

Hey GEEKS! Here’s my new blog on Pandas library, an in-depth tool for Data science learners.
It’s never too difficult to transform your dataset into a valuable piece for your project. It requires deep research and study about knowing what is your interesting part of data.
Python enables you to get your hands dirty with data in many ways. One of them,which is my favorite is its PANDAS library. As much as its name excites me, also its flexible nature of accepting all types of data like JSON,CSV, XLSX, etc, and numerous fancy features like slice/label indexing, time series functions facilitate me in data analysis.
Here I’ve got some really helpful commands that would help you analyze your data better.
first, we need to import the dataset
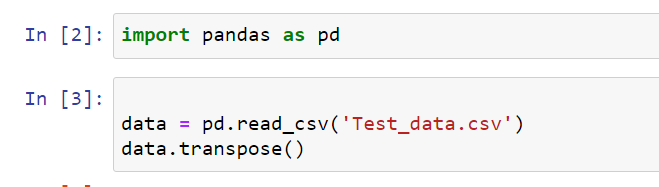
The EDA gets tougher in handling large datasets. Here are some quick DS hacks to help you out!
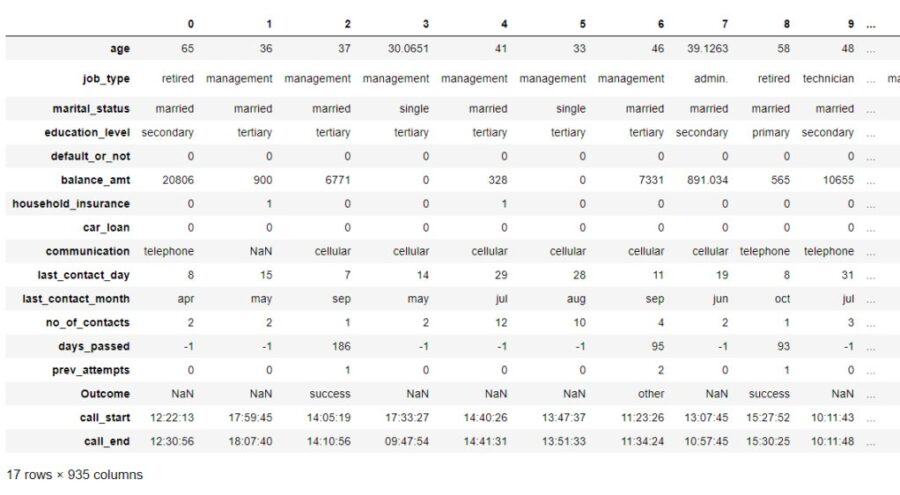
select_dtypes()
This function enables you to select columns in a data frame with their data types. By this, you can make many useful subsets of data based upon their column dtypes.
Sounds interesting? Let me show you with code
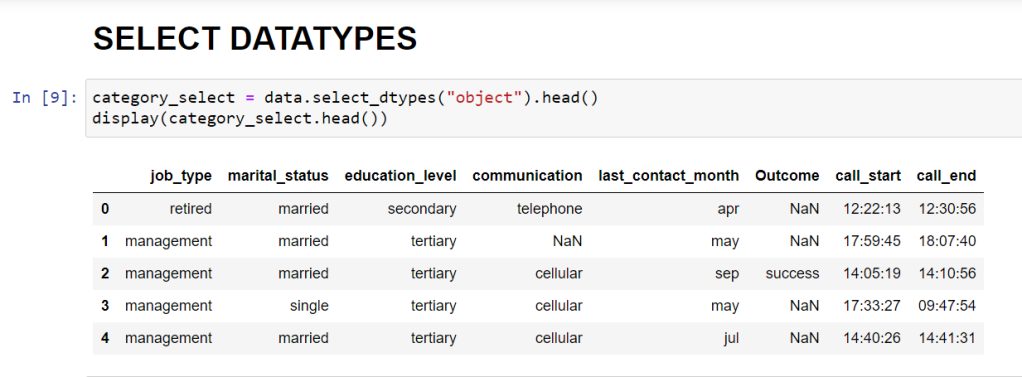
melt()
The melt() function is used to transform a data frame from wide to a long format. It can take multiple columns as identifiers of the table and allows you to see your data with two non-identifier columns (variable and value) to observe the measured variables.
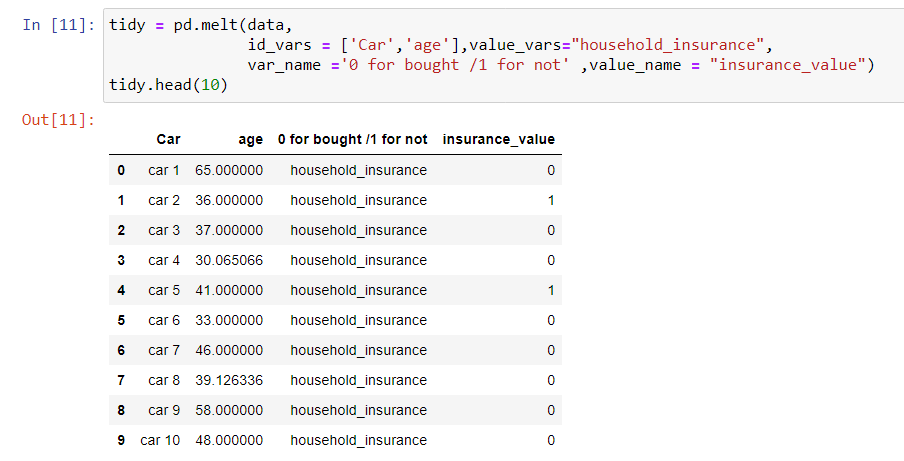
Identifiers(car & age) tells about non-identifiers (either the insurance is taken or not)
columns.tolist()
Another interesting practice most common in data munging and analysis is to convert columns obj datatype to a list. Since its easier to make modifications to a list as compared to an object, this method helps us to extract only those columns which have a great impact on our target column or make changes in the order of the columns in a data frame.
