
Summary: Analytic Platforms are rapidly being augmented with features previously reserved for data scientists. They are presented as easy to use but require substantial data literacy and advanced DS skills for the most complex. Business users and analysts can pursue more complex problems on their own, but need good oversight.
 Data Science Platform developers and Analytics Platform developers have been circling each other for years. The DSP folks see the analyst market presenting a much larger customer base. The ASP folks need to keep adding higher value features to maintain their shares. Gartner says these two ecosystems are swirling closer and closer like binary stars headed for collision.
Data Science Platform developers and Analytics Platform developers have been circling each other for years. The DSP folks see the analyst market presenting a much larger customer base. The ASP folks need to keep adding higher value features to maintain their shares. Gartner says these two ecosystems are swirling closer and closer like binary stars headed for collision.
In Gartner’s report “Augmented Analytics Is the Future of Analytics” published late last year they show the various elements that used to be unique to Data Science Platforms that are finding their way into Analytic Platforms.
The emphasis here is definitely on ‘Augmented’ as in fairly sophisticated features easy enough for a non-data scientist to use. Not all vendors of these augmented platforms provide the same features though Gartner proposes that they will rapidly converge.
Whether you’re a CXX exec in charge of this integration or a data scientists asked to participate there are some risks as well as advantages here.
Augmented Data Prep
No one would argue that data prep is the first link in both good data science and analytics. It’s also the biggest rub between IT where this has traditionally lived and users. Platforms that have focused on using AI/ML techniques to simplify this task include Paxata and Trifacta plus others with more comprehensive capabilities.
Cleaning the data and even converting categoricals is relatively straightforward. Combining and harmonizing multiple databases is another story.
Yes these platforms are able to do complex tasks like changing data roles (e.g. country or state to region, converting currencies, GIS groupings by your physical locations) and even spotting outliers. But when a business user attempts to make judgement calls about accepting a subset of the data because of missing data, or attempting to interpolate the missing values with AI/ML then the probability of bias or outright error become much greater. Not to mention fields in different databases with the same or similar names which actually have quite different interpretations (e.g. sales, gross and net margin), facts known only to those with deep understanding of the provenance of the data.
If the combination of data is well known to you and is simply taking lots of manpower to regularly extract and prepare then this can be a great time saver. If it’s combination of previously unexplored data, particularly external data, then a yellow flag should be raised.
Finding Patterns, Telling Stories
AI/ML augmentation is making substantial inroads into this bedrock of analytics. In analytics, where analysts and business users have traditionally built dashboards to show what they believe to be the strongest drivers of various KPIs like sales and margin, augmented feature selection and even presentation is showing some surprising wins.
Automated feature creation and selection, as well as model building are features of AML platforms that are finding their way into augmented BI platforms. There are several anecdotal examples in the Gartner report that describe the augmented platforms discovering key drivers that the analysts or business users had overlooked.
Beyond automating pattern discovery, we are rapidly moving out of the era of pictures into the era of NLP and NLG (natural language generation). That is platforms that can interpret and create analysis based on statements like:
“What are the top three ways I can improve sales this week in my territory?”
And just as important dynamically create not only a meaningful visual but also a NLG narrative to explain its conclusion. Here’s an example from Outlier.
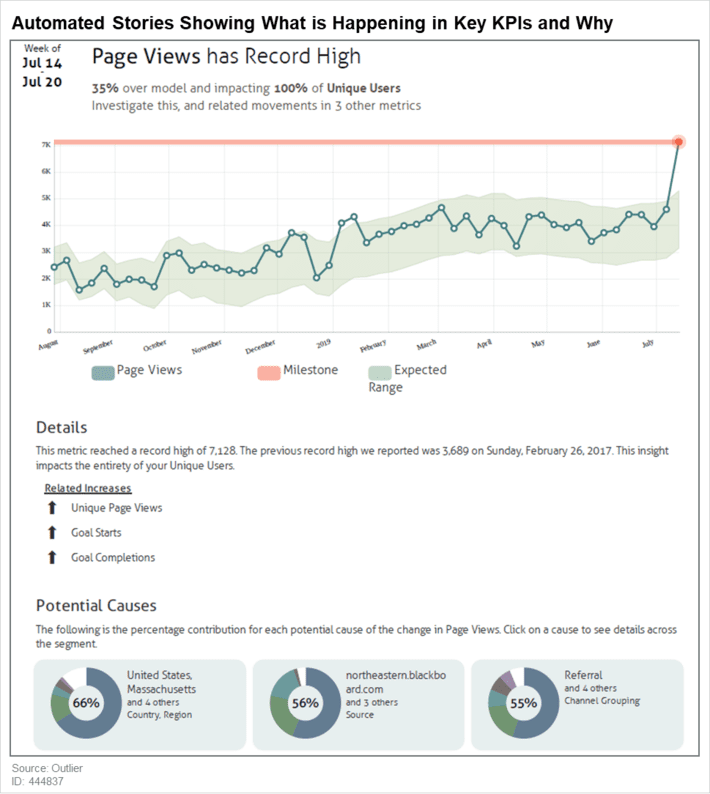
Automate Aspects of AI/ML Model Building
Finally at the most sophisticated and complex end of the augmentation are features that directly crossover into AI/ML model building. Here are combined the aspects of automated feature creation, feature selection, model selection, hyperparameter tuning, and storytelling.
