
Summary: Picking an analytic platform when first starting out in data science almost always means working with what we’re most comfortable. But as organizations grow larger there is a need for standardization and for selecting one, or a few analytic tools.
 Picking an analytic platform when first starting out in data science almost always means working with what we’re most comfortable. That in turn almost always means whatever we used in college (or your certificate course) be it R, Python, SAS, SPSS or whatever our instructors directed us to use. After all, we want to be both comfortable and efficient and all other things being equal, that means sticking with what we know.
Picking an analytic platform when first starting out in data science almost always means working with what we’re most comfortable. That in turn almost always means whatever we used in college (or your certificate course) be it R, Python, SAS, SPSS or whatever our instructors directed us to use. After all, we want to be both comfortable and efficient and all other things being equal, that means sticking with what we know.
Before R and Python became the go-to’s on many campuses, SAS and SPSS understood this lesson well and had very aggressive discounts for students and instructors (read that as nearly free). Now that there’s open source that’s been diluted somewhat but the majors keep plugging away with that strategy and it still works.
If there were a good reason to switch we’d consider it. But the reason would have to be pretty compelling, meaning features like easier or broader:
- Data blending, access, and ETL.
- Automated data prep: cleansing, binning, smoothing, auto charting.
- Geospatial capability.
- Feature generation and dimensionality reduction.
- Advanced modeling techniques including optimization, simulation, and probably recommenders.
- Automated champion model generation and selection.
- Enhanced delivery, integration, and model deployment.
Well the list goes on. Not every platform has the best of all of these, and not every practitioner can reliably call up every R and Python code to accomplish these without some help.
Once in a while a package will gain wide enough press that we’ll take notice and perhaps add that to our repetoire. But in my experience data scientists (and this is true in other industries as well) are very inwardly focused and do a pretty poor job of keeping up with the cutting edge changes in our profession. (hint, they should be doing more reading on DataScienceCentral.com).
This is simply an observation, not a criticism. We’re all focused on doing our day-to-day tasks with as much excellence as we can muster and that doesn’t leave much time left over for thinking about changing the way we’re doing things. That goes a long way to explaining why there are such strong feelings about not changing. “I’ve always used R, Python, SAS (insert package name here) and it works fine. Don’t make me change.” This observation also reveals the obvious. Change isn’t free. There’s a learning curve with any new package or technique that we’d just as soon avoid unless there’s a really compelling reason.
But Now We Have to Work In Teams
If we were all our own boss then we’d just keep doing what’s been working. This is true even if the outcome isn’t as accurate or as efficient as others are achieving because very few practitioners have an objective frame of reference for determining that. But the good news is that an increasing number of organizations are adopting advanced analytics and increasingly that means we aren’t working alone but in groups.
If you are fortunate enough to rise to the level of running one of these anaytic groups then it won’t take long to come to the realization that everyone can’t continue to go their own way. Also, that the efficiency and accuracy of the entire group does matter.
Up to very recently I’ve personally known some companies with data science staffs numbering in the several dozens that actually did let everyone go there own way. Now they too have finally had to come to grips with standardization.
Clearly there are two aspects to standardizing on an analytics platform. The more difficult task is creating organizational change and actually changing behavior. Sometimes this is top down, sometimes bottoms up. Certainly your data scientists should have a say, but now this has to be balanced against corporate financial considerations, the case for greater efficiency in teamwork, the learning curve, and even possible defections. We’ll leave that for another time.
In terms of figuring out which platform (or group of platforms) to pick the place everyone typically starts is with Gartner, Forrester, and the other research services. Here’s what they say most recently, based on the Gartner February 2016 Magic Quadrant for Advanced Analytic Platforms.
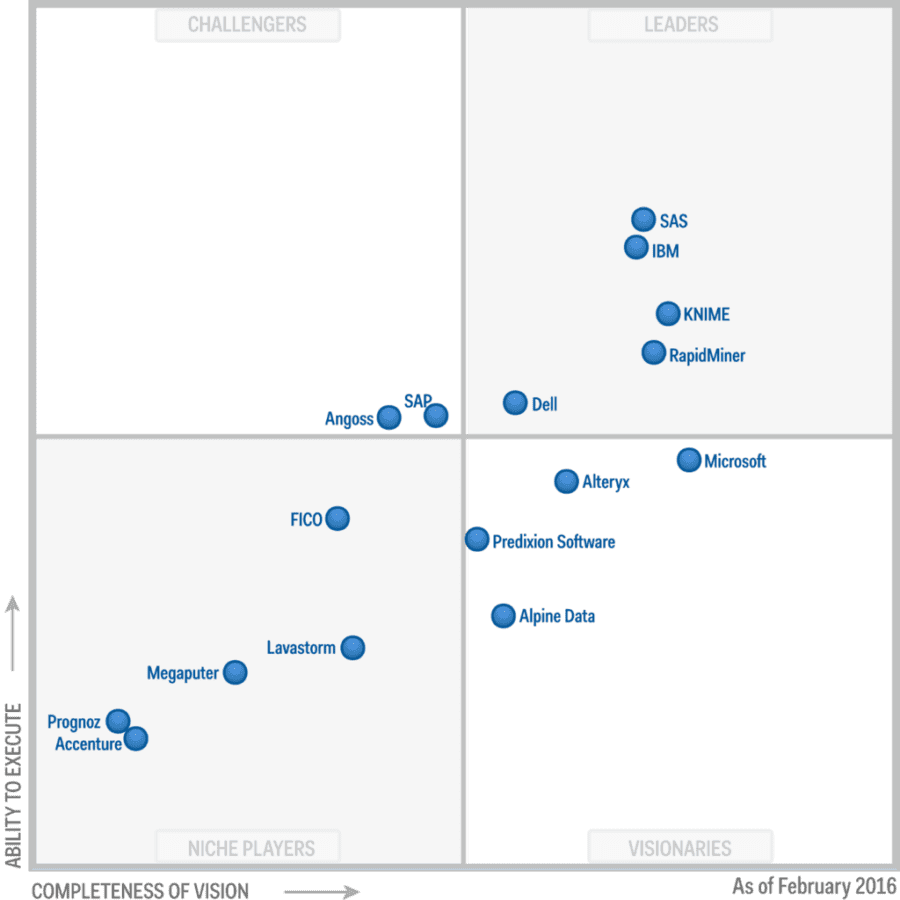
But this year Gartner has taken a slightly different tack and says your choice depends on several additional criteria. Here in part is their general guidance with some additional observations of my own.
