

- Your in-house data science team is not the exclusive source of AI/ML based improvements.
- Process Re-engineering is gaining new life as a way to optimize data processes.
- Increasingly AI/ML capabilities can be accessed with third party vendor packages.
- Intelligent automation platforms are also a source for optimization.
- Process re-engineering can open your AI tools to a broader audience.
As an industry we’ve spent a lot of the last three years trying to quantify the adoption of AI/ML. I’ve written about it here and several previous times. Most of the surveys conducted of large companies conclude that about one-third of companies are implementing AI/ML ‘at scale’. On the other hand the US Census Bureau’s recently released study reports about 9% adoption, but that includes a very long tail of very small companies with only a few employees.
Actually the measurement problem is much worse because we don’t know HOW MUCH adoption by any company. No doubt for these surveys if you’ve got one chatbot or one automated process or one propensity model that counts as adoption. It just doesn’t tell us anything important.
That’s the Wrong Question
I propose that the question is simply no longer relevant. First because the measurement of degree of adoption cannot be reasonably achieved. Second because AI/ML is now so fully integrated into the many third-party vendor packages we might buy that you probably utilize more AI/ML than you realize.
Up to this point we have largely associated AI/ML adoption with the hiring of data scientists and the creation of a corporate level initiative to build customized models. But the reality is that almost all of these custom models are used in acquiring new customers or serving existing customers via electronic channels.
If you rely on your ecommerce or web based channels to service or acquire customers then that’s where more than 90% of the focus of any in-house data science team will lie. Yes you can build customized in-house apps for other processes ranging from manufacturing and logistics to accounting and HR. But why?
History Repeats
Around 30 years ago when Thomas Davenport kicked off the era of reengineering, that movement started with a phase very similar to where we’ve been so far. You conducted process analysis and process reengineering then built expensive custom applications to utilize the newly available capabilities of automation via computers.
While the adoption of improved processes via computer automation continued on for more than a decade a host of developers brought us faster, better, cheaper packaged applications (think Oracle, SAP, or PeopleSoft ERP systems) that contained the best practices and capabilities and could be reasonably rapidly customized to a wide variety of customer situations. The same thing is happening today.
If you can utilize ML propensity or next best offer models, or need recommenders to capture new business then by and large those continue to need to be custom developed by your in-house data science team.
But it’s time to look beyond that, especially where the capabilities of image, text, and natural language processing based on deep neural nets might be useful. Particularly with these capabilities but also with some traditional ML apps your focus should be switching to vendor supplied apps.
Yes you will still need to carefully vet the capabilities of the app and the vendor but someone else’s data science team will be constantly focused on maintaining and upgrading them.
What Is Needed is a Return to Process Reengineering
Seems odd to say but process analysis and process reengineering are the skills you need to start with in-house to spot the opportunities for improvement.
Sometimes these needs will be strategically obvious. For example if your competitor can onboard a new customer in a few minutes while it’s taking you days. Or if the manpower required in your support processes of accounting or HR is much greater than your competitor. Or if it’s taking you days to approve commercial credit or process claims while your competitor does it in hours then it’s pretty obvious you’re in trouble.
But for systematic discovery of opportunities, process analysis and process reengineering are the right tools. The skills and principles involved in process reengineering haven’t changed much in the intervening years. The multiple skills required on the team and even the graphic notation of process diagrams is largely unchanged. Even identifying opportunities is based on largely the same set of rules like these from IBM.
- Waiting to obtain information from another source.
- Spending extra time finding information.
- Slowing down because of information that is in a form that cannot be used.
- Actions pending because of information processing by humans.
- Time spent finding, researching, and correcting an information-based error.
What Has Changed
What has changed is that the solutions available are now based on the capabilities of AI/ML which requires a user’s knowledge, but not an expert knowledge of data science.
Machine learning to predict or classify outcomes should be well known. Capabilities like speech and text recognition in chatbots is also intuitively obvious. What may be a little less obvious is the capability of machine vision to gather and interpret data from a wide variety of non-standard forms or other types of inputs and to apply rules or models against that data without human intervention.
In this last category we have all sorts of claims processing (from insurance to warranty), visual recognition and processing of objects (logistics, materials handling, inventory, and manufacture), recognition and validation of checks and credit devices, and much more.
Implementing that Change
Once your process reengineering team has identified the opportunity you may be able to immediately reach out to identify a third-party vendor application to address the issue. Implementing that outside application will no doubt come with a change in the process flow more or less built into or defined by the application.
However where the opportunity doesn’t warrant a full scale outside application a variety of process automation tools are now available many of which will embed or guide your use of the data science capabilities.
Forrester and Gartner both extensively review these packages and vendors. Forrester goes on to further divide the field into various scopes or depths of process reengineering that might be appropriate for different types or scales of opportunity.
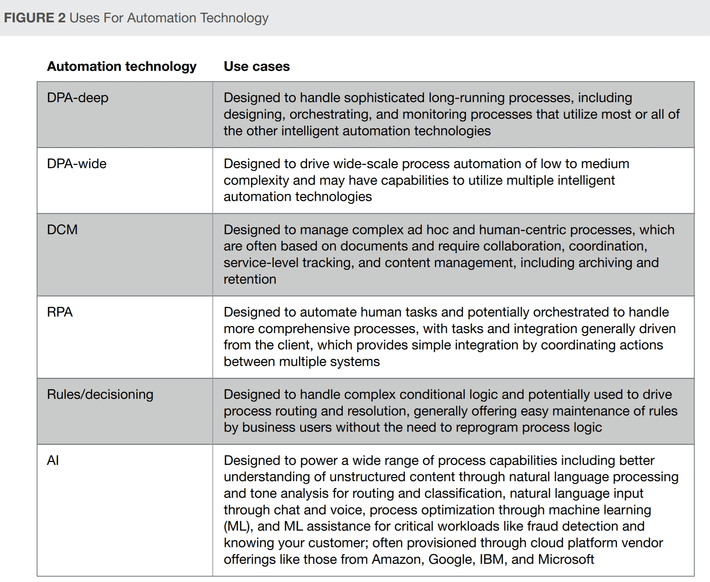
This chart is from Forrester’s report: Advance Process Automation By Keeping Automation Technologies In Their Own Lanes which can be found on line from various vendors.
The takeaway here is that the capabilities of AI/ML are no longer the exclusive domain of a bespoke in-house data science team.
There continue to be many cases where custom AI/ML models are needed for customer acquisition and customer service but increasingly all companies need to return to looking at their basic processes for improvement opportunities that incorporate AI/ML capabilities.
Other articles by Bill Vorhies.
About the author: Bill is Contributing Editor for Data Science Central. Bill is also President & Chief Data Scientist at Data-Magnum and has practiced as a data scientist since 2001. His articles have been read more than 2.5 million times.
{kind=link}