
Optimized Promotion Placement

The promotions page on any website during an offer period, may it be Thanksgiving, Cyber Monday or even Ester has tons of products scattered across the page. There could be multiple business rules governing the position of the products. Couple of scenarios that we usually come across:
- Products are just scattered across the page with no governing rule at all
- Product position randomly change for every user
- Product sorted by price or alphabetically
- Products are arranged in categories, while categories themselves
- have no underlying order
- further arranged in alphabetical order
- arranged per business focus or target for the period
Majorly the approaches are empirical in nature rather than backed by statistically proven logic. This is a real nightmare for the merchandisers and category owners, since they have to fight a tough battle to get in the top of the stack.
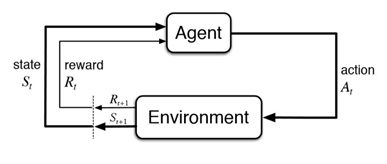
Rather than leaving it to heuristics, Reinforcement learning offers an excellent solution where in, the position can be decided basis some KPI like revenue, hits, units sold etc. Combine this with the additional logic of stock at hand, BANG! We have a strategy in place which is not only statistically proven, but is also optimized to increase the target KPI (which is overall revenue in most of the cases).
Reinforcement learning is many a times used by the media agencies which want to achieve maximum output, while having multiple versions of the same banner ad to choose from. Rather than going the route of A/B testing, all the versions are put in live environment, and in the due course, the best performing version is chosen algorithmically.
The same technique can work with on-promotions products, where the position of a product or a category on deals page can be decided by the outcome from multiple such experiments. In the predefined time frame, the products/categories position can be decided on basis their rank for the KPI. The position need not to be static. After couple of hours the same activity can be repeated and we may have a new order. Couple it with the yard stick of stock position, so that stock outs can be avoided.
There are multiple approaches to implement Reinforcement Learning:
- Multi arm bandit
- Epsilon greedy approach
- Softmax exploration
- Upper confidence bound
Do note that Reinforcement learning can be too much resource taxing and hence adequate (server grade) processing power is a must.
{kind=link}