- “Choose the advanced analytics platform(s) best suited to the size, maturity and personal style of their analytics teams.” This is a major point of depature in our thinking. Gartner believes that large teams, medium size line-of-business groups, and sole citizen data scientists have distincly different needs. More on this a little later.
- “Avoid trying to consolidate too much into one tool and instead realize that a whole portfolio of tools will be required that supplement the core advanced analytics platform (often including one of a wide range of open-source options).” I agree, it may take more than one tool, but allowing too many tools leads back toward the anarchy of everyone doing their own thing.
- “Avoid long-term commitments in this market segment, as the level of innovation is extremely high.” I’m not so sure about this one. The long term commitment is not financial since all platforms offer subscription based pricing that tends to give discounts for longevity. However, an investment in the training necessary to get everyone on one platform will pay off in the long run. The pain in switching is in the skills and familiarity with the platform.
- “Consider more affordable and flexible stacks from open-source vendors, although these tools will typically require deeper coding skills.” Before becoming a completely open source shop (R, Python, Scalia) I would look closely at the overhead on efficiency and accuracy required to perform your data science purely in scripting languages. For my money this works directly against the goals of standardization, accuracy, repeatability, and efficiency. The cost per data scientist of providing a standard proprietary platform is a small premium for these benefits.
It Depends on the Size of Your Data Science Organization
One of the most interesting thoughts here is that the tools needed to support large centralized data science groups, versus small dispersed line-of-business support DS groups, versus widely scattered citizen data scientists are different. I think there’s some truth to that but having as much to do with the maturity of the individual practitioners as the organizational structure of the group.
This side-by-side ranking is a bit of an eye chart and you can see the original here.
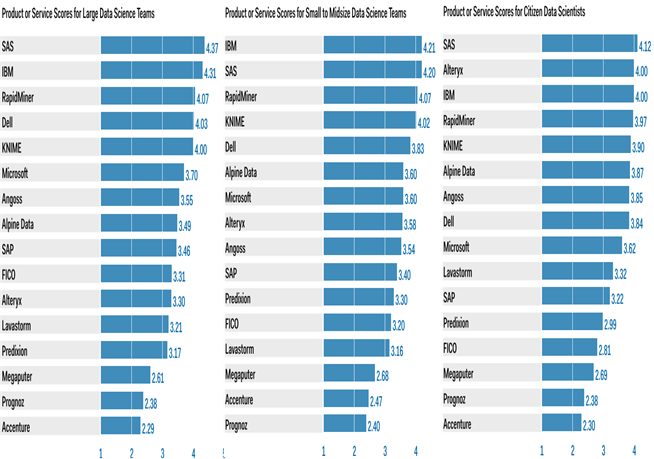
The rankings and scores don’t differ all that much and some of the major differences in criteria are these.
Large Data Science Teams
Typically these are organized into an analytics center of excellence where there is substantial management focus and support. There may be many differenct skill sets and experience levels here and good experience with R or Python that can be leveraged to support a standardized analytic platform.
These groups are likely to be working on a large number of projects and models simultaneously and need support in collaboration, access to data, model management tools, and efficient deployments via code export or APIs.
They also need access to the broadest range of the most sophisticated and cutting edge algorithms and data science tools.
Small to Midsize Data Science Teams
These teams of perhaps three to 10 are frequently deployed in support of a single line of business and in large companies there may be several of these relatively independent data science teams.
They are similar in many ways to the large teams in their needs but tend to get less management visibility and financial support. The emphasis here is still on advanced tools and capabilities but fewer resources that need to be easier to use, more efficient tools, with higher levels of automation.
Since they are likely to get less support from IT, self service features are important in access to data and data blending.
Citizen Data Scientists
These tend to be individual power users with deeper business or software engineering knowledge and novice or moderate data science skills. These individuals may be the vanguard introducing adavanced analytics into a new business area through a POC or simply data-motivated managers where few formal data science resources are available.
There are many organizational challenges that surround citizen data scientists but from a technical standpoint the emphasis is on self service, relatively automated and intuitive modeling platforms that minimize the opportunity for operator error, and visualization and reporting.
Clearly there is less emphasis on collaboration with other DS groups though from an organizational stand point there should be mentoring and the monitoring of quality before models are introduced into a production enviroment.
The Greater Analytic Platform Landscape
Gartner focuses only on the top 16 analytic platform vendors. There are at least 50 analytic platform vendors and probably a bunch I don’t know about. From a market perspective there just isn’t much air left to breathe for the other 34. There are handful I can identify with specialty niches that might be worth considering as add ons particularly in the areas of anomaly detection and the new one-click-to-model fully automated platforms. For the rest of us, standardization within this group of leaders will be a solid choice.
About the author: Bill Vorhies is Editorial Director for Data Science Central and has practiced as a data scientist and commercial predictive modeler since 2001. He can be reached at:
{kind=link}