
Overview
Call Detail Record (CDR) is the information captured by the telecom companies during Call, SMS, and Internet activity of a customer. This information provides greater insights about the customer’s needs when used with customer demographics. Most of the telecom companies use CDR information for fraud detection by clustering the user profiles, reducing customer churn by usage activity, and targeting the profitable customers by using RFM analysis.
In this blog, we will discuss about clustering of the customer activities for 24 hours by using unsupervised K-means clustering algorithm. It is used to understand segment of customers with respect to their usage by hours.
For example, customer segment with high activity may generate more revenue. Customer segment with high activity in the night hours might be fraud ones.
Data Description
A daily activity file from Dandelion API is used as a data source, where the file contains CDR records generated by the Telecom Italia cellular network over the city of Milano. The daily CDR activity file contains information for 10, 000 grids about SMS in and out, Call in and out, and Internet activity. The structure of the dataset is as follows:
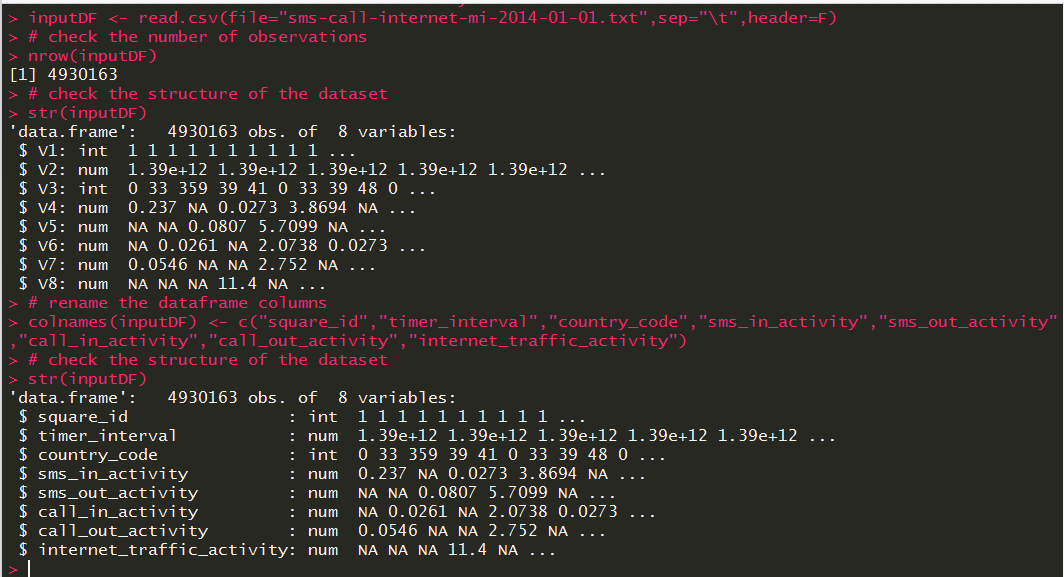
As it has five million records, a subset of the file containing activity information for 500 square IDs is used as a use case.
Data Source Features Description
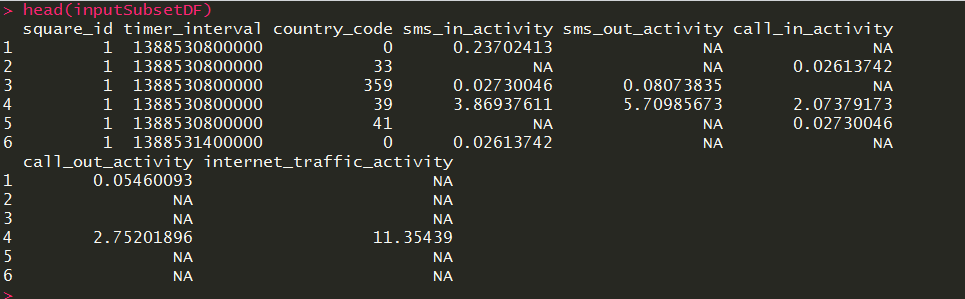
The actual dataset contains 8 numerical features about SMS in and out activity, call in and out activity, Internet traffic activity, square grid ID where the activity has happened, country code, and timestamp information about when the activity has been started.
Data Pre-processing
Data pre-processing involves data cleansing, data type conversion, and wrangling.
To pre-process data, perform the following steps:
- Convert the square ID and the county code into factor columns as part of type conversion.
