
Summary: Can AI take its victory lap in 2016? A lot depends on what you call AI and whether the consumer can perceive it.
 Image source: skymind.io
Image source: skymind.io
If 2016 is to be “the year of AI” as some folks are speculating then we ought to take a look at what that might actually mean. For starters, is AI sufficiently mature and will it matter in the every day world of consumers? I’ll stipulate that AI is already relevant to a sizable minority of data scientists, especially those directly involved in AI projects. But like the balance of data science, real economic importance comes when our knowledge is put to use in the broad economy. Hence the emphasis on whether consumers will give a hoot.
Like a lot of other DS disciplines, this doesn’t mean that Jane and Joe consumer even need to know that DS is at work. It does mean that Jane and Joe would recognize that their lives are less convenient or efficient if the DS was suddenly removed.
What the consumer sees
Since this is CES season (Consumer Electronics Show for those of you not near any sort of video screen for the last week) this might be a good place to look to see how and if AI is making its way into the consumer world. Here’s a more or less random sampling of 2016 CES new product rollouts:
- Samsung SUHD televisions
- Robot bartender
- Smart shower head (change color if you use too much water)
- Google/Lenovo Project Tango depth sensing for Android phones
- iLi wearable translator
- Advanced 3D printers
- Lyve photo organizer (organizes your digital pictures)
- Virtual reality headsets
Yes there are thousands of products at CES, but here’s the test. Of these eight new products, which rely on artificial intelligence? In my opinion there are only two, the iLi wearable translator, and the Lyve photo organizer. A little explanation about these two.
The iLi wearable translator is a sleek gadget about the size of a small TV remote control with speakers and mics on each side. Speak English into one side and it immediately broadcasts the translation into Mandarin, Japanese, French, Thai, or Korean out the other. Yes it works in reverse (Mandarin in, English out) and no WiFi required, all on board memory. Shades of Star Trek.
The Lyve photo organizer is an app in your PC or tablet that recognizes, finds, and organizes your digital photos. Find all the pictures of Aunt Sally. Show me pictures of Joe when he was a boy. Display the pictures from the Grand Canyon vacation two years ago.
These two devices show two of the three primary applications of AI best known today, voice processing, image processing, and (unrepresented in this example) text processing.
From the data science side you should immediately recognize these as capabilities of Deep Learning, perhaps best described as unsupervised pattern recognition utilizing neural net architecture.
What exactly do we mean by AI?
If you’re a data science practitioner and following the literature then you’ve probably experienced that 9 out of 10 articles on AI directly tie to deep learning. But is this the full breadth of AI from the consumers perspective?
Not to turn this into a definitional food fight, the original definitions of AI specified creating machines that could perform tasks that when performed by humans were perceived to require intelligence. Note that no one said that the AI machines had to use the same logic as humans to achieve the task.
 For example, IBM’s chess playing phenom Deep Blue played superlative chess but was widely acknowledged not to play the way humans do, instead utilizing its ability to project tens of thousands of potential move combinations and evaluate the statistical value at each step.
For example, IBM’s chess playing phenom Deep Blue played superlative chess but was widely acknowledged not to play the way humans do, instead utilizing its ability to project tens of thousands of potential move combinations and evaluate the statistical value at each step.
Interesting chess factoid:
-
Feb 10, 1996 first win by a computer against a top human.
-
Nov 21, 2005 last win by a human against a top computer.
Strong versus Weak AI
This opens the door to two divisions in the field of AI: Strong AI and Weak AI. The Strong AI camp works on solutions genuinely simulating human reasoning (very limited success here so far). The Weak AI camp wants to build systems that behave like humans, pragmatically just getting the system to work. Deep Blue is an example of Weak AI.
There is a middle ground between these two and the Jeopardy-playing computer, IBM’s Watson is an example. These are systems inspired by human reasoning but not trying to exactly model it. Watson looks at thousands of pieces of text that give it confidence in its conclusion. Like people, Watson is able to notice patterns in text each of which represents an increment of evidence, then add up that evidence to draw the most likely conclusion. Some of the strongest work in AI today is taking place in this middle ground.
