
Summary: In a comprehensive study of 18 recently presented DNN advancements in top-N recommenders, only 7 presented sufficient data to allow reproduction. Worse, of the 7 that could be reproduced none showed an actual improvement over simple linear and KNN techniques when those were properly optimized.
 Imagine you are the head of a major data science team at an ecommerce site where recommenders are a key tool to increase revenue. You pride yourself that both you and your team keep up to date on the latest advances by attending conferences and monitoring papers.
Imagine you are the head of a major data science team at an ecommerce site where recommenders are a key tool to increase revenue. You pride yourself that both you and your team keep up to date on the latest advances by attending conferences and monitoring papers.
Your trusted lead on recommenders rushes up with a new paper in hand. Just back from the RecSys conference where the paper was presented he shows you the results. It appears your top-N recommender could be made several percentage points better using the new technique. The downside is that it would require you to adopt one of the new DNN collaborative filtering models which would be much more compute intensive and mean a deep reskilling dive for some of your team.
Would you be surprised to find out that the results in that paper are not reproducible? Or more, that the baseline techniques to which it was compared to show improvements were not properly optimized. And, if they had been, the much simpler techniques would be shown to be superior.
In a recent paper “Are We Really Making Much Progress”, researchers Maurizio Ferrari Dacrema, Paolo Cremonesi, Dietmar Jannach raise a major red flag. Houston, we have a reproducibility problem.
Further, when they did succeed in reproducing the techniques described in the paper, they found almost universally that the baseline comparisons had been poorly optimized. And if optimized the simpler baseline techniques outperformed the glitzy new procedure.
Their surprising finding starts with their systematic search for papers from major conferences that report on advances in top-N recommenders that relied on advances in deep learning methods. They identified 18 in all. Of the 18, only 7 provided sufficient detail including source code and datasets used to attempt to reproduce the results. That’s disappointing for the 11 papers that couldn’t be tested but there’s more.
Of the 7 that could be reproduced they found in 6 cases that well-tuned much simpler linear or nearest neighbor models actually outperformed. In the remaining one case, the new model outperformed in some instances but not in others.
The simpler linear methods they used for comparison are these. Chances are you’re using these too.
Top Popular: A non-personalized method that recommends the most popular items to everyone. Popularity is measured by the number of explicit or implicit ratings.
Item KNN: A traditional Collaborative-Filtering (CF) approach based on k-nearest-neighborhood (KNN) and item-item similarities.
User KNN: A neighborhood-based method using collaborative user-user similarities.
Item KNN-CBF: A neighborhood content-based-filtering (CBF) approach with item similarities computed by using item content features.
Item KNN-CFCBF: A hybrid CF+CFB algorithm based on item-item similarities.
P3α: A simple graph-based algorithm which implements a random walk between users and items.
RP3β: A version of P3α where the outcomes of P3α are modified by dividing the similarities by each item’s popularity raised to the power of a coefficient.
In all cases the baseline comparison cases were optimized via Bayesian search using Scikit-Optimize6. For each test the researchers examined 35 cases varying initial random points, neighborhood sizes, and shrink terms.
Here’s a brief description of the DNN ‘improved’ techniques that proved not to be improved at all once the baseline techniques were properly optimized.
Collaborative Memory Networks (CMN)
The CMN method was presented at SIGIR ’18 and combines memory networks and neural attention mechanisms with latent factor and neighborhood models. After optimizing the baselines CMN in no single instance against three test datasets was best performing. The table below shows the test results with higher performing models shown in bold.
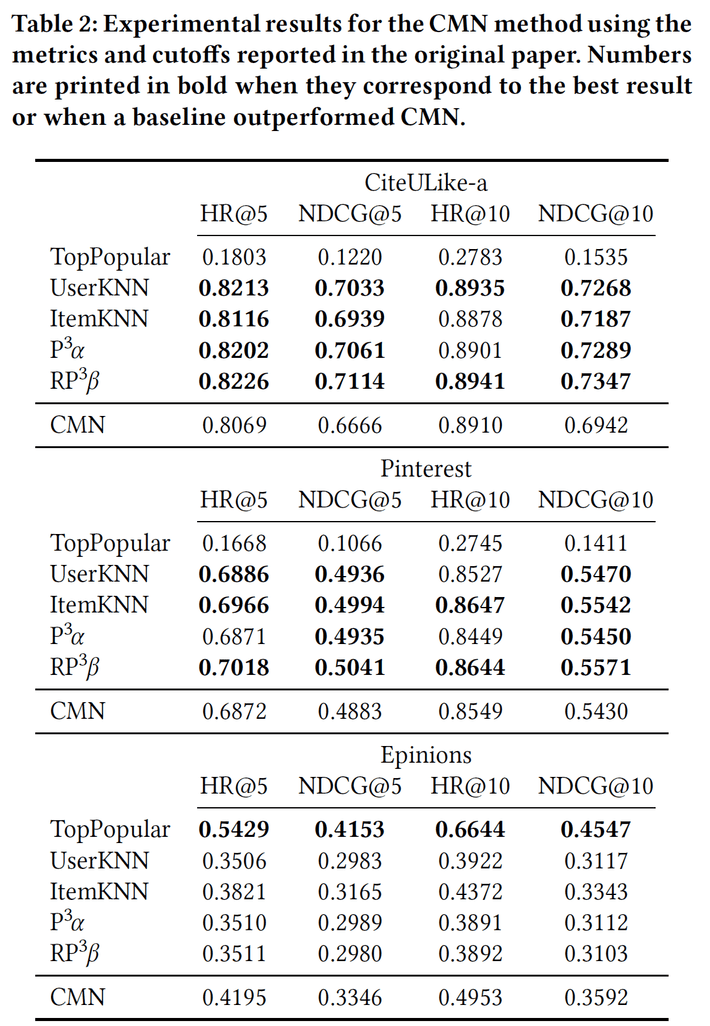
The authors present similar tables for each of the following tests which you can see in the original paper.
