
What is NLP?
Natural Language Processing (NLP) can be simply defined as teaching an algorithm to read and analyze human (natural) languages just like the human brain does, but a lot faster than a human could, more accurately and on very large amounts of data.
It is a great skill to have if you are an aspiring data scientist or data analyst because has endless valuable applications in all industries. Examples of NLP applications include information discovery and retrieval for customer service, virtual assistance, content generation, medical diagnosis assistance, topic classification or topic modeling etc.
Topic modeling is what we will focus on in this article. It is used to classify data into categories of topic. Have you ever wondered how Google organizes news articles by topic or how certain emails are automatically flagged as spam? I can assure you that no one sits there to manually arrange millions of data and emails by topic. There are algorithms for that.
Who Should Read This Article?
In this article, I will walk through a simple code to build an accurate topic classification model. Beginner data analysts, data analysts with no experience in NLP or other data scientists who are curious to see other ways of approaching topic modeling will find this interesting.
Tools and Language
I will use the Structural Topic Model (STM) package in R for this example. STM is an unsupervised clustering package that uses document-level covariates. I have used it for many projects and it gives fantastic results with minimal training. You can read more about STM here. To be able to follow this example, you need to be somewhat familiar with R and RStudio.
Let’s get coding!
# Step 1: Get (natural) Data
For this example, I will be using text data (news articles) saved in .txt documents (remember that STM uses documents as data units). I scraped my data from open sources using Python’s BeautifulSoup (yes, I like Python better when it comes to scraping data).
If you do not know how to do that yet, don’t worry! You can copy-paste free text data online and save it as .txt files (make sure to read copyrights. Use only web data that is free to use). This is what my data looks like (I kept the data small for the sake of time):

I saved all of my .txt files in a folder named STM_trainingdata.
# Step 2: Ingest Data in RStudio
A rule of thumb is to write functions for tasks that you will repeat often. To ingest my data into RStudio, I wrote a simple function. Depending on the project that you are working on and the desired output, your function can have different inputs/outputs. Here is what mine looks like:
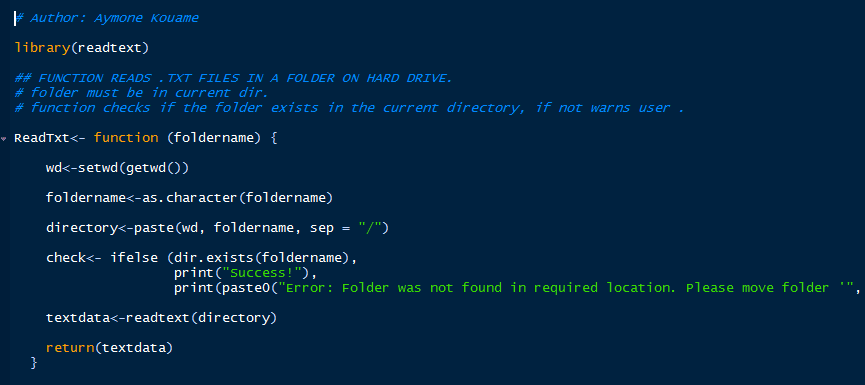
Now, call the function as shown below and you should get “SUCCESS!”:

Your data should look like this in RStudio:
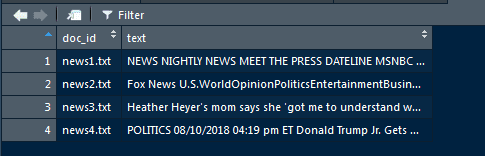
Now, every time I need to add/modify training data in my folder, all I have to do to update my data variable in RStudio is to call ReadTxt().
# Step 3: Pre-Process Your Data
Data pre-processing is one of the most important steps in any Machine Learning process. Poorly cleansed and/or structured data will yield poor results. You can use various statistical and visualization methods during data exploration to ensure that your data is ready.
Because our data sample is very small, I wrote a basic function to cleanse it. You can read inside the function the specific cleansing steps. A very important steps in NLP is to remove stopwords. You can read more about stopwords online.
The following function is very customizable. Depending on your training data, you may have more stopwords to remove. You can add them directly to the rem vector.
When writing functions, it is best practice to use descriptive names and add explanations about the inputs, outputs and processes.
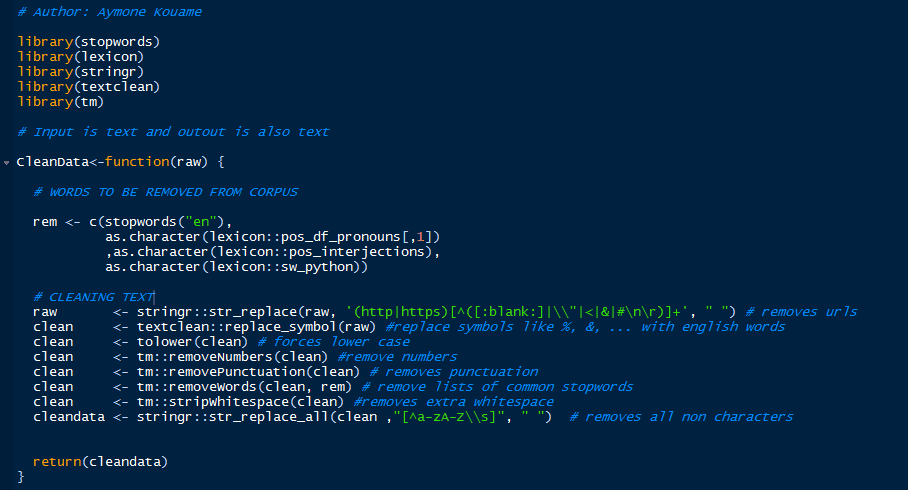
Next, call the function as follows:

Your clean data should look something like this:

At this point, you should have 4 items in your RStudio’s global environment: data, cleandata, ReadTxt() and CleanData() functions.
That’s it for Part 1! In Part 2, we will get into the interesting part: training and testing our STM model as well as some visualizations.
){kind=link}