

In the previous part, we started to outline what ontologies are and how they may be used; now it is time to get into more practical guidelines and tips that would help build an ontology from scratch.
Though there exist a number well-established methodologies for developing an ontology in various environments, including Protege, Ontolinqua and Chimaera, they are all underpinned by the same basic principles resting on the multidimensionality and flexibility of the ontology. This means that while developing an ontology you do not have to think about the final implementation in a language (UML, SysML, OWL etc.) or an environment. A specific language and a specific tool will come later, once you have a model for the ontology designed.
The fundamental principles for creating an ontology may be reduced to the following:
• There is not a correct way to model a domain: the structure of an ontology is application-driven and depends on the possible use and extensions.
• The ontology development is an iterative process : the modeler may like to start with nouns and verbs from the knowledge source to sketch the overall structure and then will go through multiple iterations to refine and correct the structure
• Concepts in the ontology should be close to objects (physical or logical) and relationships in the domain. These are most likely to be nouns (classes, attributes, instances) or verbs (relationships) in sentences that describe your domain.
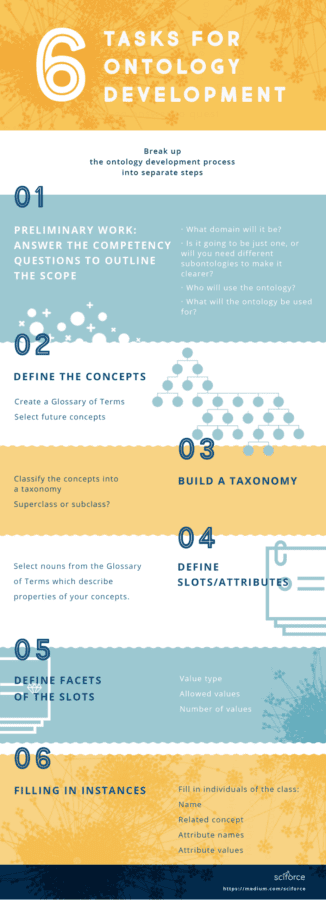
An ontology development usually encompasses several tasks. Different methodologies order them differently, but in general they include:
• preliminary work: outlining the scope of the ontology;
•defining the concepts/classes of the ontology;
• arranging the concepts in a taxonomy;
• defining slots/attributes
• defining facets of the slots/attributes;
• filling in the values for slots for instances;
• defining axioms, rules and restrictions/facets (if there is enough time and knowledge).
Preliminary work: outlining the domain, the scope and the purpose of the ontology

The preparation stage may be the hardest part because a good model requires a clear understanding of the scope and the purpose of the ontology.
For this, you are supposed to find an answer to questions such as:
• What domain will it be?
• Is it going to be just one, or will you need different subontologies to make it clearer?
• Who will use the ontology?
• What will the ontology be used for?
One of the common ways to determine the scope of the ontology is to sketch a list of competency questions that a knowledge base based on the ontology should be able to answer (Gruninger and Fox 1995). The same questions may help to limit the scope: among practitioners, it is called the possible minimal conceptualization. In other words, the ontology should not contain all the possible information about the domain, but the one you need for your application.
Tip: Know your sources
In you are an expert on the domain, you can go ahead with modeling the ontology. More common, you have a partial knowledge of the domain, so you will need more knowledge that can come from:
• Experts: if you are lucky to know them, ask everything you want to know.
• Documents: if you do not have people, you might have literatures, documents, technical information, etc. on the domain. Get a highlighter and start underlying nouns and verbs, which make sense both to you and the domain
- Existing ontologies: your domain might have been modeled before with a different viewpoint or purpose. Look for them, analyze the level of granularity, select them and evaluate them for the possibility of further full or partial reuse.
Defining the concepts of the ontology

You can start with writing down a list of all terms you might like either to make statements about or to explain to a user. Then you may try to decide on what the terms — future concepts — you would like to have in the ontology are? What properties do they have? What would you like to say about these terms?
Initially, it is important to get a comprehensive Glossary of Terms which would include a list and/or graphs of all nouns and verbs you have considered without worrying about overlap between concepts they represent, relations among the terms, or any properties that the concepts may have, or whether the concepts are classes or slots. In practice, that will mean that each term will have at least a name, a synonym, a natural language description, a type, a source (to remember why you put it there), comments. . .
Once you have a comprehensive list of terms, you may try to decide whether a term in the list might be a concept, an attribute or an instance: concepts are nouns standing on their own, attributes look more like nouns describing types of things, and instances tend to be more specific things. Then, verbs will end up as relations between specific concepts. Though the initial list may not cover up all relations and classes, the model will be refined through several iterations.
Arranging the concepts in a taxonomy

