
Updated from original posted on April 17, 2014
The importance of metadata only continues to grow as organizations are realizing that to fully exploit the business and operational potential of machine learning, deep learning and artificial intelligence requires that the raw data be enhanced with metadata. And while we have growing volumes of actual data, there is even more data, or metadata, around the usage and source of the actual data.
Metadata is defined as a set of data that describes and gives information about other data. The phone call illustrates the insights that can be mined just from the metadata. Research from the Stanford University has shown that metadata of phone calls discloses a significant amount of personal information without accessing actual voice records. Graph analyses of phone call metadata can reveal frequency, recency, strength and the nature of relationships among people[1].
Let’s drill further into the analytic richness of metadata.
Tagging Lessons Learned from Web Analytics
Tagging is a concept with which most web analytics users are familiar. Tagging is a method of tracking visitor activity on each page of the website (see Figure 1).
Figure 1: Web analytics tagging process[2] (source for picture: Hosting Canada)
Source: https://en.wikipedia.org/wiki/Web_analytics
As each web page is requested, the web server returns the HTML page with the embedded JavaScript page code. The JavaScript page code sets the values for analytic data that you are collecting and calls functions and global variables in the JavaScript library file. The JavaScript code builds an image request for a 1×1 pixel image, also called a web beacon that concatenates a query string of name/value pairs of analytics data that is sent to a data center for reporting and analysis.
The advantages of tagging include:
- Data is gathered via a component (“tag”) in the page, usually written in JavaScript, Java or Flash.
- The script may have access to additional information on the web client or on the user, not sent in the query, such as visitors’ screen sizes and the price of the goods they purchased.
- Tagging can report on events that do not involve a request to the web server, such as interactions within Flash movies, partial form completion, mouse events such as onClick, onMouseOver, onFocus, onBlur, etc.
- The tagging service manages the process of assigning cookies to visitors.
There’s Gold in Them Thar Hills of Metadata!!
Sometimes it’s hard to imagine what metadata is and why it’s important. Let’s look at an example of the metadata associated with a 140-character tweet. 140 characters wouldn’t seem to be much data, even with a voluminous number of tweets. However, data volumes explode when you start coupling the tweet with all the metadata necessary to understand the 140-characters in context of the conversation (see Figure 2).
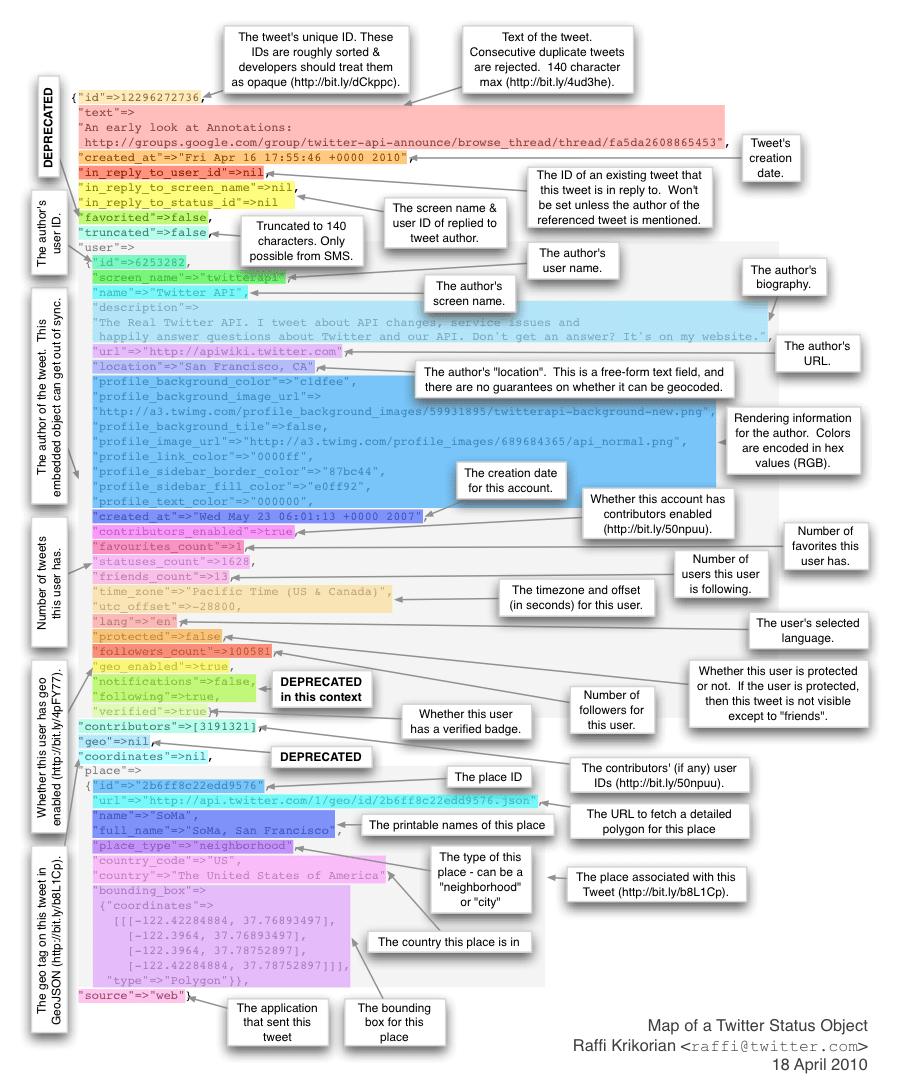
Figure 2: Metadata associated with a tweet
Here is some of the metadata associated with a 140-character tweet[3]:
- The screen name and user ID of the “replied to tweet” author
- Tweet’s creation date and time
- The author’s screen name
- The author’s user name
- The author’s biography
- The author’s URL
- The author’s location
- Rendering information for the author
- Account creation date
- Number of favorites this user has
- Number of users this user is following
- Time zone and offset for this user
- User’s selected language
- Where the user is protected or not
- Number of followers for this user