As an example Gartner shows this dynamically created dashboard from the Aible platform using basic optimization to show the cost/benefit tradeoff between true and false positives combined with the operational constraints of resources, in this case the maximum number of customers that can be pursued with existing resources.
In the graphic, the analysis suggests two strategies that improve business (above the line) and several that do not.
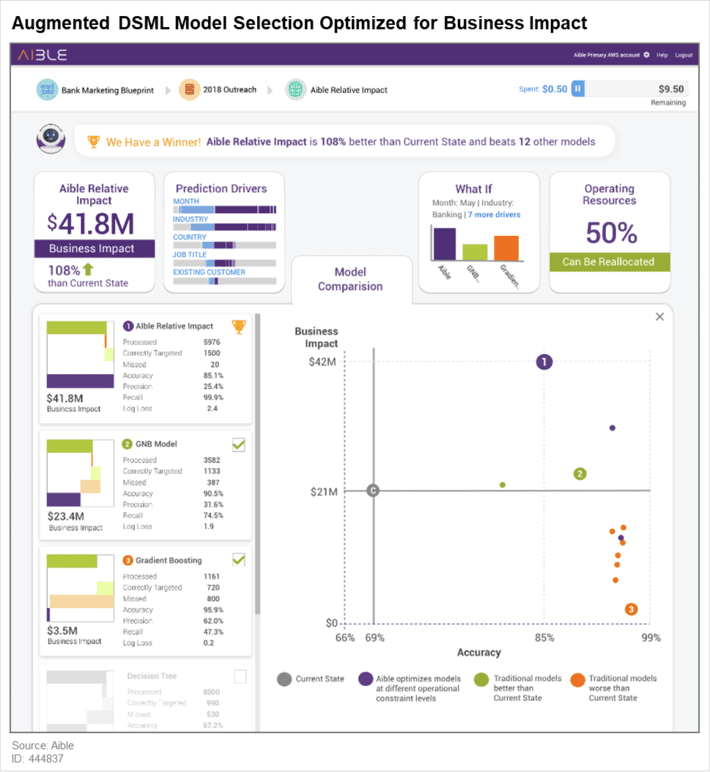
Risks and Constraints
When considering augmented BI platforms and features there are several things to keep in mind.
- Particularly at the top end of features like the Augmented AI/ML dashboarding above, the skill level required to successfully operate the platform is still likely to be constrained to data scientists or the most advanced analysts.
- Although these are billed as tools for the Citizen Data Scientist the learning curve can be long and the potential for a misguided business decision based on bad analysis is still substantial.
- For an enterprise wide push into augmented BI a very high level of data literacy is required for all users including those who are receiving the output and expected to act on it. That means focus on data literacy in hiring and in development of your existing workforce.
- Where these tools automate or enhance work you are currently doing for example in making standard data prep faster, good efficiencies can be had. When they are used with uncharted data or produce unexpected results caution is in order.
- With the most advanced Automated ML features, users are on safer ground sticking to proven algorithms versus the most advanced and complex techniques.
- Conversational interfaces for input and NLG output need to be thoroughly vetted during the vendor selection process and during use to ensure that all user inputs are in fact producing the same data outputs. There is still work to be done in NLP accuracy.
Other articles by Bill Vorhies
About the author: Bill is Contributing Editor for Data Science Central. Bill is also President & Chief Data Scientist at Data-Magnum and has practiced as a data scientist since 2001. His articles have been read more than 2.1 million times.
{kind=link}