
Introduction
Technological progress and the development of infrastructure has increased the popularity of Big Data immensely. Businesses have started to realize that data can be used to accurately predict the needs of customers which can increase profits significantly. The growing use of Big Data can be assessed from Forrester’s prediction of the global Big Data market to grow 14% this year.
Even though more n more individuals are entering this field, yet 41% of organisations face challenges due to lack of talent to implement Big Data as surveyed by Accenture. Users begin Big Data projects thinking it will be easy but discover that there is a lot to learn about data. It shows the need for good talent in the Big Data market.
According to a Qubole report of 2018, 83% of data professionals said that it’s very difficult to find big data professionals with necessary skills and experience and 75% said that they face headcount shortfall of professionals who can deliver big data value.
Qubole report found Spark is the most popular big data framework used in the enterprises. So if you want to enter Big Data market, learning Spark has become more like a necessity. If Big Data is a movie, Spark is its protagonist.
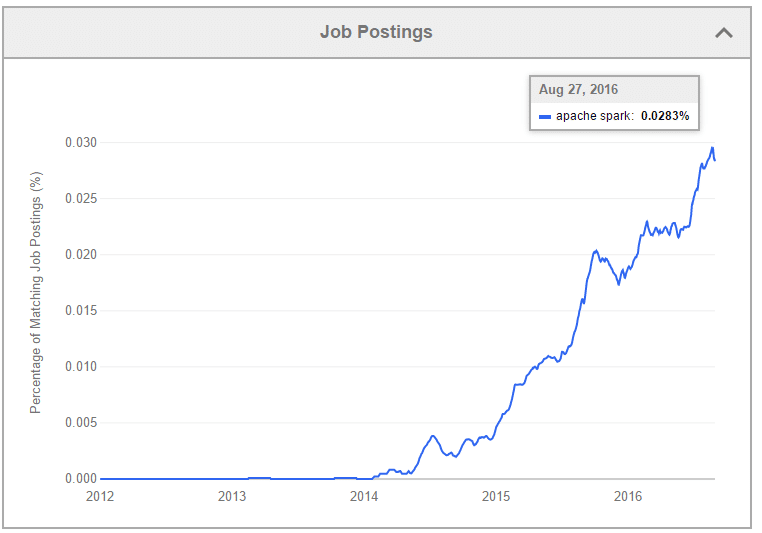
source: Edureka
Why Spark?
Spark is a leading platform for large scale SQL, batch processing, stream processing and machine learning.
An O’Reilly survey suggests that learning Spark could have more impact on salary than getting a PhD. It found strong correlations between those who used Apache Spark and those who were paid more.
Many organisations use Apache Spark for business intelligence and advanced analytics. Yahoo is using Apache Spark to offer more personalized content to the visitors. MTV and Nickelodeon use real-time big data analytics using Spark to improve customer experience. More and more businesses in India are shifting focus and resources to Big Data, it is certain that Big Data has a bright future.
Spark is being used for financial services by banks to recommend new financial products. It helps banks to analyse social media profiles, emails, call recordings for target advertising and customer segmentation. It is used in investment banking to analyse stock prices to predict future trends. It is being used in the healthcare industry to analyse patient records along with their past clinical data to assess their health risks. It is also used in manufacturing for large dataset analysis and retail industry to attract customers through personalized services. Many other industries like travel, e-commerce, media and entertainment are also using Spark to analyse large scale data to make better business decisions.
A major advantage of using Spark is it’s easy to use API for large scale data processing.
Spark’s API supports programming languages like Java, Python, R, and Scala. Many individuals are not from a coding background, in such a case, a simple programming language like python makes Spark user-friendly.
Spark in the Job Market
Linkedin’s top emerging jobs in India, according to its 2018 report, is topped by Machine Learning which mentions Big Data as its key skill. Big Data and Data Science jobs are one of the top 10 growing jobs in India.

Source: LinkedIn
At least 3 out of these 10 fastest growing jobs require Big Data as a key skill. Spark is one of the most well-known and implemented Big Data processing frameworks makes it crucial in the job market.
In US, Machine Learning is the second most growing job and requires Apache Spark as a key skill.

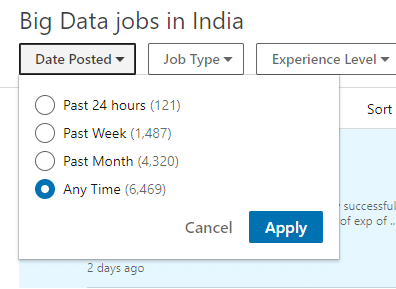
When you search for Big Data jobs in India on LinkedIn, you will find almost all companies have mentioned Spark as a requirement. There are close to 6500 jobs for Big Data on LinkedIn.
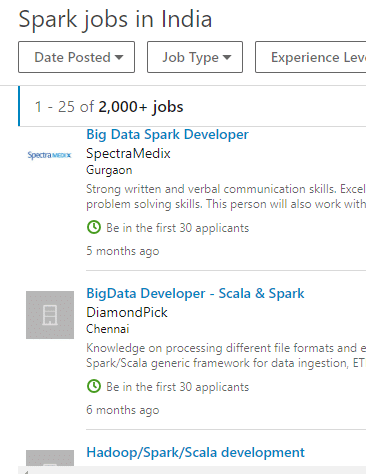
In fact, more than 2700 jobs on LinkedIn have exclusively mentioned Spark in the job profiles.
