
Currently, many of us are overwhelmed with mighty power of Deep Learning. We start to forget about humble graphical models. CRF is not so trendy as LSTM, but it is robust, reliable and worth noting.
In this post, you will find a short summary about CRF (aka Conditional Random Fields) – what is this thing, what is it for and some interesting facts. Enjoy!
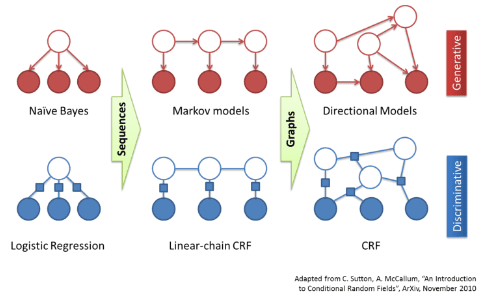
What is CRF?
- Conditional Random Fields is a discriminative undirected probabilistic graphical model, a sort of Markov random field.
- The most often used for NLP version of CRF is linear chain CRF
- CRF is a supervised learning method
How to use CRF for Natural Language Processing?
Linear chain CRF is good for different segmentation and sequence tagging tasks:
- Keywords extraction
- (Named) Entity Recognition
- Sentiment Analysis
- Part-of-Speech Tagging
- Speech Recognition
Complexity of CRF
The time complexity of the training process is large enough:

, where:
- m is the number of training iterations
- N is the number of training data sequences
T is the average length of training sequences - Q is the number of class labels
- n is the number of CRF features
- S is the searching time of the optimization algorithm (for example, L-BFGS algorithm, which is considered good for this).
In practical implementation, the computational time is often larger due to many other operations like numerical scaling, smoothing etc.
That’s sad.
The time complexity of the inference process is much better in case of using Viterbi algorithm for inference:

, where:
- T is the number of training data sequences
- S is the number of class labels
CRF vs. alike algorithms
- The most similar method for CRF is MEMM (Maximum-entropy Markov Model). It is also discriminative probabilistic graphical model. However, MEMM has so called “label bias problem” (see, for example, this link for details or this link). CRF has no such problem and this fact is the main difference between CRF and MEMM
- It is not correct to compare CRF and HMM in direct way, because both CRF and HMM relate to different classes of algorithms – HMM is generative model and CRF is discriminative model
Shortcomings of CRF
- The most evident disadvantage of CRF is high computational complexity of the training stage of the algorithm. This fact makes it more difficult to re-train the model when new training data samples become available.
- CRF does not work with unknown words, i.e. with words that were not present in training data sample
Advantages of CRF
- Many researches show that CRF is better for NER task than MEMM and HMM. That is why Stanford NER is based on CRF.
- It is possible to reach high quality of labeling (e.g. for NER task) if you choose right features
- CRF is flexible enough in terms of feature selection. In addition, it is not necessary for features to be conditionally independent
Python CRF libraries
There are not many of them.
I think, the most suitable is pyStruct.
Also, I can name CRFsuite, a fast implementation of Conditional Random Fields written in C++, but with a decent Python wrapper.
Examples of CRF usage
Keyword extraction
As CRF is supervised machine learning algorithm, you need to have large enough training sample to train it. If you have such sample, and if you choose features wisely, theoretically you may obtain the quality around 0.6-0.7 (F1-measure)
Unfortunately, researches show us that in reality it is hardly unlikely to have a quality higher than 0.5 (F1-measure). For example, some Indian researchers used CRF to extract key words from medical texts and they had good features and large enough training sample, but they obtained quality not more than 0.4 (F1-measure). That’s sad.
Named entity extraction
CRF is significantly better in coping with NER task
For example, researchers from HSE and SPSU presented a paper, where they obtained quality of NER about 0.9 (F-measure) on a test set, having a training set not more than 70 000 examples. On real data they would hardly obtain such quality, while Stanford NER shows quality not more than 0.81 (F-measure) given it has perfectly selected training features and it was trained on larger corpora (CoNLL, MUC-6, MUC-7 and ACE)
Some Spanish and Russian researchers compared HMM and CRF in NER task for medical texts on JNLPBA corpus (18546 sentences with 109588 named entities). They obtained interesting results: HMM had higher recall (+4-7% depending on the type of entity) while CRF had higher precision (+4-13% depending on the type of entity). Average F-measure on cross-validation appeared to be about 0.65 for HMM and 0.69 for CRF. The authors supposed, that the quality of NER could have been 5-10% higher if they used hybrid HMM+CRF algorithm.
Time expressions extraction
Yep, time expressions are also entities, but very specific ones, so I decided to write about them in a separate section.
According to one master thesis, linear-chain CRF operated very well on extracting time expressions from Russian text. The author manually tagged 2000 sentences (which contained about 500 time expressions) then iteratively tuned parameters and features until he obtained 0.93 (F1-measure) in cross-validation.
Sounds cool, but in real process I think there would be no more than 0.7-0.75 (F1-measure). That is also very decent, though.
Sentiment Analysis
CRF copes with this task very well. Different research papers (just google it!) claim the results of using CRF for sentiment analysis for various languages are good enough – about 0.7 (F1-measure).
For instance, the researchers from HSE claimed that they achieved 0.74 (F1-measure) while performing Sentiment Analysis on real Twitter messages. They manually tagged 20 000 messages and achieved average 0.86 (F1-measure) on all three possible types of sentiment (positive, negative and neutral).
By the way, neutral class is important for a good sentiment analysis (and my experience proves this). See, for example, this research about the importance of neutral calss in Sentiment An….
Summary
- CRF is not very good for keywords extraction as soon as it cannot handle unknown words. Moreover, adding new data to the training dataset forcers us to re-train the whole CRF model – and it may be quite time-consuming due to the high complexity of the training phase of the algorithm.
- CRF shows good performance when dealing with entity recognition (any types of entities, including named entities, time expressions, etc.). It can use both linguistic (characters, words) and non-linguistic information (upper/lower case, punctuation marks, spaces etc.). The achievable quality of entity recognition is about 0.7-0.85 (F1-measure), which is high.
- There is an interesting idea to make a hybrid algorithm by combining HMM and CRF for entity recognition. Theoretically, such algorithm could increase overall quality of entity recognition by 5-10% and reach 0.85-0.9.
- The links below this post may come in handy
References
General:
Wikipedia about CRF (http://en.wikipedia.org/wiki/Conditional_random_field)
Many formulas about CRF for formula-lovers
Yet another link about CRF and label bias
Publications:
Master thesis about using CRF to lable time expressions (in Russian)
Automatic Keyword Extraction from Documents Using Conditional Rando…
Effective Approaches For Extraction Of Keywords
CRF for Russian language (in Russian)
Conditional Random Fields vs. Hidden Markov Models in a biomedical …
Keyphrase Extraction in Scientific Articles: A Supervised Approach
:%20Short%20Survey){kind=link}