
This article will provide a high level understanding of effective ways to set up a data science function in 3 types of organisations: (1) Startups, (2) Medium Size Organisations, and (3) Large Organisations.
Most companies have realised that they need Data Science capabilities in order to stay competitive in their respective markets. In some cases, the products and insights generated from a Data Science (DS) team within an organisation is increasingly becoming their main differentiator.
Yet very few companies are getting this right.
The disconnect between what is needed by organisation and what a Data Scientist wants to work on has to do with the priorities of either side.
Most companies have a lot of “low hanging fruits” (data cleansing, simple queries, etc.) that don’t need complex data science models to be solved. However, most data scientists want to work on the most complex problems in the business.
Organisations need to clearly communicate why these low hanging fruits add value to the organisation quickly and Data Scientists need to understand that solving these problems will allow them to understand the business. Once they understand the business, a Data Scientist can play an instrumental role in maturing an organisation’s Data Science capability.
In order to get this right, 2 things are needed:
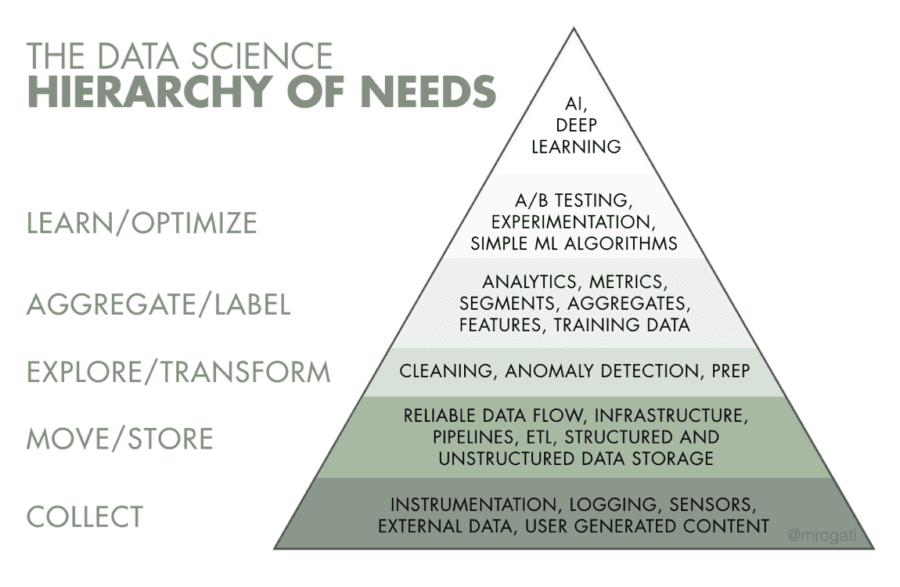
Source: Monica Rogati’s article on “The AI Hierarchy of Needs”
(i) Understanding “The Data Science Hierarchy of Needs” —
https://hackernoon.com/the-ai-hierarchy-of-needs-18f111fcc007
(ii) How to implement a team based on your organisation’s size.
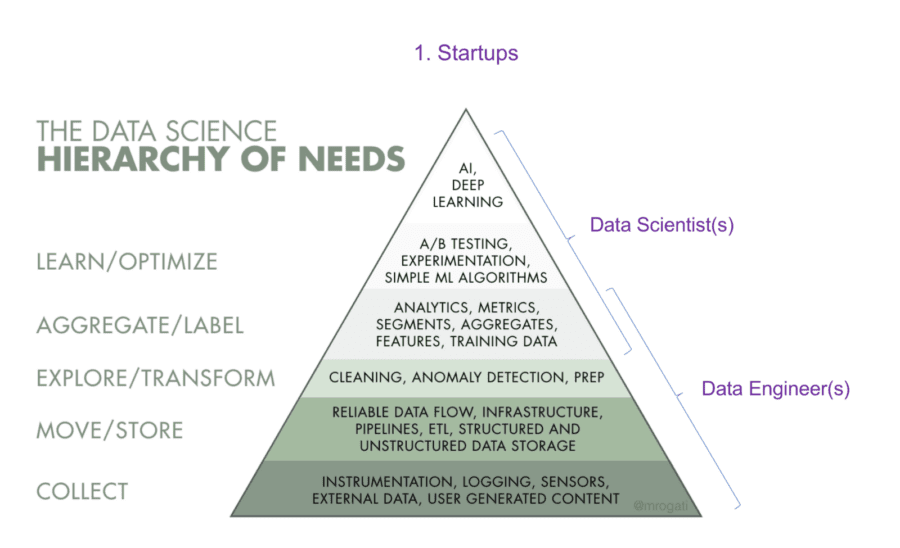
1. Startups:
In most startups, resources (time, £, and number of staff) are limited and at the same time your DS team has to be (1) responsible for setting up the entire data infrastructure as well as (2) generating the key insights needed to guide the organisation in the right direction.
For these 2 reasons, the most effective DS teams in startups have pairs of Data Scientists and Data Engineers working together. This allows both skillsets to play to their strengths and drive data products and insights forward.
