
This article was written by Moses Olafenwa.
One of the important fields of Artificial Intelligence is Computer Vision. Computer Vision is the science of computers and software systems that can recognize and understand images and scenes. Computer Vision is also composed of various aspects such as image recognition, object detection, image generation, image super-resolution and more. Object detection is probably the most profound aspect of computer vision due the number practical use cases. In this tutorial, I will briefly introduce the concept of modern object detection, challenges faced by software developers, the solution my team has provided as well as code tutorials to perform high performance object detection.
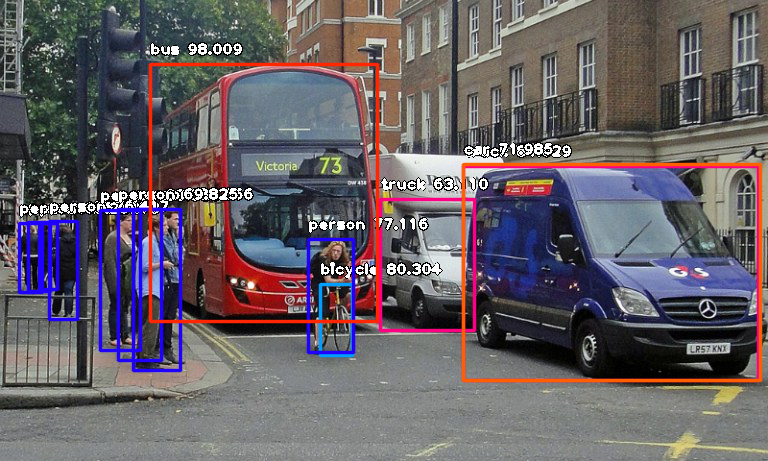
Object detection refers to the capability of computer and software systems to locate objects in an image/scene and identify each object. Object detection has been widely used for face detection, vehicle detection, pedestrian counting, web images, security systems and driverless cars. There are many ways object detection can be used as well in many fields of practice. Like every other computer technology, a wide range of creative and amazing uses of object detection will definitely come from the efforts of computer programmers and software developers.
Getting to use modern object detection methods in applications and systems, as well as building new applications based on these methods is not a straight forward task. Early implementations of object detection involved the use of classical algorithms, like the ones supported in OpenCV, the popular computer vision library. However, these classical algorithms could not achieve enough performance to work under different conditions.
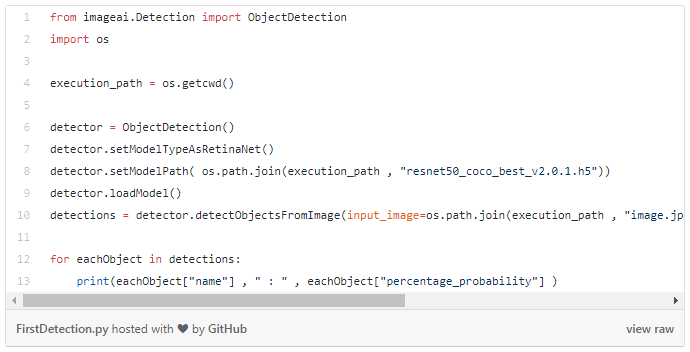
Source for the code: here
The breakthrough and rapid adoption of deep learning in 2012 brought into existence modern and highly accurate object detection algorithms and methods such as R-CNN, Fast-RCNN, Faster-RCNN, RetinaNet and fast yet highly accurate ones like SSD and YOLO. Using these methods and algorithms, based on deep learning which is also based on machine learning require lots of mathematical and deep learning frameworks understanding. There are millions of expert computer programmers and software developers that want to integrate and create new products that uses object detection. But this technology is kept out of their reach due to the extra and complicated path to understanding and making practical use of it.
My team realized this problem months ago, which is why I and John Olafenwa built ImageAI, a python library that lets programmers and software developers easily integrate state-of-the-art computer vision technologies into their existing and new applications, using just few lines of code.
Note
To run the above short code featured in the picture, you need to install the following Pyton libraries, via pip (e.g. “pip install tensorflow”):
- Tensorflow
- iNumpy
- SciPy
- OpenCV
- Pillow
- Matplotlib
- H5py
- Keras
- ImageAI
Upgrade about “pip3 install imageai”: download the RetinaNet model file that will be used for object detection via this link: https://github.com/OlafenwaMoses/ImageAI/releases/download/1.0/resn…
To read the rest of the article, click here.
{kind=link}