

The Markov Decision Process (MDP) provides a mathematical framework for solving the RL problem. Almost all RL problems can be modeled as an MDP. MDPs are widely used for solving various optimization problems. In this section, we will understand what an MDP is and how it is used in RL.
To understand an MDP, first, we need to learn about the Markov property and Markov chain.
The Markov property and Markov chain
The Markov property states that the future depends only on the present and not on the past. The Markov chain, also known as the Markov process, consists of a sequence of states that strictly obey the Markov property; that is, the Markov chain is the probabilistic model that solely depends on the current state to predict the next state and not the previous states, that is, the future is conditionally independent of the past.
For example, if we want to predict the weather and we know that the current state is cloudy, we can predict that the next state could be rainy. We concluded that the next state is likely to be rainy only by considering the current state (cloudy) and not the previous states, which might have been sunny, windy, and so on.
However, the Markov property does not hold for all processes. For instance, throwing a dice (the next state) has no dependency on the previous number that showed up on the dice (the current state).
Moving from one state to another is called a transition, and its probability is called a transition probability. We denote the transition probability by ![]() . It indicates the probability of moving from the state s to the next state
. It indicates the probability of moving from the state s to the next state  . Say we have three states (cloudy, rainy, and windy) in our Markov chain. Then we can represent the probability of transitioning from one state to another using a table called a Markov table, as shown in Table 1.1:
. Say we have three states (cloudy, rainy, and windy) in our Markov chain. Then we can represent the probability of transitioning from one state to another using a table called a Markov table, as shown in Table 1.1:
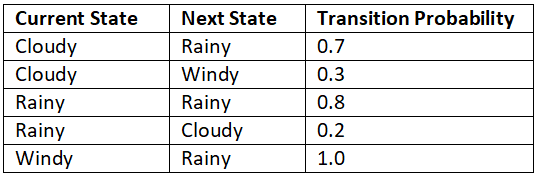
Table 1: An example of a Markov table
From Table 1, we can observe that:
- From the state cloudy, we transition to the state rainy with 70% probability and to the state windy with 30% probability.
- From the state rainy, we transition to the same state rainy with 80% probability and to the state cloudy with 20% probability.
- From the state windy, we transition to the state rainy with 100% probability.
We can also represent this transition information of the Markov chain in the form of a state diagram, as shown in Figure 1:
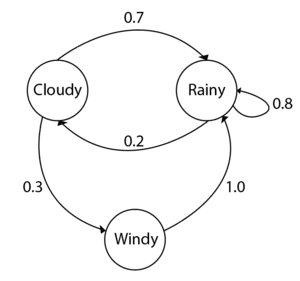
Figure 1: A state diagram of a Markov chain
We can also formulate the transition probabilities into a matrix called the transition matrix, as shown in Figure 2:
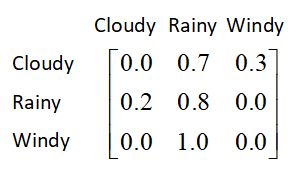
Figure 2: A transition matrix
Thus, to conclude, we can say that the Markov chain or Markov process consists of a set of states along with their transition probabilities.
The Markov Reward Process
The Markov Reward Process (MRP) is an extension of the Markov chain with the reward function. That is, we learned that the Markov chain consists of states and a transition probability. The MRP consists of states, a transition probability, and also a reward function.
A reward function tells us the reward we obtain in each state. For instance, based on our previous weather example, the reward function tells us the reward we obtain in the state cloudy, the reward we obtain in the state windy, and so on. The reward function is usually denoted by R(s).
Thus, the MRP consists of states s, a transition probability ![]() , and a reward function R(s).
, and a reward function R(s).
The Markov Decision Process
The Markov Decision Process (MDP) is an extension of the MRP with actions. That is, we learned that the MRP consists of states, a transition probability, and a reward function. The MDP consists of states, a transition probability, a reward function, and also actions. We learned that the Markov property states that the next state is dependent only on the current state and is not based on the previous state. Is the Markov property applicable to the RL setting? Yes! In the RL environment, the agent makes decisions only based on the current state and not based on the past states. So, we can model an RL environment as an MDP.