Narrow versus Broad AI
Another division in AI development is Narrow AI versus Broad AI. Given that the requirement is that the machine perform the same task as a human then Narrow AI allows for lots of examples, especially outside of deep learning. For example, systems that recommend options (what to watch, who to date, what to buy) can be built on Association math or graph analysis, much simpler than and completely unrelated to deep learning. Your Roomba can find its way back to its charging station but that system doesn’t generalize beyond that narrow application.
So its apparent that consumers today are already experiencing lots of examples of Narrow AI. In fact while there are still opportunities in Narrow AI, much of the data science foundation has been fully explored and exploited. That may be of interest to consumers in these very narrow applications but I’m not sure that even Joe and Jane consumer would say this is the AI they were promised along with their jet packs and flying cars. What we’re aiming for is the opposite, Broad AI systems that can be generalized to many applications.
Deep Learning and the Goal of Broad and Not-Wimpy AI
For data scientists and consumers it appears the way forward is Deep Learning. Other competing technologies may enter the field. For example it’s been some time since we’ve heard from Genetic Programs which compete directly with Neural Nets. But like Big Science, with all the money pouring into a single alternative, Deep Learning, that’s where we’re most likely to see break throughs.
We’re not satisfied with narrow apps. Give us a system that generalizes. And we don’t care on the strong/weak axis how we get there (hence ‘not-wimpy’) so long as it works.
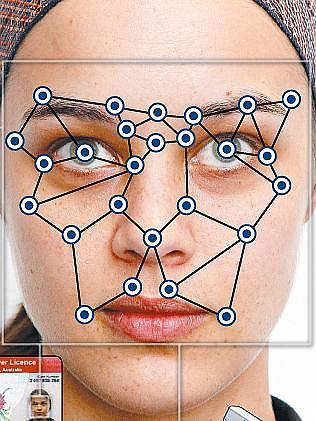 In this category, true consumer applications are not common and belong mostly to the innovation giants like Google (Android voice recognition and self driving cars), Facebook (image recognition), and Microsoft Skype (instant translation).
In this category, true consumer applications are not common and belong mostly to the innovation giants like Google (Android voice recognition and self driving cars), Facebook (image recognition), and Microsoft Skype (instant translation).
Outside of these three there are a handful of interesting examples. One of the best developed is the ability to perform text analysis on legal documents in the legal discovery process. This has come on so fast that it has displaced a large percentage of $35/hour paralegal assistants who did this job more slowly, less accurately, and at greater cost.
In fact, there’s been some speculation that the entire legal profession might be automated in this way. However a recent study concludes that only about 13% of legal work can be automated despite startups like Legal Zoom and Rocket Lawyer. The fact is that the activities performed by lawyers are extremely unstructured and therefore resistant to automation. This is likely also to be a general rule or restriction on how far AI can go. The outcome for the legal profession is probably more low cost basic services which will bring legal access to under-served portions of the population.
However, if you want a hopeful conclusion to this conversation and the impact of AI on consumers look no further than Baidu, the Chinese tech giant and their prototype device called DuLight that literally allows the blind to see. The device wraps around the ear and connects by cable to a smart phone.
The device contains a tiny camera that captures whatever is in front of you—a person’s face, a street sign, a package of food—and sends the images to an app on your smartphone. The app analyzes the images, determines what they depict, and generates an audio description that’s heard through the earpiece. If you can’t see, you can at least get an idea of what’s in front of you.
This is a fully generalized perceptual system based on deep learning that points to a time, not far beyond 2016, when AI will allow users to perceive and understand their surroundings perhaps even better than their native senses allow.
So 2016 may be a little early to declare victory but there are strong examples in the works. Self-driving cars, content recognition and summarization, and systems to enhance our perception of our surroundings. Can jet packs and flying cars be far behind?
January 6, 2016
About the author: Bill Vorhies is Editorial Director for Data Science Central and has practiced as a data scientist and commercial predictive modeler since 2001. He can be reached at:
{kind=link}