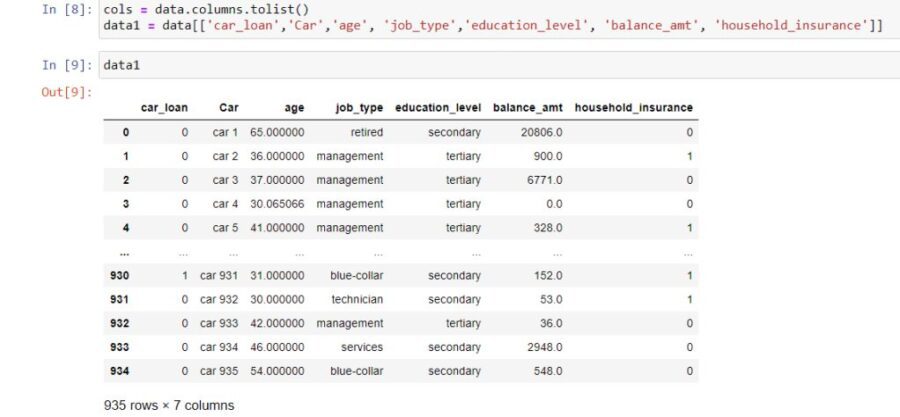
car_loan column becomes the 1st column now
str.split()
With the help of Pandas, we can split a single string into multiple columns with str.split() method. This means it will return a data frame with all separated strings in different columns. You can easily do this by specifying the separator value in the function. When a separator isn’t written, whitespace is taken as an input.
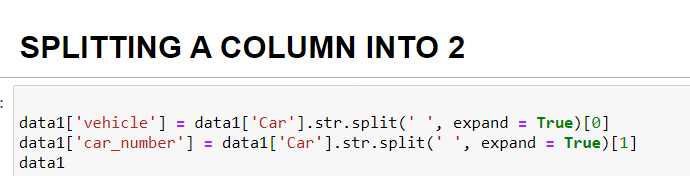
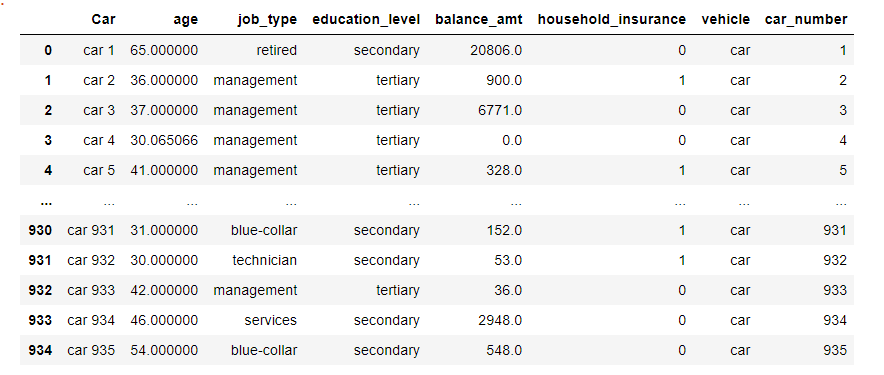
Column Car splits into two columns vehicle and car_number
to_datetime()
Handling datetime features in data science is also very important as it requires correct formatting and values to train the model.
This function takes datetime argument as an input parameter and converts it into a python datetime object.
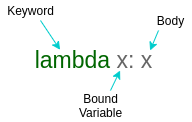
Lambda Functions:
They are the nameless functions(anonymous) that can take multiple arguments(bound variable) but returns only one expression(the body part). These functions execute faster as compared to normal functions.
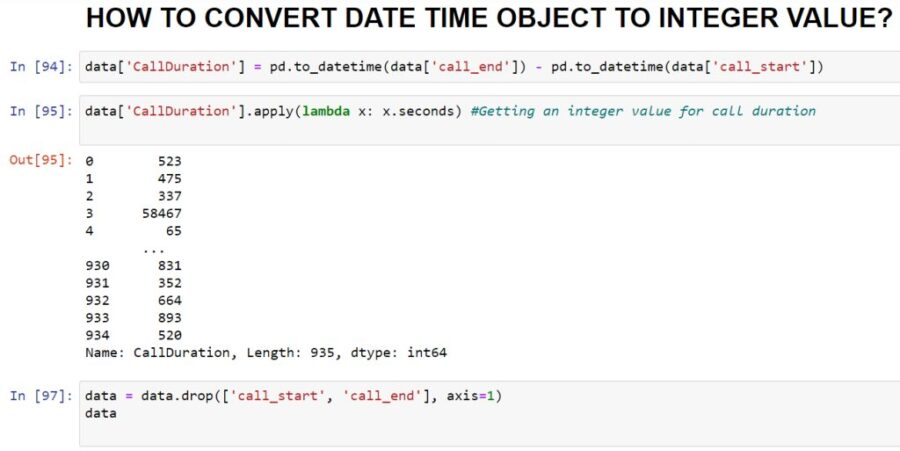
We apply a lambda function with the help of apply() function.
In the above example, we have merged call_start and call_end columns into a single column i.e. call_duration, and then called lambda function to convert the datetime object value into integer with the help of x.seconds() function.
Notebook Link : Data-science/DSHacks.ipynb at main · ToobaAhmedAlvi/Data-science (g…
I’ll come with some more interesting hacks. Until then stay connected. 🙂
{kind=link}