
The power of deep learning paired with collaborative human intelligence to increase the quality of crop cultivation imagery through super resolution.
The Problem
The focus in this article lies in locating crop fields from satellite imagery, where it is conceivable that images of a certain quality are required to reach quality results. Although Deep Learning is notoriously known for being able to pull off miracles, we human beings will have a real field day labeling the data if we cannot clearly make out the details within an image.
The following is an example of what we would like to achieve.
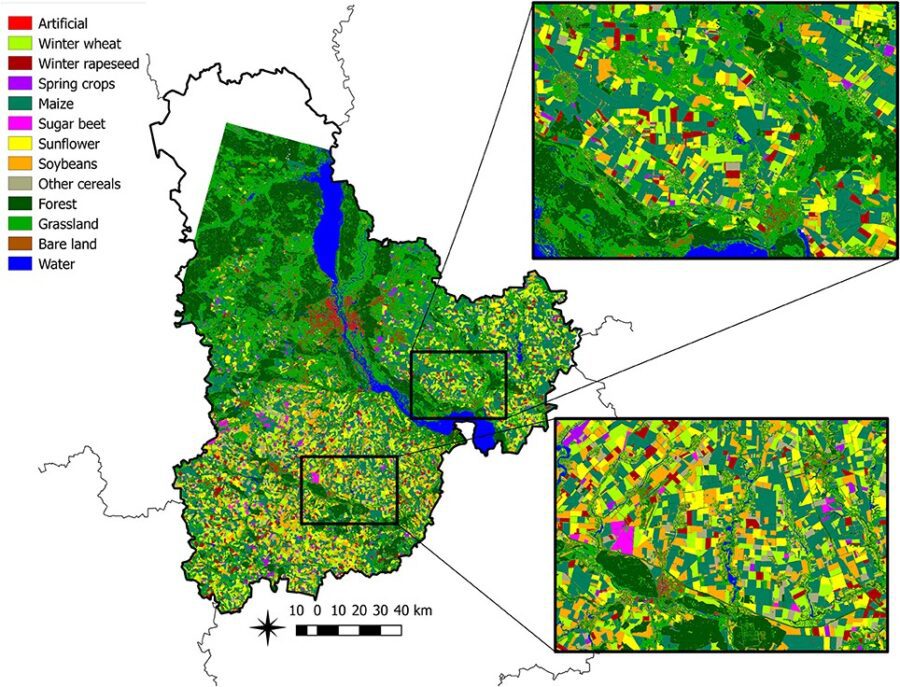
If we can clearly identify areas within a satellite image that correspond to a particular crop, we can easily extend our work to evaluate the area of cultivation of each crop, which will go a long way in ensuring food security.
The Solution
To get our hands on the required data, we explored a myriad of sources of satellite imagery. We ultimately settled on using images from Sentinel-2, largely due to the fact that the satellite mission boasts images of the best quality amongst other open-source images.
Is the best good enough?

Original Image
Despite my previous assertion that I am not an expert in satellite imagery, I believe that having seen the above image we can all agree that the quality of it is not quite up to scratch.
A real nightmare to label!
It is completely unfeasible to discern the demarcations between individual crop fields.
Of course, this isn’t completely unreasonable for open-source data. Satellite image vendors have to be especially careful when it comes to the distribution of such data due to privacy concerns.
How outrageous it would be if simply anyone can look up what our backyards look like on the Internet, right?
However, this inconvenience comes at a great detriment to our project. In order to clearly identify and label crops in an image that is relevant to us, we would require images of much higher quality than what we have.
Super-Resolution
Deep Learning practitioners love to apply what they know to solve the problems they face. You probably know where I am getting with this. If the quality of an image isn’t good enough, we try to enhance it of course! The process we like to call super-resolution.
This is one of the first things that we tried, and here are the results.

Results of applying Deep Image Prior to the original image.
Quite noticeably there has been some improvement, the model has done an amazing job of smoothening out the rough edges in the photo. The pixelation problem has been pretty much taken care of and everything blends in well.
However, in doing so the model has neglected finer details and that leads to an image that feels out of focus.
Decrappify
Naturally, we wouldn’t stop until we got something completely satisfactory, which led us to try this instead.