Metapath based Context for RECommendation (MCRec)
MCRec presented at KDD ’18 is a meta-path based model that leverages auxiliary information like movie genres for top-n recommendation. From a technical perspective, the authors propose a priority-based sampling technique to select higher-quality path instances and propose a novel co-attention mechanism to improve the representations of meta-path based context, users, and items.
Collaborative Variational Autoencoder (CVAE)
The CVAE method presented at KDD ’18 is a hybrid technique that considers both content as well as rating information. The model learns deep latent representations from content data in an unsupervised manner and also learns implicit relationships between items and users from both content and ratings.
Collaborative Deep Learning (CDL)
The discussed CVAE method considers the earlier and often-cited CDL method from KDD ’15 as one of their baselines, and the authors also use the same evaluation procedure and CiteULike datasets. CDL is a probabilistic feed-forward model for joint learning of stacked denoising autoencoders (SDAE) and collaborative filtering. It applies deep learning techniques to jointly learn a deep representation of content information and collaborative information.
Neural Collaborative Filtering (NCF)
Neural network-based Collaborative Filtering presented at WWW ’17 generalizes Matrix Factorization by replacing the inner product with a neural architecture that can learn an arbitrary function from the data. The proposed hybrid method (NeuMF) was evaluated on two datasets (MovieLens1M and Pinterest), containing 1 million and 1.5million interactions, respectively.
Spectral Collaborative Filtering (SpectralCF)
SpectralCF presented at RecSys ’18 was designed to specifically address the cold-start problem and is based on concepts of Spectral Graph Theory. Its recommendations are based on the bipartite user-item relationship graph and a novel convolution operation, which is used to make collaborative recommendations directly in the spectral domain.
The previous six techniques were all found to be inferior to well-trained simple baseline techniques. The following technique was shown to have a small improvement against the upgraded baselines using SLIM but that difference disappeared under slightly different test conditions.
Variational Autoencoders for Collaborative Filtering (Mult-VAE)
Mult-VAE is a collaborative filtering method for implicit feedback based on variational autoencoders. The work was presented at WWW ’18. With Mult-VAE, the authors introduce a generative model with multinomial likelihood, propose a different regularization parameter for the learning objective, and use Bayesian inference for parameter estimation. They evaluate their method on three binarized datasets that originally contain movie ratings or song play counts.
Using their code and datasets, we found that the proposed method indeed consistently outperforms our quite simple baseline techniques. The obtained accuracy results were between 10% and 20% better than our best baseline. Thus, with Mult-VAE, we found one example in the examined literature where a more complex method was better, by a large margin, than any of our baseline techniques in all configurations.
For both datasets, we could reproduce the results and observe improvements over SLIM of up to 5% on the different measures reported in the original papers.
The differences between Mult-VAE and SLIM in terms of the NDCG, the optimization goal, are quite small. In terms of the Recall, however, Mult-VAE improvements over SLIM seem solid. Since the choice of the used cutoffs (20 and 50 for Recall, and 100 for NDCG) is not very consistent in we made additional measurements at different cutoff lengths. They show that when using the NDCG as an optimization goal and as a performance measure, the differences between SLIM and Mult-VAE disappear on this dataset, and SLIM is actually sometimes slightly better.
Takeaway
Before adopting DNN approaches that are the ‘hot new thing’ you might consider trying to reproduce the results yourself. As these authors found, not many of these papers provide sufficient information to reproduce their findings and as in this study, essentially all the DNN techniques were found to be inferior to simpler techniques when those were properly optimized.
Other articles by Bill Vorhies
About the author: Bill is Contributing Editor for Data Science Central. Bill is also President & Chief Data Scientist at Data-Magnum and has practiced as a data scientist since 2001. His articles have been read more than 2.1 million times.
{kind=link}