Let’s understand this with an example. Given any environment, we can formulate the environment using an MDP. For instance, let’s consider the same grid world environment we learned earlier. Figure 3 shows the grid world environment, and the goal of the agent is to reach state I from state A without visiting the shaded states:
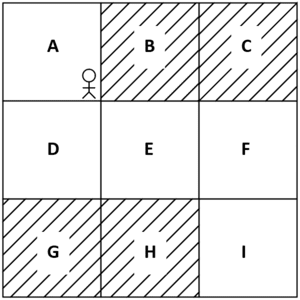
Figure 3: Grid world environment
An agent makes a decision (action) in the environment only based on the current state the agent is in and not based on the past state. So, we can formulate our environment as an MDP. We learned that the MDP consists of states, actions, transition probabilities, and a reward function. Now, let’s learn how this relates to our RL environment:
States – A set of states present in the environment. Thus, in the grid world environment, we have states A to I.
Actions – A set of actions that our agent can perform in each state. An agent performs an action and moves from one state to another. Thus, in the grid world environment, the set of actions is up, down, left, and right.
Transition probability – The transition probability is denoted by  . It implies the probability of moving from a state
. It implies the probability of moving from a state  to the next state while performing an action
to the next state while performing an action  . If you observe, in the MRP, the transition probability is just that is, the probability of going from state to state and it doesn’t include actions. But in MDP we include the actions, thus the transition probability is denoted by .
. If you observe, in the MRP, the transition probability is just that is, the probability of going from state to state and it doesn’t include actions. But in MDP we include the actions, thus the transition probability is denoted by .
For example, in our grid world environment, say, the transition probability of moving from state A to state B while performing an action right is 100% then it can be expressed as:  . We can also view this in the state diagram as shown below:
. We can also view this in the state diagram as shown below:
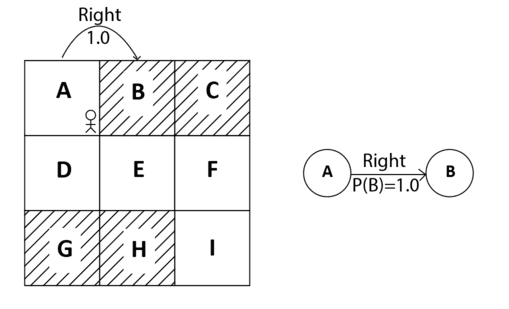
Figure 4: Transition probability of moving right from A to B
Suppose our agent is in state C and the transition probability of moving from state C to state F while performing the action down is 90%, then it can be expressed as P(F|C, down) = 0.9. We can also view this in the state diagram, as shown in Figure 5:
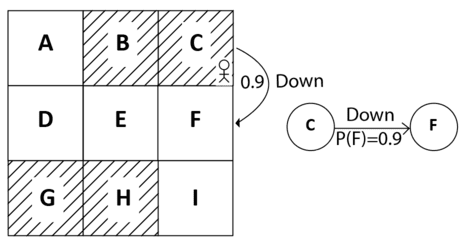
Figure 5: Transition probability of moving down from C to F
Reward function – The reward function is denoted by  . It implies the reward our agent obtains while transitioning from a state to the state while performing an action .
. It implies the reward our agent obtains while transitioning from a state to the state while performing an action .
Say the reward we obtain while transitioning from state A to state B while performing the action right is -1, then it can be expressed as R(A, right, B) = -1. We can also view this in the state diagram, as shown in Figure 6:
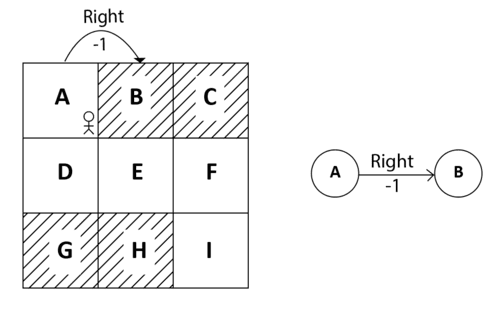
Figure 6: Reward of moving right from A to B
Suppose our agent is in state C and say the reward we obtain while transitioning from state C to state F while performing the action down is +1, then it can be expressed as R(C, down, F) = +1. We can also view this in the state diagram, as shown in Figure 7:
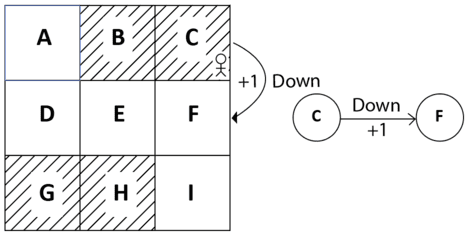
Figure 7: Reward of moving down from C to F
Thus, an RL environment can be represented as an MDP with states, actions, transition probability, and the reward function. Learn more in Deep Reinforcement Learning with Python, Second Edition by Sudharsan Ravichandiran.
{kind=link}