At this stage, the concepts are classified into a taxonomy to define superclass-subclass hierarchy, as some nouns from the Glossary of Terms will seem to be related as types (subclasses) of other (superclasses).
There are several possible approaches in developing a class hierarchy (Uschold and Gruninger 1996):
• A top-down development process starts with the definition of the most general concepts in the domain and subsequent specialization of the concepts.
• A bottom-up development process starts with the definition of the most specific classes, the leaves of the hierarchy, with subsequent grouping of these classes into more general concepts.
• A combination development process is a combination of the top-down and bottom-up approaches: We define the more salient concepts first and then generalize and specialize them appropriately.
While developing the taxonomy, it is important to account for different types of taxonomic relations, i.e., how the subclasses are related to the superclasses (Horridge et al, 2001):
• Subclass: a concept C1 is subclass of concept C2, if and only if every instance of C1 is also instance of C2;
• Disjoint decomposition of C: set of subclasses of C that do not have common instances and do not cover C;
• Exhaustive decomposition of C: set of subclasses of C that may have common instances and subclasses and do cover C;
• Partition of C: set of subclasses that do not share common instances but cover C.
One of the hardest decisions to make at this stage of modeling is when to introduce a new class or when to represent a distinction through different property values. It is hard to navigate both an extremely nested hierarchy with too many classes and a very flat hierarchy that has too few classes with too much information encoded in slots. There are several rules of thumb that help decide when to introduce new classes in a hierarchy:
Subclasses of a class may have
• additional properties that the superclass does not have, or
• restrictions different from those of the superclass, or
• participate in different relationships than the superclasses.
Although you should not model all possible things, you have to define the ones you need for your level of detail and scope and be careful to stick to them avoiding inconsistencies, misclassifications and redundancies.
Between concepts, there will be relations that are to be described in detail by giving a name, source concept, target concept, cardinality (how many instances of a concept are related with how many of the others), inverse name (you can read from A to B, but also from B to A. Sometimes, the distinction is important).
Defining slots/attributes — the properties of your concepts

Slots, also called attributes of properties, describe the features of the concepts. Some of the nouns in the Glossary of Terms could be considered as slots, i.e., the terms used to describe others.
Ontologists distinguish between class attributes (terms describing concepts which take their values in the class they are defined, and not inherited in the hierarchy) and instance attributes (terms describing concepts that take their values in the instance, and may be different for each instance).
In general, there are several types of object properties that can become slots in an ontology:
• “intrinsic” properties of the object;
• “extrinsic” properties such as a the object’s name;
• parts, if the object is structured; these can be both physical and abstract “parts”
• relationships to other individuals: these are the relationships between individual members of the class and other.
There is no unique way to define the slots of a concepts, but there are certain tips and general guidelines:
• Try to attach the attribute/slot to the most general class/concept that can have that property.
• Try to define type attributes (integer, string, float, . . .). If a term can have a well-defined type (integer, string, float) it is an attribute, not a concept.
• Try to define a range, value, precision, related classes and other data that might be useful
Most importantly, you should remain flexible and open-minded: some classes might end up being attributes to describe the different classes and/or instances.
Defining the facets of the slots/attributes

Slots can have different facets describing the value type, allowed values, the number of the values (cardinality), and other features of the values the slot can take. The common facets include:
Slot cardinality which defines how many values a slot can have. Some systems distinguish only between single cardinality (allowing at most one value) and multiple cardinality (allowing any number of values);
Slot-value type which specifies what types of values can fill in the slot, such as string, Boolean, float etc..
Filling in the values for slots for instances

An instance is an individual of a class, you can describe in detail relevant instances that may appear by giving them a name, concept to which they are related, attribute names and values.
Defining axioms and functions
Formal axioms are used in ontologies to model sentences that are always true, while functions represent special case of relations. These may help you ontology be more precise and complete.
At the end, your ontology should be precise, consistent, complete and concise. To avoid errors and inconsistencies, it is compulsory to evaluate the concepts and the taxonomies, attributes and relations you may have made by giving the second thought to the questions:
• Whether a new class is needed?
• Is it a class or an attribute?
• Is it a class or an instance?
• Is your ontology free from class cycles (class A has a subclass B, which in turn, is superclass of A)?
• Are all concepts classified as subclasses of other concepts to which they really belong?
• Is your ontology free from classes or instances with the same formal definition?
After this evaluation your model is ready and you can proceed to selecting the environment for creating the ontology.
References:
Bermejo J. (2007). A simplified guide to create an ontology. Technical Report R- 2007–004. Madrid University, Autonomous Systems Laboratory.
Horridge M., Knublauch H., Rector A., Stevens R., Wroe C. (2004) A Practical Guide To Building OWL Ontologies Using The Protégé-OWL Plugin and COODE Tools Edition 1.0, The University Of Manchester Stanford University.
Noy N., McGuinness D., (2001) Ontology Development 101: A Guide to Creating Your First Ontology.
Uschold, M., and Gruninger, M. (1996). Ontologies: principles, methods, and applications. Knowledge Engineering. Review, 11, 2, pp. 93–155.
{kind=link}