
What is a Cheat Sheet ?
Wikipedia defines cheat sheets as a concise set of notes used for quick reference. Now the word that needs to be emphasized here is ‘quick reference’.
In programming, cheat sheets are OK because no one can remember all the syntax of a programming language. Especially if the programming language constantly evolves (like Python) or if the programmer finds himself/herself transitioning in and out of different programming languages.
A quick reference like a cheat sheet helps the programmer save time and focus on the larger problem.
Data Scientist , What are you in a hurry for ?
Machine learning algorithm learning and implementation are never supposed to be a 100 M dash. Each machine learning implementation is supposed to be mulled over, thought through carefully, and then implemented. Data science solution takes time, it is an exploratory and experimental endeavor.
Following some cheat sheet makes you less experimental and you fail to explore all the options. The ‘Dive-straight into the problem’ attitude might help you win some Kaggle competitions but it won’t take you far in real-life machine learning use cases.
OK, now let’s get to the crux of the matter…
Why ML algorithms cheat sheets are a bad idea?
Data and Assumptions
Even within a company, one department’s business problem varies from the other. On a case to case basis, the data variety & complexity are too vast that no one single approach could be prescribed. But ML cheat sheet does exactly that.
For e.g. If data < 1k, choose algorithm X: Else If data > 1k, choose algorithm Y
Coming to the assumptions, there are multitudes of assumptions considered for every machine learning algorithm. Starting from, assumptions about the data generation process to assumptions about the model. These assumptions are simply not studied or evaluated in detail.
Cheat sheets put you on a path with no U-turns or detours
Much like hard coding in programming, cheat sheets for ML algorithms constrain your options. They put you on a path in which you merrily thread and once when you do realize that the path that you are on is wrong, it is often too late!
No opportunity to Innovate
If you go by cheat sheets, you are not taking the road less traveled. Needless to say, Innovation happens by taking the road less traveled. The cheat sheets don’t tell you to apply learning from one domain to another. Transfer learning ain’t happening here. Neither does it tell you to try some ensemble technique or to try some amalgamation of different algorithmic techniques. One is more or less like a horse with blinkers.
We (Data Scientists) stand on the shoulders of giants. Be it OLS from Legendre or Geoffrey Hinton’s various Deep learning techniques, none of them were invented by following cheat sheets.
Cheat sheet makes your Decision making ‘machine-like’
Well, coding machine learning algorithms does not mean you become the machine itself !! Cheat sheets often make your decisions binary at every stage.
For e.g
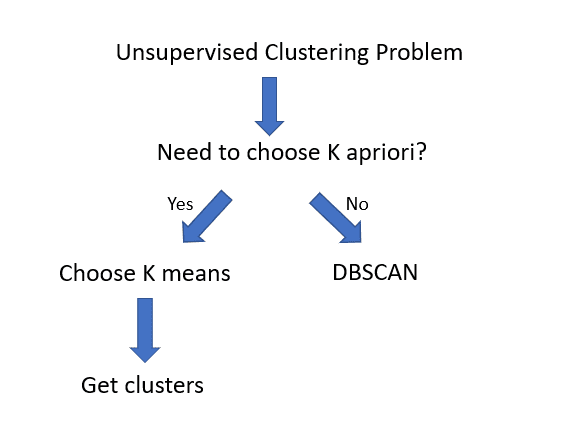
Voila, you have your clusters.. or do you?
A naive Data scientist or an aspiring Data Scientist would just be happy with clusters he/she got and just move on.
But here is the catch…
One of the pitfalls k means algorithm has is that it will cluster almost anything. Because we now have clusters, it does not mean we have accomplished anything! It is just a Pyrrhic victory.
So one can clearly see that, while a cheat sheet has led the data scientist down the path of K means algorithm, it gives a false sense of task completion when further probing is required.
No free lunch theory — The final nail in the coffin
Perhaps ‘No free lunch theory’ is the final nail in the coffin for ML cheat sheets. No free lunch theory states that
“There is no one model that works best for every problem. The assumptions of a great model for one problem may not hold for another problem”.
If there is no one model or algorithm which works best for every problem, then does it really make sense to have an ML algorithm cheat sheet?
So, please refrain from using ML algorithm cheat sheets. Try to arrive at a solution organically. Let your mind intuit and connect the dots!
Your comments and opinions are welcome.
{kind=link}