
Describing and picturing MLAlgos and Machine Learning is the main idea of this post. I will attempt to answer few basic questions as well. Though these questions have been answered many a times in the past and are widely available. Answering them again here from my very own experience on the ground may makes the difference though rather then simply answering from phd or scholar books material prospective.
- Machine Learning at a Glance
- Types of Machine Learning
- Algorithms in Machine Learning – MLAlgos
The learning process for human child or new machine algorithm is same regardless of the fact that something is made up of bones and flash or wires and metal.
Machine Learning at a Glance
Machine learning is subset to Artificial Intelligence which borrows principles from computer science. It is not an AI though; It is focal point where business and experience meet emerging technology and decides to work together. ML also has very close relationship to statistics; which is a graphical branch of mathematics. It instructs an algorithm to learn for itself by analyzing data. The more data it processes, the smarter the algorithm gets. Until only recently even though foundation was laid down in 1950 ML remained largely confined to academia.
ML has Organizations have had success with each type of learning, but making the right choice for your business problem requires an understanding of which conditions are best suited for each approach. Types of machine learning algorithms i.e. MLAlgos and which one to be used when is extremely important to know. The goal of the task and all the things that are being done in the field and put you in a better position to break down a real problem and design a machine learning system.
Types of Machine Learning
Before we get into MLAlgos lets understand some basics here. The approach of developing ML includes learning from data inputs based on “What has happened”. Evaluating and optimising different model results remains focus here. As on date Machine Learning is widely used in data analytics as a method to develop algorithms for making predictions on data. It is related to probability, statistics, and linear algebra.
Machine Learning is classified into four categories at high level depending on the nature of the learning and learning system. Some how I find difficult to accept Semi-supervised Learning.

3 Major + 1 Non Major Types
- Supervised learning: Supervised learning gets labelled inputs and their desired outputs. The goal is to learn a general rule to map inputs to the output.
- Unsupervised learning: Machine gets inputs without desired outputs, the goal is to find structure in inputs.
- Reinforcement learning: In this algorithm interacts with a dynamic environment, and it must perform a certain goal without guide or teacher.
- Semi-supervised Learning: This type of ml i.e. semi-supervised algorithms are the best candidates for the model building in the absence of labels for some data. So if data is mix of label and un-label then this can be the answer. Typically a small amount of labeled data with a large amount of unlabeled data is used here.

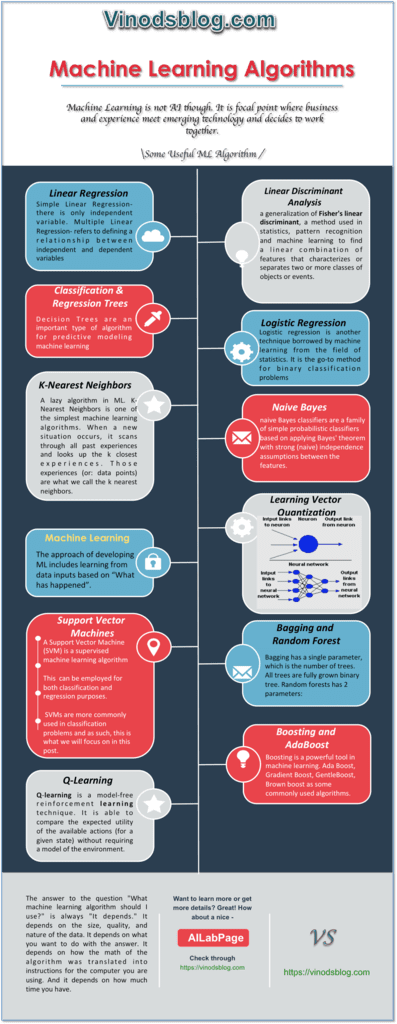
Some of the popular Machine Learning Algorithms (MLAlgos)
- Linear Regression – Simple Linear Regression- there is only independent variable. Multiple Linear Regression- refers to defining a relationship between independent and dependent variables
- Logistic Regression – A super simple form of regression analysis in which the outcome variable is binary or dichotomous. Helps to estimate adjusted prevalence rates, adjusted for potential confounders (sociodemographic or clinical characteristics)
- Linear Discriminant Analysis – A generalization of Fisher’s linear discriminant, a method used in statistics, pattern recognition and machine learning to find a linear combination of features that characterizes or separates two or more classes of objects or events.
- Classification and Regression Trees- Decision trees are are an important type of algorithm for predictive modeling machine learning. A greedy algorithm based on divide and conquer rule. Split the records based on an attribute test that optimizes certain criterion. Real value is in determining how to split the records.
- Naive Bayes – Naive Bayes classifiers are a family of simple probabilistic classifiers based on applying Bayes’ theorem with strong (naive) independence assumptions between the features.
- K-Nearest Neighbors – A laziest algorithm which is also very simple algorithm that stores all available cases and predict the numerical target based on a similarity measure. In the beginning of 1970’s as a non-parametric technique KNN has been used in statistical estimation and pattern recognition already.
- Learning Vector Quantization- It has aim i.e. representation of large amounts of data by (few) prototype vectors by identification and grouping in clusters of similar data.
To read full post here
Thank you all, for spending your time reading this post. Please share your feedback / comments / critics / agreements or disagreement. Remark for more details about posts, subjects and relevance please read the disclaimer.
{kind=link}