
Multicollinearity (Collinearity) is not a new term especially when dealing with multiple regression models. This phenomenon of relationship in between one response variable with the set of predictor variables also include models like classification and regression trees as well as neural networks. Collinearity is infamously famous for inflating the variance of at least one estimated regression coefficient, which can cause the model to predict erroneously and in a business setup it can have an unrepairable consequence.
So, the next logical question is how to identify collinearity?
While there are various techniques available to counter this problem, I specifically use two techniques that are readily available in most of the statistical applications:
- Variance Inflation Factor Identification Technique
- Best Subset Analysis – I wrote a specific article around this technique which can be acces….
In this article we will only talk about the Variance Inflation Factor(VIF) identification technique which is very useful for identify high multicollinearity among the predictor variables when working with MLR (Multiple Linear Regression Models).
It is also important to understand that VIF ranges from 1 upwards, where the VIF tells you in (decimal form) by what percentage the variance i.e. standard error squared is inflated for each coefficient.
Example:
VIF of 1.9 indicates that the variance for a particular coefficient is 90% bigger than what one should expect it to be.
Rules for identifying collinearity using VIF technique:
- If all values of VIF are near 1 indicates no collinearity between the predictor variables
- VIF of >1 to 5 indicates moderate collinearity
- VIF of >5 indicates serious collinearity
VIF values greater than 10 may indicate multicollinearity is unduly influencing your regression results. Consider removing unimportant predictors from your model.
In Minitab variance inflation factors can be obtained by running a simple multiple regression analysis via Stat>Regression>Regression>Fit Regression Model
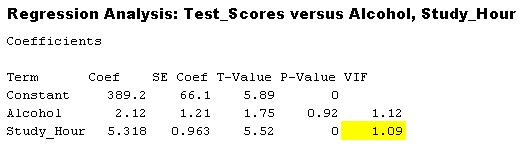
The below snapshot clearly shows the VIF results for a model where the analyst is trying to create a Student Test Score result predictions based on the study hours and the alcohol consumption.
Conclusion:
Multicollinearity is as much an opportunity as it is a problem to improve the predictability of the model and VIF identification is one of the effective and widely used procedures to improve the predictions for multiple linear regression model, helping the analysts to spot large variance inflating factors “without a sweat”.
{kind=link}