
Machine learning in finance may work magic, even though there is no magic behind it (well, maybe just a little bit). Still, the success of machine learning project depends more on building efficient infrastructure, collecting suitable datasets, and applying the right algorithms.
Machine learning is making significant inroads in the financial services industry. Let’s see why financial companies should care, what solutions they can implement with AI and machine learning, and how exactly they can apply this technology.
Definitions
We can define machine learning (ML) as a subset of data science that uses statistical models to draw insights and make predictions. The chart below explains how AI, data science, and machine learning are related. For the sake of simplicity, we focus on machine learning in this post.
The magic about machine learning solutions is that they learn from experience without being explicitly programmed. To put it simply, you need to select the models and feed them with data. The model then automatically adjusts its parameters to improve outcomes.
Data scientists train machine learning models with existing datasets and then apply well-trained models to real-life situations.

The model runs as a background process and provides results automatically based on how it was trained. Data scientists can retrain models as frequently as required to keep them up-to-date and effective. For instance, our client Mercanto retrains machine learning models every day.
In general, the more data you feed, the more accurate are the results. Coincidentally, enormous datasets are very common in the financial services industry. There are petabytes of data on transactions, customers, bills, money transfers, and so on. That is a perfect fit for machine learning.
As the technology evolves and the best algorithms are open-sourced, it’s hard to imagine the future of the financial services without machine learning.
That said, most financial services companies are still not ready to extract the real value from this technology for the following reasons:
- Businesses often have completely unrealistic expectations towards machine learning and its value for their organizations.
- AI and machine learning R&D is costly.
- The shortage of DS/ML engineers is another major concern. The figure below illustrates an explosive growth of demand for AI and machine learning skills.
- Financial incumbents are not agile enough when it comes to updating data infrastructure.

We will talk about overcoming these issues later in this post. First, let’s see why financial services companies cannot afford to ignore machine learning.
Why consider machine learning in finance?
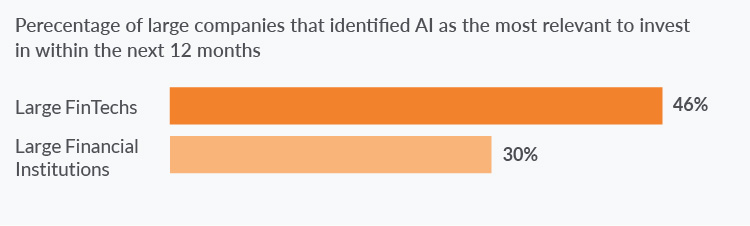
Despite the challenges, many financial companies already take advantage of this technology. The figure below shows that financial services’ execs take machine learning very seriously, and they do it for a bunch of good reasons:
- Reduced operational costs thanks to process automation.
- Increased revenues thanks to better productivity and enhanced user experiences.
- Better compliance and reinforced security.
There is a wide range of open-source machine learning algorithms and tools that fit greatly with financial data. Additionally, established financial services companies have substantial funds that they can afford to spend on state-of-the-art computing hardware.
Tanks to the quantitative nature of the financial domain and large volumes of historical data, machine learning is poised to enhance many aspects of the financial ecosystem.
That is why so many financial companies are investing heavily in machine learning R&D. As for the laggards, it can prove to be costly to neglect AI and ML.
What are machine learning use cases in finance?
Let’s take a look at some promising machine learning applications in finance.

