “broader impact statement” about how the presented research might impact society. The Conference on Empirical Methods in Natural Language Processing will begin rejecting papers on ethical grounds.
This is that classical Orwellian conundrum of who is watching the watchers. I leave open for your comments about whether it is ever desirable for a society to preemptively censor lines of academic inquiry before the results can be evaluated.
Back to the Topic of Bias
As we described in our original article there are actually many different types of bias. Microsoft identifies five types: association bias, automation bias, interaction bias, confirmation bias, and dataset bias. Others use different taxonomies.
There’s even an entire conference dedicated to the topic: the Conference on Fairness, Accountability, and Transparency (which recently changed its acronym from FAT* to FAccT – thank goodness) now in its seventh year.
However, we shouldn’t mix up socially harmful bias that can have a negative impact on the lives of a specific minority (who gets arrested, gets bail, a loan, insurance, a job, or a house) for types of bias based on our self-selection, like what we choose to read or who we elect to friend.
When we looked at this last time we concluded that regulated industries like insurance and lending which are precluded from looking at variables that specifically or by inference (e.g. neighborhood) indicate race are actually doing a pretty good job at removing racial bias. It’s in their interest to give a loan or insurance to every qualified customer and the restrictions we’ve put on their modeling seems to have done this pretty well.
We Need to Watch Out for Unregulated Industries – The Most Important of Which are Public Agencies
It’s no surprise that the public focus has been brought to bear on purported racially biased models by their use in public agencies – in this case police. The high stakes outcomes for racial minorities are particularly severe in the public sector.
Consider these examples from our previous research called out by the AI Now Institute which don’t show biased models but simply wrong problem definition assumptions. Nonetheless they have or had racial impact.
Teacher Evaluation: This is a controversial model litigated in court in NY that rates teachers based on how much their students have progressed (student growth percent). Long story short, a teacher on Long Island regularly rated ‘highly effective’ was suddenly demoted to ‘ineffective’ based on the improvement rate of her cohort of students but outside of her control. It’s a little complicated but it smacks of bad modeling and bad assumptions, not bias in the model.
Student School Matching Algorithms: Good schools have become a scarce resource sought after by parents. The nonprofit IIPSC created an allocation model used to assign students to schools in New York, Boston, Denver, and New Orleans. The core is an algorithm that generates one best school offer for every student.
The model combines data from three sources: The schools families actually want their children to attend, listed in order of preference; the number of available seats in each grade at every school in the system; and the set of rules that governs admission to each school.
From the write-up this sounds more like an expert system than a predictive model. Further, evidence is that it does not improve the lot of the most disadvantaged students. At best the system fails transparency. At worst the underlying model may be completely flawed.
It also illustrates a risk unique to the public sector. The system is widely praised by school administrators since it dramatically decreased the work created by overlapping deadlines, multiple applications, and some admissions game playing. So it appears to have benefited the agency but not necessarily the students.
COMPAS Recidivism Prediction: There is one example of bias we can all probably agree on from the public sector and that’s COMPAS, a predictive model widely used in the courts to predict who will reoffend. Judges across the United States use COMPAS to guide their decisions about sentencing and bail. A well-known study showed that the system was biased against blacks but not in the way you might expect.
COMPAS was found to correctly predict recidivism for black and white defendants at roughly the same rate. However the false positive rate for blacks was almost twice as high for blacks as for whites. That is, when COMPAS was wrong (predicted to reoffend but did not) it did so twice as often for blacks. Interestingly it made a symmetrical false negative prediction for whites (predicted not to reoffend but did).
Healthcare: And while we might not immediately think of healthcare as public sector, among African Americans it is most definitely a resource allocated by the public trust and not the private sector version that many others experience. There are any number of studies that show that the medical models used to define optimum treatment are biased against African Americans. And when different models prescribing different treatments for this minority were recommended they were frequently dismissed as “self-proclaimed racial identity is socially constructed and may differ from one’s biological race…” as a reason for not supporting the cost of this treatment.
Correcting Sources of Error
What causes models to be wrong, but with a high degree of confidence for some subsets of the population? In the past we always looked to insufficient data as the source.
 If there were enough data that equally represented outcomes for each social characteristic we want to protect (typically race, gender, sex, age, and religion in regulated industries) then modeling could always be fair.
If there were enough data that equally represented outcomes for each social characteristic we want to protect (typically race, gender, sex, age, and religion in regulated industries) then modeling could always be fair.
Sounds simple but it’s actually more nuanced than that. It requires that you first define exactly what type of fairness you want. Is it by representation? Should each protected group be represented in equal numbers (equal parity) or proportionate to their percentage in the population (proportional parity/disparate impact)?
Or are you more concerned about the impact of the false positives and false negatives that can be minimized but never eliminated in modeling?
This is particularly important if your model impacts a very small percentage of the population (e.g. criminals or people with uncommon diseases). In which case you have to further decide if you want to protect from false positives or false negatives, or at least have parity in these occurrences for each protected group.
Could It Also Be the Model?
In the past we always believed that our modeling tools are completely objective and could never by themselves be the source of bias. That is still true. But it could be the way we’ve shortened the modeling cycle and come to rely on deep neural nets or equally opaque ensemble trees.
What I’m alluding to here is that early in the history of modeling the first step was pretty much always to cluster and test whether different models might not better predict the outcomes for different clusters. DNNs, particularly multi-class classifiers may have distracted us from this common practice. Perhaps, as with the medical modeling, more accurate outcomes could be predicted for clusters that might well be defined somewhat, if not exclusively, along lines of ethnicity.
This may or may not be an answer. That is for experimentation to reveal. However, there is a potential problem here that we should surface.
On issues that rise to societal importance and rely on the perception of equal treatment and fairness are we prepared to defend what appears to be a double standard?
By that I mean, suppose that there were different models used in lieu of the COMPAS model in sentencing for African Americans and hypothetically everyone else. Or there might be several different models based on mathematically derived but likely along ethnic or at least socio-economic lines.
The variables and their weights in each model would be mathematically derived delivering the most accurate outcomes based on the training data. BUT, BUT, BUT they might in fact be different variables with different weights from group to group.
I leave this as an open question you might want to comment on. As a data scientist and as a citizen could you defend using different criteria for different groups that result in more accurate outcomes? Or is this really a classical double standard?
Other articles by Bill Vorhies.
About the author: Bill is Contributing Editor for Data Science Central. Bill is also President & Chief Data Scientist at Data-Magnum and has practiced as a data scientist since 2001. His articles have been read more than 2.1 million times.
{kind=link}