
- Cardiovascular diseases are the primary cause of global deaths.
- New model detects coronary heart disease with almost 99% accuracy.
- DNN with hidden layers shows more accuracy than other models.
According to the World Health Organization (WHO), cardiovascular diseases (CVDs) are the leading cause of death globally, killing 17.9 million people in 2019 [1]. The WHO risk models identified many different variables as risk factors for CVDs, including the key predictor variables: age, blood pressure, body mass index, cholesterol, and tobacco use. Historically, this potpourri of factors made CVDs almost impossible to predict with any meaningful accuracy. A new study by Kondeth Fathima and E. R. Vimina [2], published in Intelligent Sustainable Systems Proceedings of ICISS 2021, used Deep Neural Networks (DNNs) with four Hidden Layers (HDs) to predict CVDs with an impressive 99% accuracy.
What is a DNN with Hidden Layers?
Neural network models have come to the forefront in recent years, gaining popularity because of their exceptional prediction capabilities. Many different deep learning techniques have been developed, including Convolutional Neural Networks (CNNs) used extensively for object recognition and classificationand Long Short-Term Memory Units (LSTMs), widely used to detect anomalies in network traffic. This new study used a Deep Neural Network (DNN), known for their robustness to low and high data variations, generalizability to a wide range of applications, and scalability for additional data.
DNNs can be single- or multi-layered and are defined as an interconnected assembly of processing elements that act upon a function [2]. The additional computational layers in multi-layered DNNs are called Hidden Layers (HLs); HLs repeat a process through many cycles. A neural network model with hidden layers can handle increasingly complex information, making it an ideal choice for analyzing data with multiple featureslike data on cardiovascular disease. When modeling the intricacies of CVD risk-factors, more hidden layers give better results than one with fewer layers. The goal of the study was to find the DNN with the optimal number of hidden layersthe one giving the best accuracy for predicting cardiovascular disease.
Methodology
The study authors used two datasets from the University of California at Irvines machine learning repository [3], Statlog and Cleveland. Both of these data sets are known for their data source reliability. After using Exploratory Data Analysis on the data, the researchers chose the best model based on accuracy performance on the two datasets.
Three different neural network models were studied, each with a different number of layers and neurons. After experimenting with various numbers of hidden layers, the researchers chose one with one input layer (IL), four HLs, and one output layer (OL).
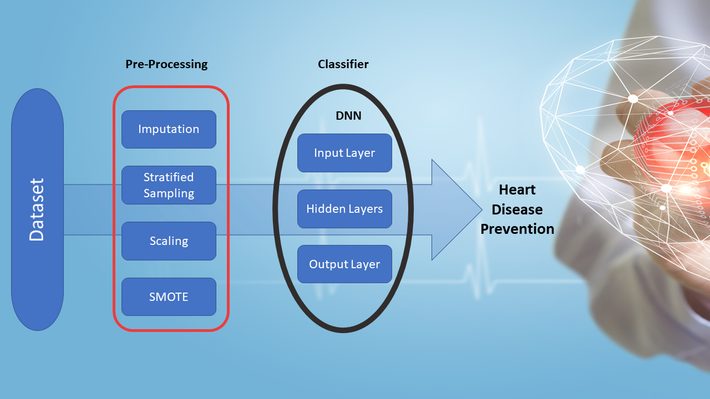
Synthetic Minority Oversampling Technique (SMOTE) increased and balanced the number of cases in the imbalanced dataset, which contained disproportionate cases of healthy and unhealthy cases. Mean imputation replaced the missing data, and the datasets were divided into a training set (70%) and testing set (30%) containing equal proportions of healthy and unhealthy cases. The weights of the 13 features were optimized using gradient descent in neural networks, and the data was scaled using standardization.
Results
Different metrics used for evaluating the models, including accuracy, sensitivity, specificity, F1 score, misclassification, ROC, and AUC. The result was a four-HL DNN that detected coronary heart diseases with promising results. The selected model gave accuracies of 98.77 on the Statlog dataset and 96.70 for the Cleveland dataset.
References
DNN Image (Top): Adobe Stock / Creative Cloud.
4-HL DNN Model by Author (Based on Kondeth Fathima and E. R. Viminas original Fig. 1). Background: Adobe Stock / Creative Cloud.
[1] Cardiovascular diseases (CVDs)
[2] Heart Disease Prediction Using Deep Neural Networks: A Novel Approach
{kind=link}