Process Automation
Process automation is one of the most common applications of machine learning in finance. The technology allows to replace manual work, automate repetitive tasks, and increase productivity.
As a result, machine learning enables companies to optimize costs, improve customer experiences, and scale up services. Here are automation use cases of machine learning in finance:
- Chatbots
- Call-center automation.
- Paperwork automation.
- Gamification of employee training, and more.
Below are some examples of process automation in banking:
JPMorgan Chase launched a Contract Intelligence (COiN) platform that leverages Natural Language Processing, one of the machine learning techniques. The solution processes legal documents and extracts essential data from them. Manual review of 12,000 annual commercial credit agreements would typically take up around 360,000 labor hours. Whereas, machine learning allows to review the same number of contracts in a just a few hours.
BNY Mello integrated process automation into their banking ecosystem. This innovation is responsible for $300,000 in annual savings and has brought about a wide range of operational improvements.
Wells Fargo uses an AI-driven chatbot through the Facebook Messenger platform to communicate with users and provide assistance with passwords and accounts.
Privatbank is a Ukrainian bank that implemented chatbot assistants across its mobile and web platforms. Chatbots sped up the resolution of general customer queries and allowed to decrease the number of human assistants.
Security
Security threats in finance are increasing along with the growing number of transaction, users, and third-party integrations. And machine learning algorithms are excellent at detecting frauds.
For instance, banks can use this technology to monitor thousands of transaction parameters for every account in real time. The algorithm examines each action a cardholder takes and assesses if an attempted activity is characteristic of that particular user. Such model spots fraudulent behavior with high precision.
If the system identifies suspicious account behavior, it can request additional identification from the user to validate the transaction. Or even block the transaction altogether, if there is at least 95% probability of it being a fraud. Machine learning algorithms need just a few seconds (or even split seconds) to assess a transaction. The speed helps to prevent frauds in real time, not just spot them after the crime has already been committed.
Financial monitoring is another security use case for machine learning in finance. Data scientists can train the system to detect a large number of micropayments and flag such money laundering techniques as smurfing.
Machine learning algorithms can significantly enhance network security, too. Data scientists train a system to spot and isolate cyber threats, as machine learning is second to none in analyzing thousands of parameters and real-time. And chances are this technology will power the most advanced cybersecurity networks in the nearest future.
Adyen, Payoneer, Paypal, Stripe, and Skrill are some notable fintech companies that invest heavily in security machine learning.

Underwriting and credit scoring
Machine learning algorithms fit perfectly with the underwriting tasks that are so common in finance and insurance.
Data scientists train models on thousands of customer profiles with hundreds of data entries for each customer. A well-trained system can then perform the same underwriting and credit-scoring tasks in the real-life environments. Such scoring engines help human employees work much faster and more accurately.
Banks and insurance companies have a large number of historical consumer data, so they can use these entries to train machine learning models. Alternatively, they can leverage datasets generated by large telecom or utility companies.
For instance, BBVA Bancomer is collaborating with an alternative credit-scoring platform Destacame. The bank aims to increase credit access for customers with thin credit history in Latin America. Destacame accesses bill payment information from utility companies via open APIs. Using bill payment behavior, Destacame produces a credit score for a customer and sends the result to the bank.
Algorithmic trading
In algorithmic trading, machine learning helps to make better trading decisions. A mathematical model monitors the news and trade results in real-time and detects patterns that can force stock prices to go up or down. It can then act proactively to sell, hold, or buy stocks according to its predictions.
Machine learning algorithms can analyze thousands of data sources simultaneously, something that human traders cannot possibly achieve.
Machine learning algorithms help human traders squeeze a slim advantage over the market average. And, given the vast volumes of trading operations, that small advantage often translates into significant profits.
Robo-advisory
Robo-advisors are now commonplace in the financial domain. Currently, there are two major applications of machine learning in the advisory domain.
Portfolio management is an online wealth management service that uses algorithms and statistics to allocate, manage and optimize clients’ assets. Users enter their present financial assets and goals, say, saving a million dollars by the age of 50. A robo-advisor then allocates the current assets across investment opportunities based on the risk preferences and the desired goals.
Recommendation of financial products. Many online insurance services use robo-advisors to recommend personalized insurance plans to a particular user. Customers choose robo-advisors over personal financial advisors due to lower fees, as well as personalized and calibrated recommendations.
How to make use of machine learning in finance?
In spite of all the advantages of AI and machine learning, even companies with deep pockets often have a hard time extracting the real value from this technology. Financial services incumbents want to exploit the unique opportunities of machine learning but, realistically, they have a vague idea of how data science works, and how to use it.
Time and again, they encounter similar challenges like the lack of business KPIs. This, in turn, results in unrealistic estimates and drains budgets. It is not enough to have a suitable software infrastructure in place (although that would be a good start). It takes a clear vision, solid technical talent, and determination to deliver a valuable machine learning development project.
As soon as you have a good understanding of how this technology will help to achieve business objectives, proceed with idea validation. This is a task for data scientists. They investigate the idea and help you formulate viable KPIs and make realistic estimates.
Note that you need to have all the data collected at this point. Otherwise, you would need a data engineer to collect and clean up this data.
Depending on a particular use case and business conditions, financial companies can follow different paths to adopt machine learning. Let’s check them out.
Forgo machine learning and focus on big data engineering instead
Often, financial companies start their machine learning projects only to realize they just need proper data engineering. Max Nechepurenko, a senior data scientist at N-iX, comments:
When developing a [data science] solution, I’d advise using the Occam’s razor principle, which means not overcomplicating. Most companies that aim for machine learning in fact need to focus on solid data engineering, applying statistics to the aggregated data, and visualization of that data.
Merely applying statistical models to processed and well-structured data would be enough for a bank to isolate various bottlenecks and inefficiencies in its operations.
What are the examples of such bottlenecks? That could be queues at a specific branch, repetitive tasks that can be eliminated, inefficient HR activities, flaws of the mobile banking app, and so on.
What’s more, the biggest part of any data science project comes down to building an orchestrated ecosystem of platforms that collect siloed data from hundreds of sources like CRMs, reporting software, spreadsheets, and more.
Before applying any algorithms, you need to have the data appropriately structured and cleaned up. Only then, you can further turn that data into insights. In fact, ETL (extracting, transforming, and loading) and further cleaning of the data account for around 80% of the machine learning project’s time.