- Place ID
- Printable name for this place
- Type of place
- The country for this place
- The application that sent the tweet
It’s quick to see how the volume of metadata quickly dwarfs the amount of raw data, and this is what happens when organizations start tagging more of their transactions and interactions in order to gain additional insight into the nature and context of the dialogue and interaction.
Untapped Data Examples
Not all data is necessarily useful for Big Data analytics. However, some data types are particularly ripe for analysis, such as:
- Surveillance footage. Typically, generic metadata (date, time, location, etc.) is automatically attached to a video file. However, as IP cameras continue to proliferate, there is greater opportunity to embed more intelligence into the camera (on the edge) so that footage can be captured, analyzed, and tagged in real time. This type of tagging can expedite criminal investigations, enhance retail Big Data analytics for consumer traffic patterns, and improve military intelligence as videos from drones across multiple geographies are compared for pattern correlations, crowd emergence and response, or measuring the effectiveness of counterinsurgency.
- Embedded and medical devices. In the future, sensors of all types (including those that may be implanted into the body) will capture vital and non-vital biometrics, track medicine effectiveness; correlate bodily activity with health, monitor potential outbreaks of viruses, etc.—all in real time.
- Entertainment and social media. Trends based on crowds or massive groups of individuals can be a great source of Big Data to help bring to market the “next big thing,” help pick winners and losers in the stock market, and yes, even predict the outcome of elections—all based on information users freely publish through social outlets.
- Consumer images. We say a lot about ourselves when we post pictures of ourselves or our families/ friends. A picture used to be worth a thousand words, but the advent of Big Data has introduced a significant multiplier. The key will be the introduction of sophisticated tagging algorithms that can analyze images either in real time when pictures are taken or uploaded or en masse after they are aggregated from various websites.
These are in addition to the normal transactional data running through the enterprise systems in the course of normal data processing today.
Summary
An IDC study titled “Discover the Digital Universe of Opportunities” states that from 2013 to 2020, the digital universe will grow by a factor of 10x—from 4.4 trillion gigabytes to 44 trillion. However, the IDC study estimates that only 3% of the potentially useful data will be tagged.
Call this the Big Data gap: information that is untapped and waiting for enterprising digital explorers to extract the value hidden within it. The bad news is that this will take extra work and investment to tag all of these new data sources. The good news is that, as the digital universe expands, so does the amount of useful data it contains, and the invaluable insights about your customers, products, markets, and operations that can be used to optimize key business processes and uncover new monetization opportunities.
[1]Source: Eckerson Group “If Data is the New Oil, Metadata is the New Gold”
[2]Researcher9999 – Own work, CC BY-SA 4.0, https://commons.wikimedia.org/w/index.php?curid=44197627
[3]http://readwrite.com/2010/04/19/this_is_what_a_tweet_looks_like#awe…
{kind=link}