
Via Nitish Tiwari
Kubernetes has fundamentally altered the traditional application development and deployment patterns. Application development teams can now develop, test and deploy their apps in days, across different environments, all within their Kubernetes clusters. Previous generations of technology typically took weeks if not months.
This acceleration is possible due to the abstraction that Kubernetes brings to the table, i.e. it deals with underlying details of physical or virtual machines, while allowing the users to declare CPU, memory, number of container instances among other parameters. Supported by a large, loving community and ever-increasing adoption, Kubernetes is the leading container orchestration platform, by a considerable margin.
As the adoption grows, the confusion over storage patterns in Kubernetes is growing too.
With everyone competing for a piece of the Kubernetes storage pie, there is a lot of noise around storage options, drowning the signal.
Kubernetes is the modern model for application development, deployment and management. The modern model disaggregates storage and compute. To fully understand disaggregation in the Kubernetes context we need to also understand the concepts of stateful and stateless applications and storage. This is where the RESTful API approach of S3 offers a clear advantage over the POSIX/CSI approach offered by alternative solutions.
This post discusses Kubernetes storage patterns and addresses the stateless vs stateful debate with the goal of understanding exactly why there is a difference and why it matters. Later in the post, we cover applications and their storage patterns in light of container and Kubernetes best practices.
Stateless containers
Containers are inherently lightweight and ephemeral in nature, they can be easily stopped, deleted, or deployed to another node, all within a few seconds. In a large container orchestration system, this happens all the time without its consumers even noticing such shifts. But, this movement is possible only if the container doesn’t have any data dependency on the underlying node. Such containers are stateless.
Stateful containers
If a container stores data on locally mounted drives (or block device), the underlying storage would have to be moved to the new node alongwith the container itself – in case of a failure. This is important, otherwise the application running in the container can’t function properly because it needs to refer to the data it stored on the local mounts. Such containers are stateful.
Technically, stateful containers can move around to different nodes as well. Generally this is achieved via distributed file systems or network block storage attached to all the nodes where containers are running. This way, containers get access to persistent volume mounts and data is stored to the attached storage which is available across the network. I will refer to this approach as the stateful container approach for the rest of the article for uniformity.
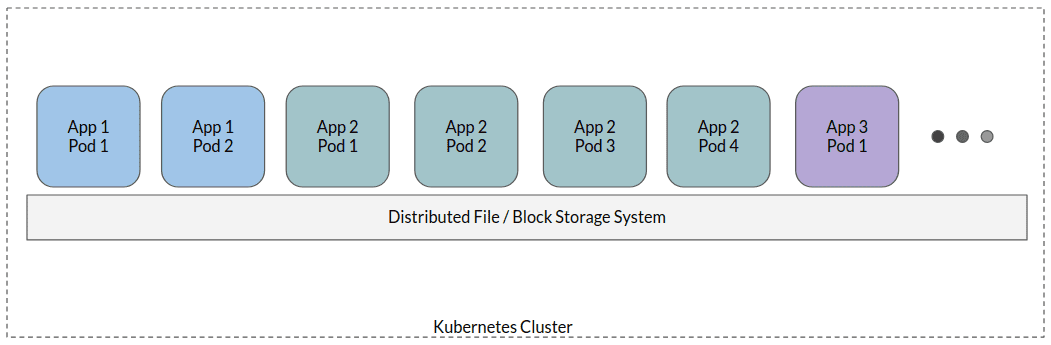
In a typical stateful container approach, application pods are mounted to one distributed file system – sort of a shared storage where all the application data resides. While there may be some variations, this is the high level approach.
Now, lets understand why the stateful container approach is an anti-pattern in a cloud-native world.
Cloud-Native Application Design
Traditionally applications used databases for structured data and local drives or distributed file systems to dump all of their unstructured and even semi-structured data. As unstructured data grew, developers realized that POSIX was too chatty, had significant overhead taxes that ultimately held back the application from performing at scale.
This largely contributed to a new storage standard, i.e. cloud-native storage, driven by RESTful APIs, freeing the application of any burden to handle local storage and making it effectively stateless (as state is with the remote storage system). Modern applications are built ground up keeping this in consideration. Typically any modern application that deals with some kind of data (logs, metadata, blobs, etc), conforms to the cloud-native design by shipping the state to a relevant storage system.
The stateful container approach takes it all right back to where it started!
With POSIX interfaces to store data, applications behave in a stateful manner and lose the most important tenets of cloud-native design, i.e. ability to have application workers grow and shrink based on inbound load, move to a new node as soon as a current node goes down and so on.
As we get more specific we find that we are in the POSIX vs REST API for storage all over again, BUT with additional amplification of POSIX issues due to the distributed nature of Kubernetes environments. Specifically,
- POSIX is Chatty: POSIX semantics requires each operation to have associated metadata and file descriptors that maintain the state of the operation. This leads to a lot of overhead which doesn’t add any real value. Object storage APIs like S3 API got rid of these requirements, allowing applications to fire and forget the call. A response from the storage system indicates whether the action was successful or not. In case of failure, applications can retry.
- Network limitations: In a distributed system, it is implicit that there may be multiple applications trying to write data to a single mount. So, not only do the applications contend for bandwidth (to send data to the mount), the storage system itself contends for bandwidth on the same network to send data to actual drives. Due to POSIX chatiness, the number of network calls increases several fold. S3 API on the other hand allows a clear segregation of network calls between client to server and internal server calls.
