
Image source: Statistical Aid
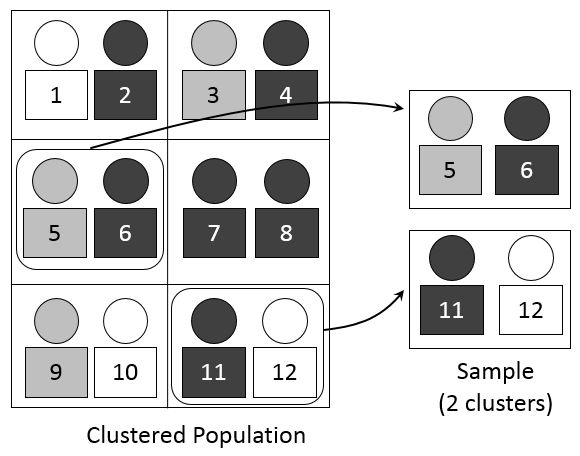
Cluster sampling is defined as a sampling method where multiple clusters of people are created from a population where they are indicative of homogenous characteristics and have an equal chance of being a part of the sample. In this sampling method, a simple random sample is created from the different clusters in the population. This is a probability sampling procedure.
Examples
Types of cluster sampling
There are three types as following,
Two-stage Cluster: In this process, first choose a cluster and then draw sample from the cluster using simple random sampling or other procedure. For example, A business owner wants to explore the performance of his/her plants that are spread across various parts of the U.S. The owner creates clusters of the plants. He/she then selects random samples from these clusters to conduct research.
Multistage Cluster: Few step added to two-stage then it is called multistage cluster sampling. For example, An organization intends to survey to analyze the performance of smartphones across Germany. They can divide the entire countrys population into cities (clusters) and select cities with the highest population and also filter those using mobile devices.
{kind=link}