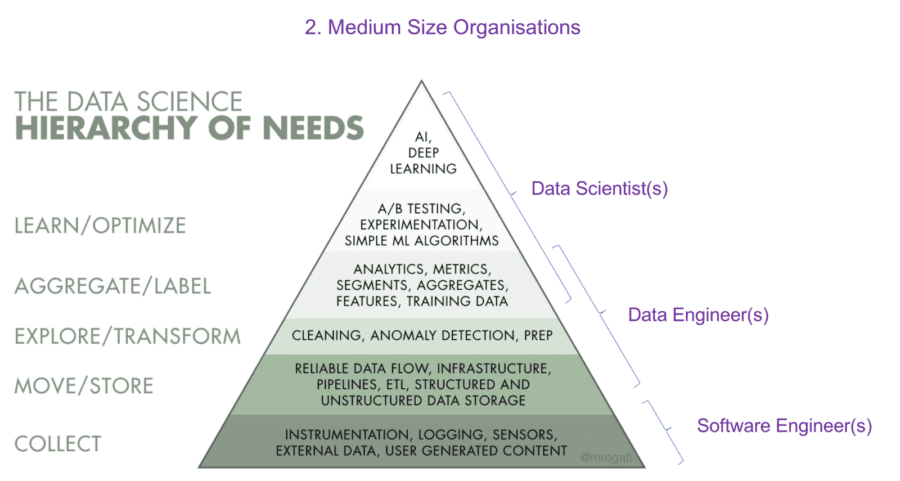
2. Medium Size Organisations
In medium size companies, resources that can be leveraged to create data products and insights are a little less scarce. This means they can separate the Data Scientists and Data Engineers. In some cases, a medium size company may also have Software Engineers that can be leveraged to take care of data collection and data acquisition.
This allows for a bit more separation based on skill set.
The key takeaway here is that the Data Engineers and Data Scientists can focus on analytics and metrics that effectively tell the business how their product or offering is doing while still pushing the envelope of developing new complex models.
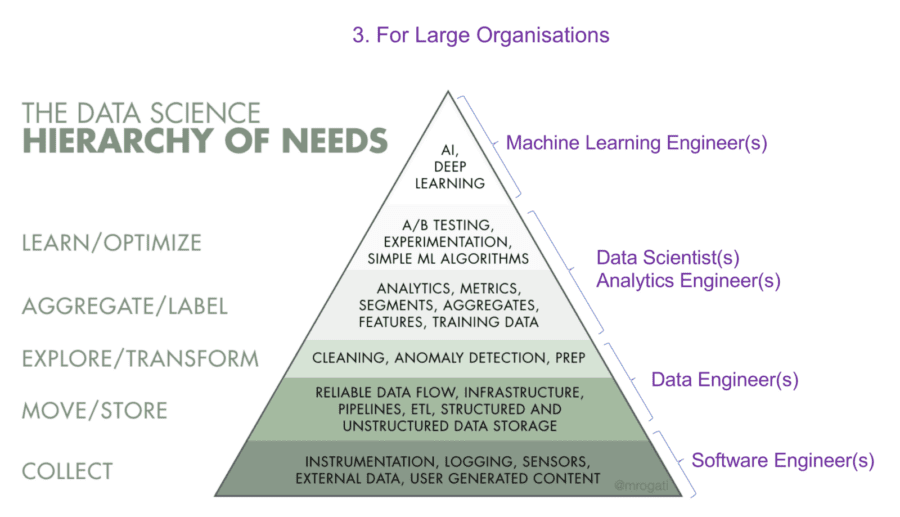
3. Large Organisations
When companies get large enough, they start to spend money on their employees. This allows for two things: (1) employees don’t have to worry about things outside of their domain and (2) employees can focus on what they are best at with little distraction.
Similar to medium size organisations, in large organisation the Software Engineers take care of instrumentation, logging, etc. and Data Engineers are focused on the architecture of your data pipeline.
The separation now occurs among the different types of Data Scientists.
- Data Science, Analytics Engineers
These Data Scientists focus on:
(i) Taking large datasets and turning them into concrete conclusions and actionable insights.
(ii) Communicating complex topics to a diverse audience.
(iii) Thinking creatively to identify new opportunities that will guide the organisation in the right direction. - Data Science, Machine Learning Engineers
These Data Scientists focus on:
(i) Developing highly scalable tools that leverage rule based models.
(ii) Suggesting, collecting, and synthesising requirements to create effective roadmaps.
(iii) Coding deliverables in tandem with Engineering team.
(iii) Adopting standard machine learning methods to best exploit modern parallel environments.
It is still quite difficult to bridge the gap between what motivates Data Scientists and what organisations mean when they say they want a Data Scientist to join them.
Both sides having a think about the data science hierarchy of needs and how to best implement pairs where individuals are playing to their strengths will yield the best outcome out of a data science team.
In my next article, I will be discussing how pairing Product Designers and Data Scientists can lead to developing highly effective products.
{kind=link}