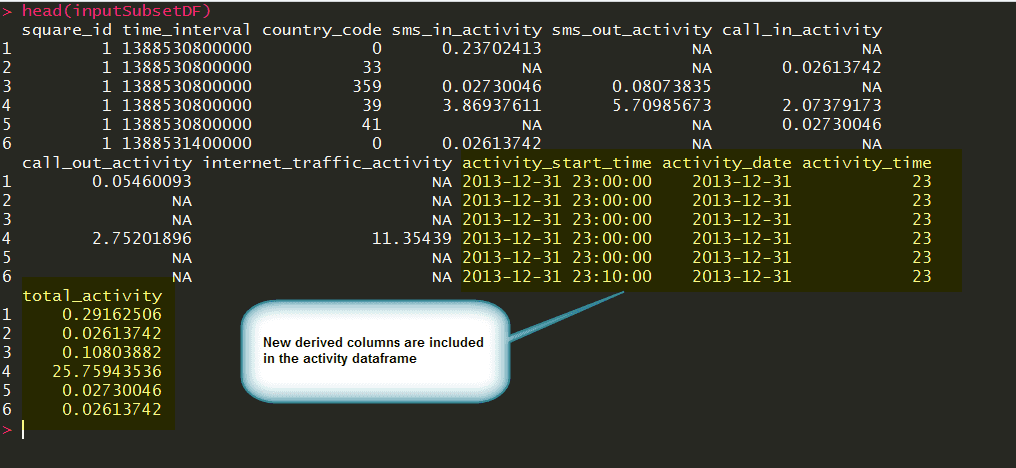
- Derive new fields such as “activity start date” and “activity hour” from “time interval” field.
- Find total activity, which is the sum of SMS in and out activity, call in and out activity, and Internet traffic activity.
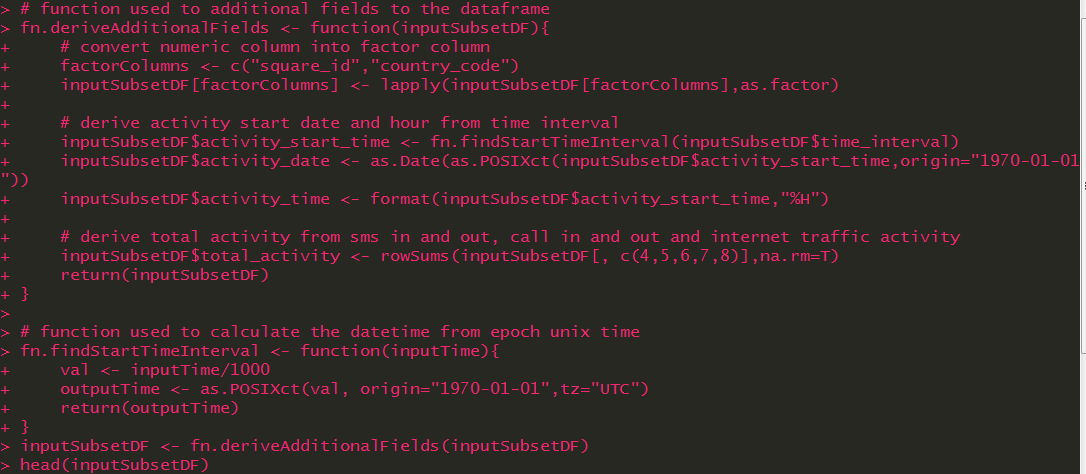
- Create new derived fields as mentioned above.
CDR Exploratory Data Analysis (EDA)
Exploratory Data Analysis is the process of analyzing the data visually. It involves outlier detection, anomaly detection, missing values detection, aggregating the values, and producing the meaningful insights.
The plot for “Total activity by activity hours” is as follows:
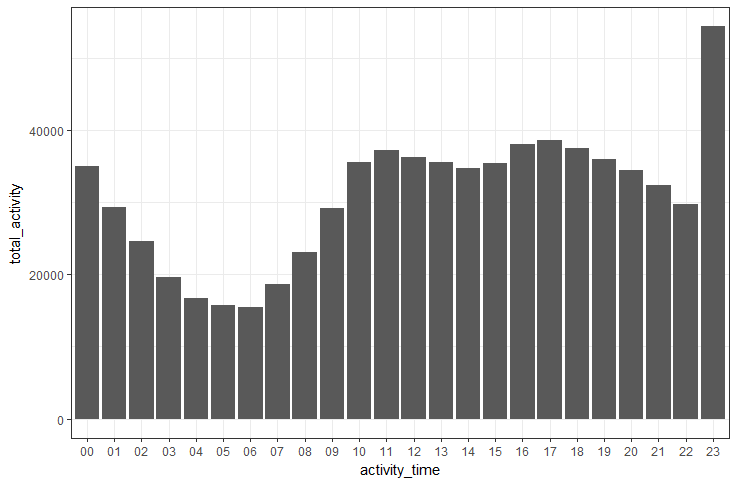
From the above plot, it is evident that most of the activities happened in the hour of 23 and very less activity happened in the hour of 06.