Demand for Apache Spark professionals is even higher in US, with more than 42k job listings, exclusively for Spark, on LinkedIn.
Talking about salary, on average, Big Data professionals in non-managerial role make Rs. 8.5 lacs per annum. People with specialized skill sets in Big Data earn even further and can go from 12 to 14 lacs. Freshers with a master’s degree in Big Data and analytics ranges between 4 to 10 lacs per annum, while for experienced professionals, it can go between 10 to 30 lacs per annum. IT professionals with over 10 years of experience get Big Data analytics salary of up to 1 crore.
If along with Big Data, an individual possesses Machine Learning skills, the annual salary could go up by 4 lac. Imagine if you are proficient in Spark’s other components as well, then you have much more to offer to an organization.
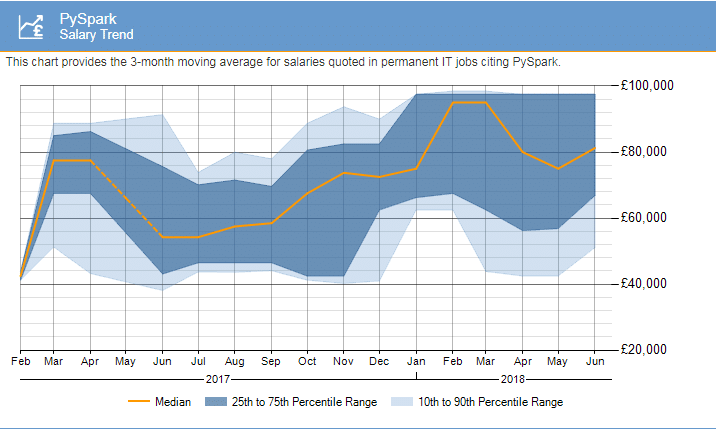
source: Dataflair
In United States, the average salary for Big Data ranges from approximately $68,242 per year for Data Analyst to $141,819 per year for a software architect.
Whereas, the average salary for Spark related jobs in U.S., as per Indeed, ranges from approximately $97,915 for the developer to $143,786 per year for Machine Learning Engineer.
Why Spark is in Demand?
Unified Analytics Engine: The growing demand for Spark professionals lies in the fact that it comes with high-level libraries which enable teams to run multiple workloads with a single engine. The tasks that had to be performed in a series of separate frameworks can be performed by Spark alone. It supports the following functionalities –
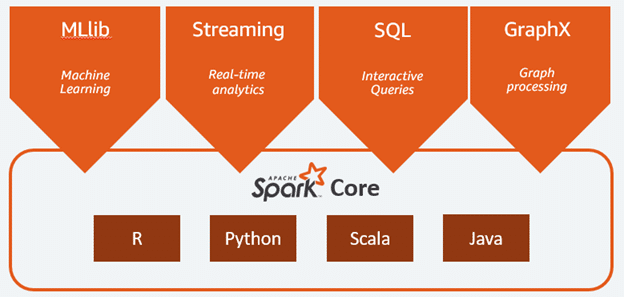 Source: Amazon AWS
Source: Amazon AWS- Spark Core: It is the fundamental unit of Spark containing the basic functionalities like in-memory computation, fault tolerance and task scheduling. It can deal with unstructured data like streams of text.
- Spark Streaming: It enables the processing of live data streams. This data may come from multiple sources and has to be processed as n when it arrives. It supports data from Twitter, Kafka, Flume, HDFS, and many other systems.
Spark streaming has the capability to handle streaming and analyzing enormous amounts of data in real time on a daily basis.
Companies like Uber use Spark Streaming for carrying complex analytics in real time.
- Spark SQL: It is a distributed query engine that queries the data up to 100x faster than MapReduce. It is used to execute SQL queries. Data is represented as Dataframe/Dataset in Spark SQL.
- Spark MLlib: It is Spark’s machine learning library. It provides tools such as ML Algorithms, Featurization, Pipelines, Persistence and Utilities like linear algebra and statistics. It supports both RDD based API and Dataframe/Dataset based API.
It enables Spark to be used for common big data functions like predictive intelligence, customer segmentation for marketing purposes and sentiment analysis. Given the growing demand for Machine learning profiles in both U.S. and India, and Spark MLlib being one of the leading platforms for machine learning, it becomes a key component in the job market.
- Spark GraphX: it is used for graphs and graph parallel computations. It includes a collection of graph algorithms and builders to simplify graph analytics.
Lightning Fast Speed: Spark can be 100 times faster than Hadoop MapReduce for large scale data processing as it is an in-memory processing framework. Spark performs faster than MapReduce even when it uses disk-based processing.
Interactive Analysis: Interactive analysis allows you to quickly explore data using visualizations. Spark has the capability to explore complex datasets fastly with interactive visualization. You can use Spark’s libraries to visualize streaming machine learning algorithms.
Hybrid Framework: It supports both batch processing and stream processing which gives organizations an advantage to handle both kinds of data processing simultaneously with less space and computational time.
Deployment: It can be run both by itself on standalone mode and over several other existing cluster managers like Hadoop YARN, making it suitable for just about any business. It can also be run locally on Windows or UNIX machine that can be used for development or testing.
Conclusion
Apache Spark alone is a very powerful tool. It is in high demand in the job market. If integrated with other tools of Big Data, it makes a strong portfolio.
Today, Big Data market is booming and many individuals are making use of it. It is wiser to pull your socks up and make use of the opportunity.
To Learn more about Big Data, Click to read Big Data Blog.
{kind=link}