
 Artificial Intelligence (AI) and Machine Learning (ML) are already being leveraged for increased efficiency and greater success in public web data-gathering operations.
Artificial Intelligence (AI) and Machine Learning (ML) are already being leveraged for increased efficiency and greater success in public web data-gathering operations.
It’s not a secret that web scraping can be complex and challenging. Part of that challenge is the fact that much of the process consists of repetitive and time-consuming activities associated with:
- Data parsing
- Infrastructure management
- Proxy management
- Overcoming fingerprinting
- Rendering JavaScript-heavy websites at scale
Web scraping specialists need to be on point with the dynamic nature of the job. Nothing is static in the digital world — things are changing all the time. Applications that are able to “learn” as they do their job are part of the solution.
That’s where Artificial Intelligence (AI) and Machine Learning (ML) come into play. Recent innovations in web scraping are leveraging these technologies so that data specialists overcome these obstacles.
Let’s first define our terms
Clarifying terms associated with AI is useful — even for seasoned professionals in the industry. That’s because terms like “artificial intelligence”, “machine learning”, and “deep learning” tend to get thrown around interchangeably in popular media. AI, in particular, often gets misused.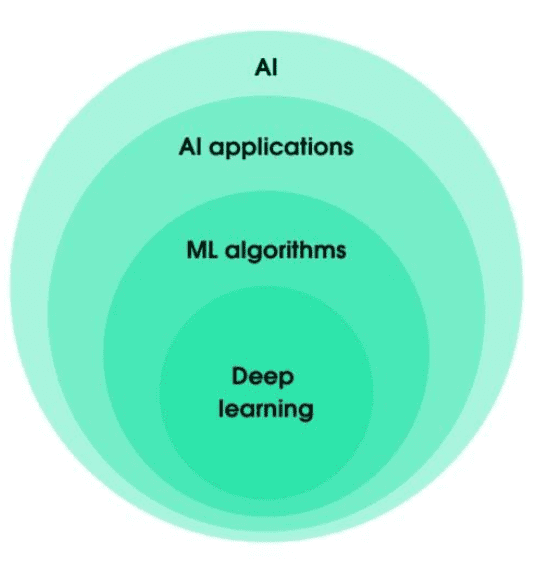
To start, AI is a general term that implies the capability of a machine or computer to learn something through its operation. Similar to human intelligence, the longer it operates the more it learns about its environment.
AI applications is a more appropriate term that can be used to describe how AI is being used for applications such as medical diagnosis, remote sensing and finance trading platforms.
Machine learning describes the algorithms being used by AI applications. Taking finance trading platforms as an example, this would include algorithmic trading software that detects patterns to guide buy and sell orders on the stock market.
Finally, deep learning is part of machine learning in the sense that it is based on artificial neural networks with representation or feature learning — the ability of a machine to learn features and use them to perform a specific task.
So when it comes to web scraping, the use of the term AI doesn’t cut it. Understanding the process means understanding that these algorithms can be put to work to understand how they can make the process more efficient and successful.
Web Scraping Challenges
Now let’s take this back to web scraping and data analysis. The process involves a set of tasks — sometimes time-consuming and tedious. They require governance and quality assurance, and the process becomes increasingly challenging as we scale up the process.
Let’s take a look at some of the big ones that could use some help from AI:
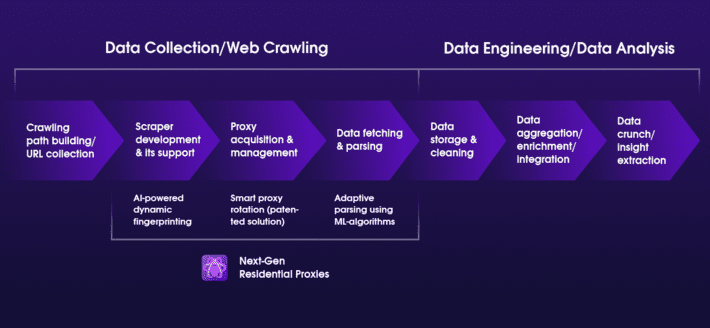
1. Crawling path building and URL collection
The first step in web scraping is to build a crawling path — a library of URLs from where the data will be extracted. It’s like a treasure map, but in this case we have hundreds of paths and multiple locations of treasure. To add to the challenge we aren’t quite sure which paths lead to treasure and which ones take us off a cliff.
Similar to the idea of paths, hundreds of these URLs (which technically are paths) need to be scraped, parsed, and identified. It’s a time and resource-intensive process, requiring “intelligence” to complete successfully.
2. Scraper development
Building a web scraper is challenging and requires many factors for consideration. These include items such as:
- Choosing languages, APIs, frameworks, etc.
- Scraper testing
- Maintenance and management of infrastructure
- Overcoming bot detection
- Rendering of JavaScript-heavy websites at scale
3. Proxy acquisition and management
Proxies are an essential part of the scraping process, requiring constant management and infrastructure maintenance. Many issues come into play, such as the possibility of errors after blocking proxy batches. Accordingly, proxy rotation is a good practice but doesn’t address all issues.
4. Data fetching and parsing
The data produced by scraping is not meaningful unless it’s parsed properly. This part of the process is particularly complex because parsers require maintenance and adaptation to different page formats.
All websites are different, and the formats change all the time. Keeping up with the dynamic nature of websites structures requires manual labour, time, and resources.
The solution to this issue — and all the others above — lies in the use of AI and ML to automate many tasks and conduct operations in an “intelligent” way.
Leveraging AI & ML for Web Scraping Automation
Since patterns repeat in web content, ML can learn to spot these patterns and extract the information. Part of the challenge is to uncover the general models found across various websites and developing the ability to scale up these solutions to accommodate realistic web scraping loads and pipelines.
ML-powered solutions can simplify the data gathering pipeline along with solving many issues related to proxy pool management, data parsing and other time-consuming and tedious tasks.
These solutions can enable developers to build highly scalable data extraction tools that empower data science teams to prototype rapidly. They can even act as a backup if their existing custom-built code was to ever break.
Next-Generation Solution
At Oxylabs, we’ve built Next-Gen Residential Proxies, and they are quickly gaining popularity amongst our business partners. Powered by the latest AI applications, they have been created for large-scale, heavy-duty data retrieval operations using a patented proxy rotation system.
Our solution support custom headers and IP stickiness along with reusable cookies and POST requests. Most interestingly, they also feature AI-Powered Dynamic Fingerprinting and ML-based Adaptive Parser, in addition to an auto-retry system and JavaScript rendering — all of which generate higher success rates with less maintenance, delays and errors, further automating once a manual, time-consuming web scraping process.
Wrapping up
Data extraction used to be as simple as entering numbers into a spreadsheet. Web scraping revolutionized that process to produce massive loads of data that enabled insights that were previously impossible to uncover in the pre-digital world.
These innovations, however, came with their own set of challenges. AI applications leveraging machine learning are now revolutionizing the process. The latest advancements within the space leveraging this technology are destined to make large-scale web scraping operations future-proof.
{kind=link}