
What is ETL?
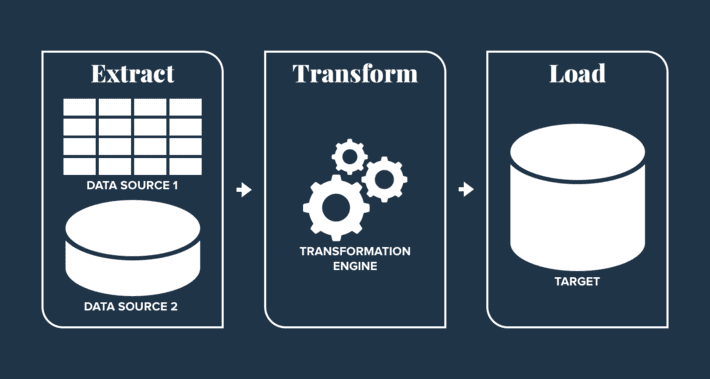
Put simply, an ETL pipeline is a tool for getting data from one place to another, usually from a data source to a warehouse. A data source can be anything from a directory on your computer to a webpage that hosts files. The process is typically done in three stages: Extract, Transform, and Load. The first stage, extract, retrieves the raw data from the source. The raw data is then transformed to match a predefined format. Finally, the load stage moves all that processed data into a data warehouse.
Challenges with ETL and variety
One of the greatest challenges that any data professional encounters is working with data variety. Variety is the degree to which data differs depending on where and how it’s generated. As a comparison, cars all serve the same basic function but can have huge differences in how they operate, look, and perform. With data, there’s an incredible number of variables from one dataset to the next.
For example, if you’re used to .csvs that format dates year-month-day and you encounter an .xlsx file that provides dates in year-day-month, you’re going to have to account for that if you want to blend these two dataset together. This kind of work, which we call prep and processing, is a crucial step, and accounts for a huge proportion of a data scientist’s time.
To ingest data from a given source into a warehouse, there’s two main challenges of variety that we have to deal with: data storage formats and data publishing standards. Data can be stored in many different formats (.csv, .xls, .xml…), which all have their own unique considerations. What’s more, we can’t assume that the format will stay static – systems get retooled, databases get restructured, old methods get deprecated.
Aside from the variety in data storage formats, data rarely conforms to a universal standard. To deal with these challenges in an enterprise organization, you will need technical workers to manage these changes, which is both costly and time-consuming.
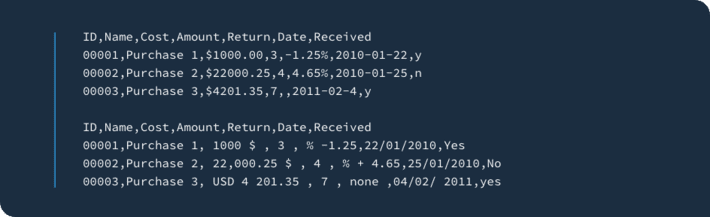
For example, let’s take a look at how two different sets of financial data are presented:
Common tools and handling variety
Spreadsheet processing has existed for quite some time, and remains important today. Excel is a very popular tool for this purpose, and is largely accessible to everyone. However, there are some shortcomings that prevent it from being a scalable solution. For starters, Excel is limited in the types of file formats it handles – it has certainly gotten better over the years, but it’s not without limitations. Furthermore, there are limits on the number of rows and columns it can open and process, and it’s unsuitable when users need to process anything larger than a modest file.
Another big issue is keeping data up to date.
When you open a file in Excel, it’s a static snapshot of the data. If it changes in any way after that moment, the information you’re using is no longer current.Finally, there’s no way to effectively collaborate on data and no single source of truth. As soon as data is shared from one person to another, that file is stale. New changes on one machine won’t carry over to another.OpenRefine is another useful tool – a standalone, open-source desktop application for data cleanup and transformation. However, it behaves more like a database than a spreadsheet processor. And, while OpenRefine is an excellent tool for restructuring data, the problem of scalability remains. If it takes an hour to transform a dataset into an ideal format, that’s not bad as a one-time cost. But if that dataset updates regularly, you might have to sacrifice a significant part of your work week to managing just one feed.
If data values change frequently (high velocity) but the structure is consistent (low variety), it’s relatively straightforward to set up a connector. Conversely, if the data has high variety but low velocity, a tool like OpenRefine works fine. But data in the real world updates and changes often and, chances are, tools like Excel and OpenRefine will only get you so far before they start to slow you down.
What’s the difference between ETL and data prep?
Both data preparation and ETL improve data’s usability. However, the ways in which this is accomplished are quite distinct. Data prep tools are more fine-grained, but require focus, time and specific knowledge. On the other hand, an ETL processes data as far as what can be automated with the end output being broad, high-level ideas that can be applied to lots of different things.
What’s the best fit for my business?
Like most things, it depends, and it’s entirely possible that you need both.A couple of questions you may want to ask:
How much data am I trying to process?Is there a common theme in the transformation I need to make?
- How often is the data updated?
- How large are the datasets I’m using?
Generally, if your organization deals with data that can have a broad set of common transformations applied, an ETL is your best fit, even if the data is updated frequently. That being said, your problem may not be so clear-cut, in which case a blend of both may be more suitable.
At ThinkDataWorks, we’re no strangers to data variety. Our tools have been trained on 250,000 datasets, the bulk of which are open, government data. If you’ve ever tried to connect to government data portals and ingest data from different sources, you know that it’s like snowflakes – no two are ever the same. Internally, we have crafted a blended solution to fit our needs: the automation power of an ETL solution, but with flexibility in how it processes incoming data.
Our ingestion pipeline looks at the incoming data and makes an educated guess at the information. Essentially, after a user provides a source, our solution obtains all the file formats, the underlying types of data (currencies, dates, text, geographical data, and so on), and all the necessary transformations. We’ve trained our pipeline on the world’s largest catalogue of open data, which is notoriously non-standard. As a result, it’s extremely good at deciphering the incoming data, and no extra configuration is needed (although, we’ve built that functionality in for special cases).
Takeaways
Both ETL pipelines and data prep tools are made to solve for data variety, but each has distinct advantages and drawbacks. Although automation can save time, it’s rare to find a perfect, catch-all solution. Coupling automation with the ability to manually review and augment data transformations has been a huge boost to our productivity, and makes the process of bringing data into a solution even faster. Before your organization adopts either of these tools, it’s critical to define your business and data strategies, and understand how they work in tandem. Consult with our experts today to get your organization on the path to more data with less overhead.
{kind=link}