
Summary: This new study claims to be able to identify criminals based on their facial characteristics. Even if the data science is good has AI pushed too far into areas of societal taboos? This isn’t the first time data science has been restricted in favor of social goals, but this study may be a trip wire that starts a long and difficult discussion about the role of AI.
Has AI gone too far? This might seem like a nonsensical question to data scientists who strive every day to expand the capabilities of AI until you read the headlines created by this just released peer reviewed scientific paper: Automated Inference on Criminality Using Face Images (Xiaolin Wu, McMaster Univ. and Xi Zhang, Shanghai Jiao Tong Univ. Nov. 21, 2016).
That’s right, shades of The Minority Report (movie in which criminals are arrested before the crime occurs) and the 19th century studies of phrenology. These researchers claim 89.51% accuracy in making this classification on several sets of unlabeled validation images, each of about 1,500 facial images.

I hope this has really taken your breath away. What does this mean for the future of facial recognition?
Like the Minority Report, do we incarcerate before the crime occurs?
Does this mean that the foundations of AI are broken in some way?
First About the Data Science
There is no good news or bad news here. The data science and techniques utilized appear sound. To correctly reflect the rigor of this experiment we quote these excerpts directly from the published paper:
In order to conduct our experiments and draw conclusions with strict control of variables, we collected 1856 ID photos that satisfy the following criteria: Chinese, male, between ages of 18 and 55, no facial hair, no facial scars or other markings, and denote this data set by S. Set S is divided into two subsets Sn and Sc for non-criminals and criminals, respectively. Subset Sn contains ID photos of 1126 non-criminals that are acquired from Internet using the web spider tool; they are from a wide gamut of professions and social status, including waiters, construction workers, taxi and truck drivers, real estate agents, doctors, lawyers and professors; roughly half of the individuals in subset Sn have university degrees. Subset Sc contains ID photos of 730 criminals, of which 330 are published as wanted suspects by the ministry of public security of China and by the departments of public security for the provinces of Guangdong, Jiangsu, Liaoning, etc.; the others are provided by a city police department in China under a confidentiality agreement. We stress that the criminal face images in Sc are normal ID photos not police mugshots. Out of the 730 criminals 235 committed violent crimes including murder, rape, assault, kidnap and robbery; the remaining 536 are convicted of non-violent crimes, such as theft, fraud, abuse of trust (corruption), forgery and racketeering.
Wu and Zhang then built four classifiers using supervised logistic regression, KNN, SVM, and CNNs with all four techniques returning strong results, the best by the CNN and SVM versions.
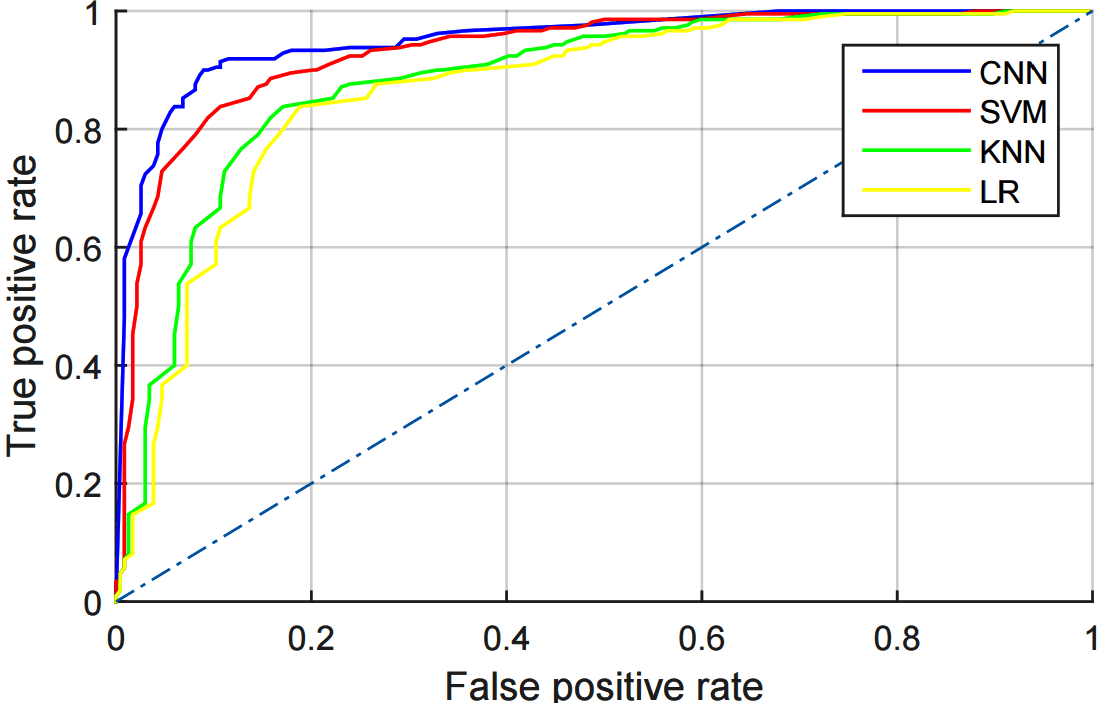
Since it is widely understood that CNNs can sometimes be deceived and may focus on factors not intended, the researchers also used the technique of introducing gaussian noise into the images with only about a 3% fall off in accuracy.