- Security: The POSIX security model was built for human users, with administrators configuring specific access levels for each user or group. This makes it difficult to adapt to cloud-native world. Modern applications depend on API based security models with policy defined access, service accounts, temporary credentials and so on.
- Manageability: Stateful containers add management overhead. Syncing parallel data access, ensuring data consistency, etc. need careful consideration of data access patterns. This means more software to install, manage, and configure, and of course additional development effort.
Container Storage Interface
While CSI did a great job at extending the Kubernetes volume layer to third party storage vendors, it also inadvertently led the ecosystem to believe the stateful container approach as the recommended storage approach in Kubernetes.
CSI was developed as a standard for exposing arbitrary block and file storage storage systems to legacy applications on Kubernetes. And, as we saw in this post, the only situation where stateful container approach (and CSI in its current form) makes sense is if the application itself is a legacy system with no possibility to add support for object storage APIs.
It is important to understand that using CSI in its current form, i.e. volume mounts with modern applications, will ultimately lead to similar problems that we have been seeing with POSIX style storage systems.
The Better Approach
The important thing to understand is that most of the applications are not inherently stateful or stateless. Their behaviour is defined by the overall architecture and specific design choices. Of course there are storage applications that need to be stateful (e.g. MinIO). We’ll talk about stateful apps in a bit.
In general, application data can be categorized into a few broad types:
- Log data
- TimeStamp data
- Transaction data
- Metadata
- Container images
- Blob data
All these data types are very well supported among modern storage platforms and there are several cloud-native platforms available to cater to each of these specific data formats. For example transactional data and metadata can sit in a modern, cloud-native database like CockroachDB, YugaByte etc. Container images or blob data can be stored on a docker registry based on MinIO. TimeStamp Data can be stored on time series databases like InfluxDB and so on. We’ll skip going into details of each data type and the relevant application, but the idea is to avoid local mount based persistence.
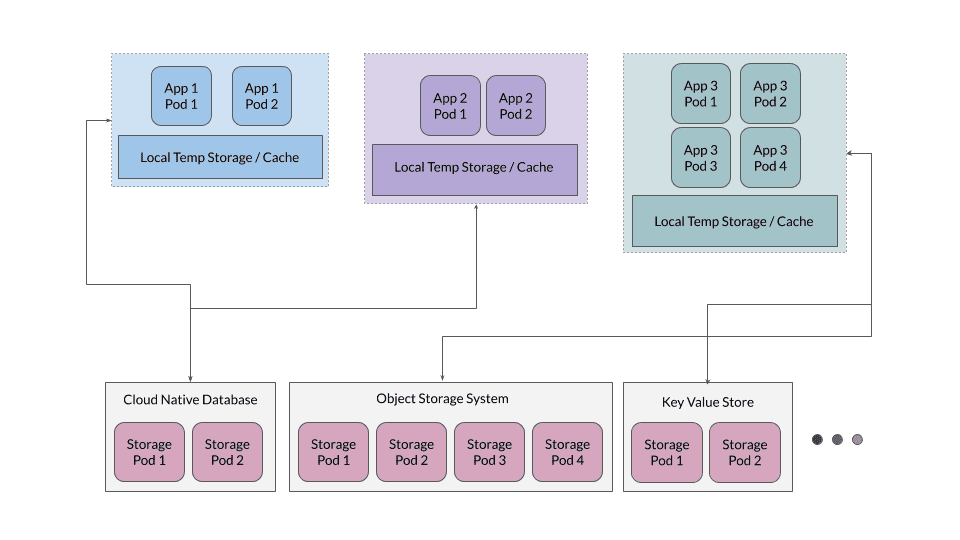
Additionally in many cases, it is efficient to have a temporary caching layer available as scratch space for the applications, but the application should not depend on this layer as the source of truth.
Stateful Applications Storage
While generally it is better to keep the applications stateless, storage applications e.g. Databases, Object Stores, Key Value stores need to be stateful. Let’s understand how these applications are deployed on Kubernetes. I’ll take MinIO as an example, but similar principles apply for all major cloud native storage systems.
Cloud native storage applications are designed to leverage the flexibility containers bring, this means these applications do not make assumptions about the environment in which they are deployed. For example MinIO uses an internal erasure coding mechanism to ensure there is enough redundancy in the system to allow up to half of the drives to fail. MinIO also manages the data integrity and security using own hashing and server side encryption.
For such cloud native applications, local persistent volumes (PVs) are best suited as the backing storage. Local PVs offer the raw storage capacity, while the application running on top of these PVs uses its own intelligence to scale and manage the growing data requirements.
This is a much simpler and scalable approach as compared to CSI based PVs that bring their own management and redundancy layers which generally compete with the stateful application’s design.
The steady march towards disaggregation
In this post we talked about applications going stateless, or, in other terms, disaggregating storage from compute. Now, let’s take a look at some real world examples of this trend.
Spark, the famous data analytics platform has been traditionally run in a stateful manner on HDFS oriented deployments but as it moves to the cloud native world, Spark is increasingly run in a stateless manner on Kubernetes using the `s3a` connector. Spark uses the connector to ship state to other systems while Spark containers themselves are running completely stateless. Other major enterprise players in big data analytics space like Vertica, Teradata, Greenplum are also moving to a disaggregated model of compute and storage.
Similarly, all the other major analytics platforms from Presto, Tensorflow to R, Jupyter notebooks follow such patterns. Offloading state to remote cloud storage systems makes your application much easier to scale and manage. Additionally, it helps keep the application portable to different environments.
{kind=link}