Results of applying Decrappify to the original image.
Now, it is quite obvious that this model has done something completely different than Deep Image Prior. Instead of attempting to ensure that the pixels blend in with each other, this model instead places great emphasis on refining each individual pixel. In doing so it neglects to consider how each pixel is actually related to its surrounding pixels.
Albeit being successful in injecting some life into the original image by making the colors more refined and attractive, the pixelation in the image remains an issue.
Next try

Results of running the original image through Deep Image Prior and then Decrappify.
When we first saw this, we couldn’t believe what we were watching. We have come such a long way from our original image! And to think that the approach taken to achieve such results was such a silly one.
Since each of the previous two models were no good individually, but they clearly were good at getting different things done, what if we combined the two of them?
So we ran the original image through Deep Image Prior, and subsequently fed the results of that through the Decrappify model, and voila!
Relative to the original image, the colors of the current image look incredibly realistic. The lucid demarcations of the crop fields will certainly come a long way in helping us label our data.
Our Methodology
The way we pulled this off was embarrassingly simple. We used Deep Image Prior which is found at its official Github repository. As for Decrappify, given our objectives, we figured that training it on satellite images would definitely help out. Having the two models readily set up, its just a matter of feeding images into them one after the other.
A Quick Look at the Models
For those of you that have made it this far and are curious about what the models actually are, here’s a brief overview of them.
Deep Image Prior
This method hardly conforms to conventional deep learning-based super-resolution approaches.
Typically, we would create a dataset of low and super-resolution image pairs, following which we train a model to map a low-resolution image to its high-resolution counterpart to increase crop cultivation. However, this particular model does none of the above, and as a result, does not have to be pre-trained prior to inference time. Instead, a randomly initialized deep neural network is trained on one particular image. That image could be one of your favorite sports stars, a picture of your pet, a painting that you like, or even random noise. Its task is then, to optimize its parameters to map the input image to the image that we are trying to super-resolve. In other words, we are training our network to overfit to our low-resolution image.
Why does this make sense?
It turns out that the structure of deep networks imposes a ‘naturalness prior’ over the generated image. Quite simply, this means that when overfitting/memorizing an image, deep networks prefer to learn the natural/smoother concepts first before moving on to the unnatural ones. That is to say that the convolutional neural network (CNN) will first ‘identify’ the colors that form shapes in various parts of the image and then proceed to materialize various textures in the image. As the optimization process goes on, CNN will latch on to finer details.
When generating an image, neural networks prefer natural-looking images as opposed to pixelated ones. Thus, we start the optimization process and allow it to continue to the point where it has captured most of the relevant details but has not learned any of the pixelations and noise. For super-resolution, we train it to a point such that the resulting image it creates closely resembles the original image when they are both downsampled. There exist multiple super-resolution images that could have produced each low-resolution image to increase crop cultivation.
And as it turns out, the most plausible image is also the one that doesn’t appear to be highly pixelated, this is because the structure of deep networks imposes a ‘naturalness prior’ on generated images.
We highly recommend a recent talk by Dmitry Ulyanov (who was the main author of the Deep Image Prior paper) to understand the above concepts in depth. Below you can follow the super-resolution process of Deep Image Prior.




The super-resolution process of Deep Image Prior
Super Resolution
Decrappify
In contrast with the previous model, here it is about to learn as much possible about satellite images. As a result, when we give it a low-quality image as an input, the model is able to bridge the gap between a low and high-quality version of it by using its knowledge of the world to fill in the blanks.
The model has a U-net architecture with a pre-trained ResNet backbone. The objective of this model is to produce an output image of higher quality, such that when it is fed through a pre-trained VGG16 model, it produces minimal ‘style’ and ‘content’ loss relative to the ground truth image. The ‘style’ loss is relevant because we want the model to be able to be careful in creating a super-resolution image with a texture that is realistic of a satellite image to increase crop cultivation. The ‘content’ loss is responsible for encouraging the model to recreate intricate details in its higher quality output.
Originally posted here.
{kind=link}