Use third-party machine-learning solutions
Even if your company decides to utilize machine learning in its upcoming project, you do not necessarily need to develop new algorithms and models.
Most machine learning projects deal with issues that have already been addressed. Tech giants like Google, Microsoft, Amazon, and IBM sell machine learning software as a service.
These out-of-the-box solutions are already trained to solve various business tasks. If your project covers the same use cases, do you believe your team can outperform algorithms from these tech titans with colossal R&D centers?
One good example is Google’s multiple plug-and-play recommendation solutions. That software applies to various domains, and it is only logical to check if they fit to your business case.
A machine learning engineer can implement the system focusing on your specific data and business domain. The specialist needs to extract the data from different sources, transform it to fit for this particular system, receive the results, and visualize the findings.
The trade-offs are lack of control over the third-party system and limited solution flexibility. Besides, machine learning algorithms don’t fit into every use case. Ihar Rubanau, a senior data scientist at N-iX comments:
A universal machine learning algorithm does not exist, yet. Data scientists need to adjust and fine-tune algorithms before applying them to different business cases across different domains.
So if an existing solution from Google solves a specific task in your particular domain, you should probably use it. If not, aim for custom development and integration
Innovation and integration
Developing a machine learning solution from scratch is one of the riskiest, most costly and time-consuming options. Still, this may be the only way to apply ML technology to some business cases.
Machine learning research and development targets a unique need in a particular niche, and it calls for an in-depth investigation. If there are no ready-to-use solutions that were developed to solve those specific problems, third-party machine learning software is likely to produce inaccurate results.

Still, you will probably need to rely heavily on the open source machine learning libraries from Google and the likes. Current machine learning projects are mostly about applying existing state-of-the-art libraries to a particular domain and use case.
At N-iX, we have identified seven common traits of a successful enterprise R&D project in machine learning. Here they are:
- A clear objective. Before collecting the data, you need at least some general understanding of the results you want to achieve with AI and machine learning. At the early stages of the project, data scientists will help you turn that idea into actual KPIs.
- Robust architecture design of the machine learning solution. You need an experienced software architect to execute this task.
- Appropriate big data engineering ecosystem (based on Apache Hadoop or Spark) is a must-have. It allows to collect, integrate, store, and process huge amounts of data from numerous siloed data sources of the financial services companies. Big data architect and big data engineers are responsible for constructing the ecosystem.
- Running ETL procedures (extract, transform, and load) on the newly created ecosystem. A big data architect or a machine learning engineer perform this task.
- The final data preparation. Besides data transformation and technical clean-up, data scientists may need to refine the data further to make it suitable for a specific business case.
- Applying appropriate algorithms, creating models based on these algorithms, fine-tuning models, and retraining models with new data. Data scientists and machine learning engineers perform these tasks.
- Lucid visualization of the insights. Business intelligence specialists are responsible for that. Besides, you may need frontend developers to create dashboards with easy-to-use UI.
Small projects may require significantly less effort and a much smaller team. For instance, some R&D projects deal with small datasets, so they probably don’t need sophisticated big data engineering. In other instances, there is no need in complex dashboards or any data visualization at all.
Key takeaways
- Financial incumbents most frequently use machine learning for process automation and security.
- Before collecting the data, you need to have a clear view of the results you expect from data science. There is a need to set viable KPIs and make realistic estimates before the project’s start.
- Many financial services companies need data engineering, statistics, and data visualization over data science and machine learning.
- The bigger and cleaner a training dataset is, the more accurate results a machine learning solution produces.
- You can retrain your models as frequently as you need without stopping machine learning algorithms.
- There is no universal machine learning solution to apply to different business cases.
- The machine learning development is costly.
- Tech giants like Google create machine learning solutions. If your project concerns such use cases, you cannot expect to outperform algorithms from Google, Amazon, or IBM.
This article was originally published at www.n-ix.com
{kind=link}