

In my last post, I have compared R to Julia, showing how Julia brings a refreshening programming mindset to the Data Science community. The main takeaway is that with Julia, you no longer need to vectorize to improve performance. In fact, good use of loops might deliver the best performance.
In this post, I am adding Python to the mix. The language of choice of Data Scientists has a word to say. We will solve a very simple problem where built-in implementations are available and where programming the algorithm from scratch is straightforward. The goal is to understand our options when we need to write efficient code.
Experiments
Let us consider the problem of membership testing on an unsorted vector of integers:
julia> 10 ∈ [71,38,10,65,38]
true
julia> 20 ∈ [71,38,10,65,38]
false
I implemented the linear search algorithm in R, Python and Julia, and compared CPU times against a C implementation (1.000 searches over an array with 1.000.000 unique integers). Several flavours of implementations were tested:
- Built-in functions/operators (in, findfirst);
- Vectorized (vec);
- Map-reduce (mapr);
- Loops (for, foreach).
Results
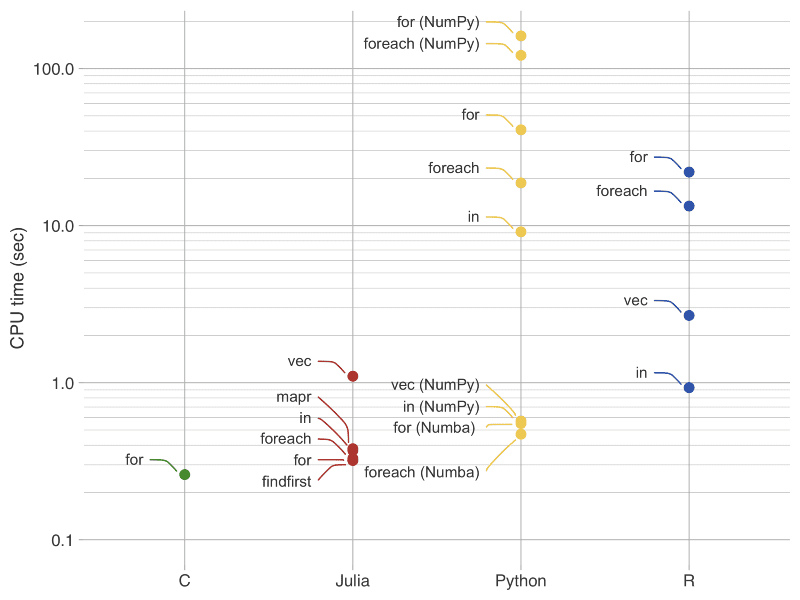
Looking to results side by side for this simple problem, we observe that:
- Julia’s performance is close to C almost independently on the implementation;
- The exception in Julia is when writing R-like vectorized code, with performance degrading about 3x;
- When adding JIT compilation (Numba) to Python, loop-based implementations got close to Julia’s performance; still Numba imposes constraints on your Python code, making this option a compromise;
- In Python, pick well between native lists and NumPy arrays and when to use Numba: for the less experienced it is not obvious which is the best data structure (performance-wise), and there is no clear winner (especially if you include the use case of adding elements dynamically, not covered here);
- R is not the fastest, but you get a consistent behavior compared to Python: the slowest implementation in R is ~24x slower than the fastest, while in Python is ~343x (in Julia is ~3x);
- Native R always performed better than native Python;
- Whenever you cannot avoid looping in Python or R, element-based looping is more efficient than index-based looping.
A comprehensive version of this article was originally published here (open access).
{kind=link}