
In recent years, the field of object detection has seen tremendous progress, aided by the advent of deep learning. Object detection is the task of identifying objects in an image and drawing bounding boxes around them, i.e. localizing them. It’s a very important problem in computer vision due its numerous applications from self-driving cars to security and tracking.
Prior approaches of object detection have generally proposed pipelines that are separate stages in a sequence. This causes a disconnect between what each stage accomplishes and the final objective, which is drawing a tight bounding box around the objects in an image. An end-to-end framework that optimizes the detection error in a joint fashion would be a better solution, not just to train the model for better accuracy but to also improve detection speed.
This is where the You Only Look Once (or YOLO) approach comes into play.
Deep learning has proven to be a powerful tool for image classification, achieving human level capability on this task. Earlier detection approaches leveraged this power to transform the problem of object detection to one of classification, which is recognizing what category of objects the image belonged to.
The way this was done was via a 2-stage process:
- The first stage involved generating tens of thousands of proposals. They are nothing but specific rectangular areas on the image also known as bounding boxes, of what the system believed to be object-like things in the image. The bounding box proposal could either be around an actual object in an image or not, and filtering this out was the objective of the second stage.
- In the second stage, an image classifier would classify the sub-image inside the bounding box proposal, and the classifier would say if it was of a particular object type or simply a non-object or background.
While immensely accurate, this 2-step process suffered from certain flaws such as efficiency, due to the immense number of proposals being generated, and a lack of joint optimization over both proposal generation and classification. This leads to each stage not truly understanding the bigger picture, instead being siloed to their own mini-problem and thus limiting their performance.
What YOLO is all about
This is where YOLO comes in. YOLO, which stands for You Only Look Once, is a deep learning based object detection algorithm developed by Joseph Redmon and Ali Farhadi at the University of Washington in 2016.
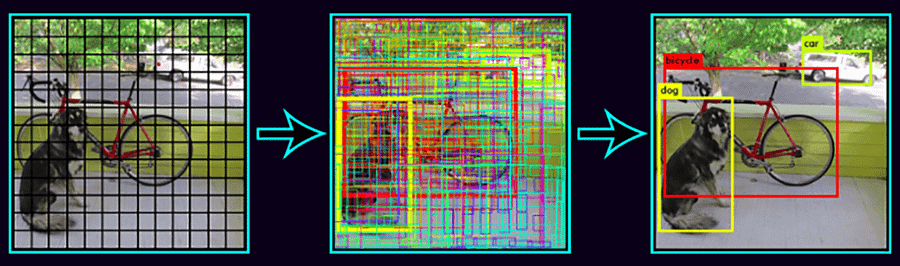
The rationale behind calling the system YOLO is that rather than pass in multiple subimages of potential objects, you only passed in the whole image to the deep learning system once. Then, you would get all the bounding boxes as well as the object category classifications in one go. This is the fundamental design decision of YOLO and is what makes it a refreshing new perspective on the task of object detection.
The way YOLO works is that it subdivides the image into an NxN grid, or more specifically in the original paper a 7×7 grid. Each grid cell, also known as an anchor, represents a classifier which is responsible for generating K bounding boxes around potential objects whose ground truth center falls within that grid cell (K is 2 in the paper) and classifying it as the correct object.
Note that the bounding box is not restricted to be within the grid cell, it can expand within the boundaries of the image to accommodate the object it believes it is responsible to detect. This means that in the current version of YOLO, the system generates 98 bounding boxes of varying sizes to accommodate the various objects in the scene.
Performance and Results
For more dense object detection, a user could set K or N to a higher number based on their needs. However, with the current configuration, we have a system that is able to output a large number of bounding boxes around objects as well as classify them into one of various object categories, based on the spatial layout of the image.
This is done in a single pass through the image at inference time. Thus, the joint detection and classification leads to better optimization of the learning objective (the loss function) as well as real-time performance.
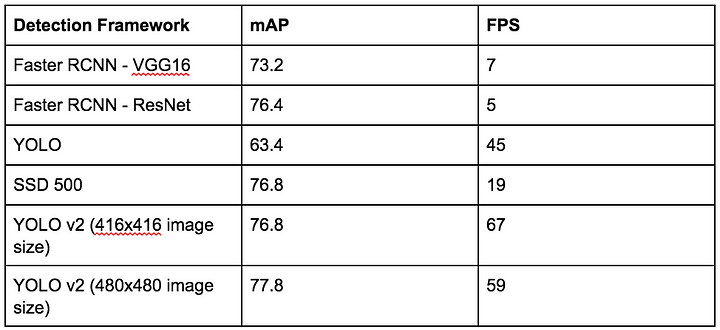
Indeed, the results of YOLO are very promising. On the challenging Pascal VOC detection challenge dataset, YOLO manages to achieve a mean average precision, or mAP, of 63.4 (out of 100) while running at 45 frames per second. In comparison, the state of the art model, Faster R-CNN VGG 16 achieves an mAP of 73.2, but only runs at a maximum 7 frames per second, a 6x decrease in efficiency.
You can see comparisons of YOLO to other detection frameworks in the table below.
If one lets YOLO sacrifice some more accuracy, it can run at 155 frames per second, though only at an mAP of 52.7.
Thus, the main selling point for YOLO is its promise of good performance in object detection at real-time speeds. That allows its use in systems such as robots, self-driving cars, and drones, where being time critical is of the utmost importance.
YOLOv2 framework
Recently, the same group of researchers have released the new YOLOv2 framework, which leverages recent results in a deep learning network design to build a more efficient network, as well as use the anchor boxes idea from Faster-RCNN to ease the learning problem for the network.

The result is a detection system which is even better, achieving state-of-the-art performance at 78.6 mAP on the Pascal VOC detection dataset, while other systems, such as the improved version of Faster-RCNN (Faster-RCNN ResNet) and SSD500,only achieve 76.4 mAP and 76.8 mAP on the same test dataset.
The key differentiator though is the performance speed. The best performing YOLOv2 model runs at 40 FPS compared to 5 FPS for Faster-RCNN ResNet.
Although SSD500 runs at 45 FPS, a lower resolution version of YOLOv2 with mAP 76.8 (the same as SSD500) runs at 67 FPS, thus showing us the high performance capabilities of YOLOv2 as a result of its design choices.
Final thoughts
In conclusion, YOLO has demonstrated significant performance gains while running at real-time performance, an important middle ground in the era of resource hungry deep learning algorithms. As we march on towards a more automation ready future, systems like YOLO and SSD500 are poised to usher in large strides of progress and enable the big AI dream.
This post originally appeared here.
{kind=link}