In summary, the study has been conducted with rigor. The results are what they are. Wu and Zhang make no comment on the implications of the study beyond the data science, but they really don’t need to.
The Implications of the Study
Both the general press and data scientists were quick to criticize the study results but not the techniques or competence of the researchers. Comments abound about the thoroughly debunked and historically much abused attempts to utilize physical profiling to categorize humans.
Some critics attempt to invalidate the study by implying that because our computers and software are created by humans they are susceptible to inherent bias. To me, blaming the math seems like a stretch.
It is possible that we are seeing some false correlation or false equivalence. Most critics focused on the similarity to the pseudo science of phrenology and particularly on the risk of societal abuse. However, none direclty challenge the rigor of the study. If there is a false equivalence here it will need to be conclusively demonstrated.
Implications for Advances in AI
It is remarkable how rapidly the applications of data science and also AI are finding there way into our everyday lives and that trend has become more obvious to the public given the major strides in AI of just the last two years. It’s difficult to open any thoughtful publication these days without seeing an article calling for ‘transparancy’ and ‘accountability’ of the data science that impacts us.
 It’s not new news that particularly banks and insurance companies have been politically and legally compelled not to use data that identifies us as members of protected groups (by sex, race, religion, and in some cases even location). These are societal issues which have already been placed as constraints on otherwise good science. Using these factors might in fact yield more accurate models and therefore more accurate business understanding of risk or pricing. Our legislators however have decided that these are worthwhile restrictions.
It’s not new news that particularly banks and insurance companies have been politically and legally compelled not to use data that identifies us as members of protected groups (by sex, race, religion, and in some cases even location). These are societal issues which have already been placed as constraints on otherwise good science. Using these factors might in fact yield more accurate models and therefore more accurate business understanding of risk or pricing. Our legislators however have decided that these are worthwhile restrictions.
However, a broader and more significant restriction is being called for. The public and the press widely call this ‘transparancy’ and ‘accountability’. As data scientists you will recognize this as ‘interpretability’.
As long as we have been preparing models of human behavior there has always been the tradeoff between accuracy and interpretability. Simple decision trees are easy to interpret, especially when they are significantly pruned. Linear regression is reasonably interpretable. But as our techniques have become more varied the most accurate of these, neural nets, ensembles, SVMs and others are not open to easy interpretation.
Yes even with these complex techniques we have access to interpretation through say input impact analysis. While this may satisfy the curiosity of your business sponsor it falls well short of being able to explain why customer X was favored or disfavored by your model’s score.
No Easy Answer
There is no easy answer to this issue. Straightforward scoring models or data science techniques embedded in AI bots are taking over both simple and complex decisions from all of us at an increasing rate.
On the more benign end, you could find reason to bemoan something as simple as our selection of reading being almost completely overtaken by recommenders. Critics might say this takes away the serendipity of discovering new authors and new content that only a certain amount of randomness enables. Many of us would say that recommenders have been a huge boon in guiding us to great and satisfying selections without the lost time and effort of random exploration.
On the more difficult end we are already equipping self driving cars that are only one step away from making such deep moral decisions as to have to choose between running over pedestrians or endangering the lives of the passengers (the trolley problem).
As drivers we don’t demonstrate any universal agreement on which moral solution is superior. When we program this into our self driving vehicles will we still be responsible or will we now have someone else to blame? And what happens if our legislators demand that the solution is to save the pedestrians. How will we feel about trusting a car designed to harm us in some situations?
Now that AI is here, there is no way to avoid these conversations. There are deep social and economic implications whether we are talking about surveilling people based on their facial characteristics or giving up certain techniques and types of data that results in deeply suboptimized decisions and economics in favor of some social goals.
As data scientists, the only option is to be aware and be engaged in this conversation.
About the author: Bill Vorhies is Editorial Director for Data Science Central and has practiced as a data scientist and commercial predictive modeler since 2001. He can be reached at:
{kind=link}