
As a data scientist in an organization you frequently find yourself in a couple of situations:
- you have a dataset, you want to extract some useful information
- you have a business problem, you want to find a data-driven solution
The first situation is actually a common one, basically, this means doing all the things you have learnt as part of exploratory data analysis (EDA) in your data science journey. In this article instead, I will explain how to navigate the second kind of situations.
Let’s say you have been long enough in your organization to know its business practices and all the kinds of data it generates. And along the way, you have developed a hypothesis that you want to test. Or, just maybe your manager/CEO/CTO is asking you to help find an answer to a question they were having trouble with. If you are experienced enough you will probably know your next steps, but newbies often struggle to kick off their thinking in the right direction. So here is an algorithmic way to think about the problem through to a solution.
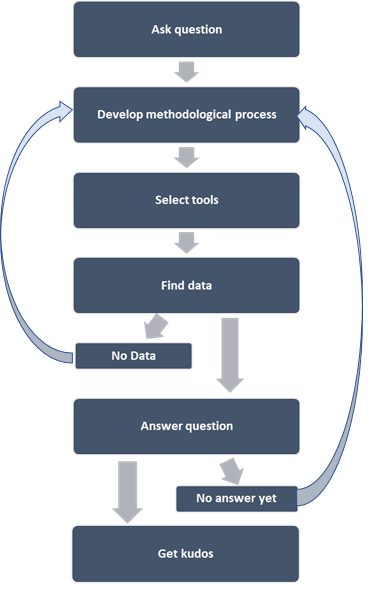
Data science project cycle ( @DataEnthus)
The problem
In step 1, you have a question or problem. If it’s a big one, you could break it down to smaller pieces if needed. For example, if the question is about forecasting sales growth over the next 10 years, you could break it down to pieces such as what’s been the historical sales? How’re the sales currently trending? How’s the demand trending in the market? How are the competitors doing? Etc.
You gather as much information as possible from different sources to understand the problem from different perspectives. You first zoom out for the big picture then zoom in to specific bits of information related to the problem. At this stage, you really are getting to know the issue at hand from many different angles. This part is similar to literature review in academic research projects. You should want to allocate a good portion of your time in framing the problem.
The process
In step 2, no, you are not thinking about what models/tools/visualization techniques to use; not yet. You are thinking about a methodological process that will guide you through answering your question. You lay out a list of datasets, locate where to find them, and maybe make a list of tools that might be useful. Even if you haven’t made final decisions on specifics of data/tools, having an overall process in your mind or written on paper helps a lot, even if it will change later on with additional information. This approach is kind of similar in academic settings where you write your research proposal before actually executing the research; things often change along the way as you study the problem at hand further and go deeper.
The tools
In step 3, now you are thinking about what tools can help answer this question. If it’s a forecasting problem, you would think if a time series based model is any useful? Or is it a linear regression problem instead? Do you need GIS technology? Is there a good package in R or Python?
Once you have explored all available options and decided upon a particular set of tools, you are now ready to go data hunting. Data that you need can be a multi-million rows dataset or may very well be a hundred data points — depending on your problem and the model you choose.
Have you found the required data for the chosen model? If yes, you are good to go fit your model. But if you don’t have all the required inputs, you should stop here and go back to your methodological process in step 2. Maybe there are other tools/methods that don’t require time series data? How about a system dynamic model that requires not many parameters or large datasets?
The answer
You have chunked your big problem into smaller pieces, and answered them individually. In aggregate have you solved the big problem that you started with? If yes, kudos. If not, go back to step 2.
Communication is a big part in problem solving process. Do you need to be able to convince your audience (product manager/colleagues/external audiences) why your solution makes sense? You also need to be transparent about the uncertainties and caveats associated with the proposed solution and as well as the assumptions you made along the way.
The bottom line
In summary, being a scientist means going through a process of exploration/discovery. We are often hung up with what tools/models we know and how to fit them with the data. As we have seen, selecting the right tool is a small part of the problem solving process. It’s always problems first, tools later.
Originally posted here.
{kind=link}