The plot for “Top 25 square grids by total activity” is as follows:
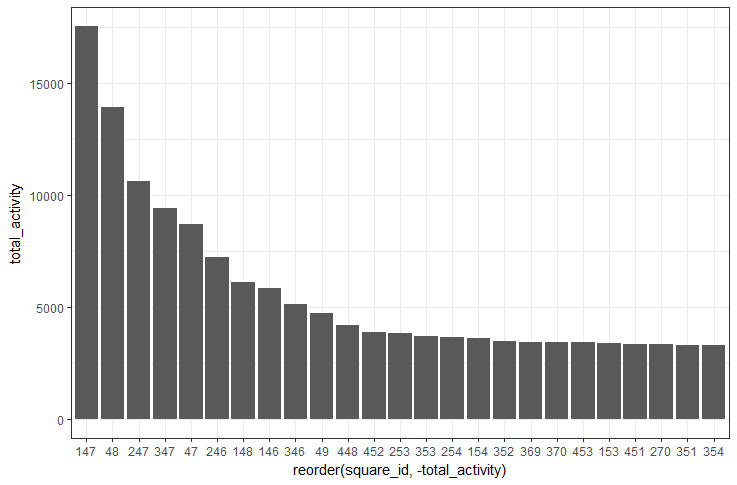
From the above plot, it is evident that most of the activities happened in the square grid ID 147.
The plot for “Top 10 country by total activity” is as follows:
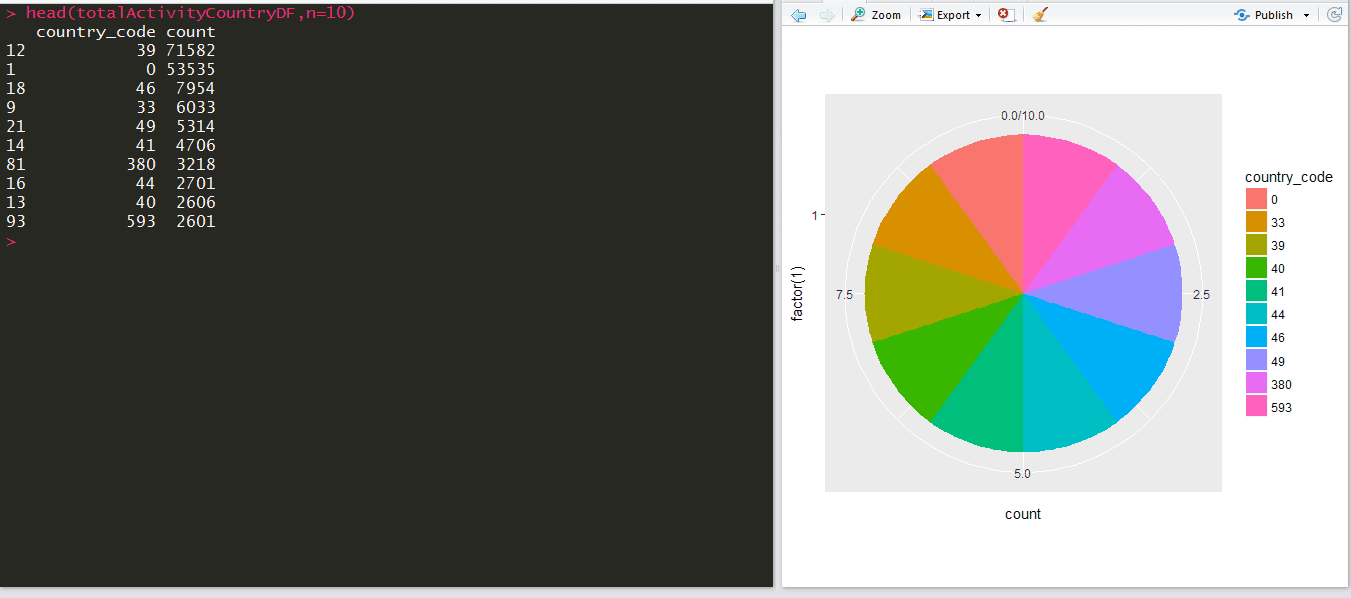
From the above plot, it is evident that the country code 39 has the highest activity.
Call Detail Record Clustering
K-means clustering is the popular unsupervised clustering algorithm used to find the pattern in the data. Here, K-means is applied among “total activity and activity hours” to find the usage pattern with respect to the activity hours.
Elbow method is used to find optimal number of clusters to the K-means algorithm.
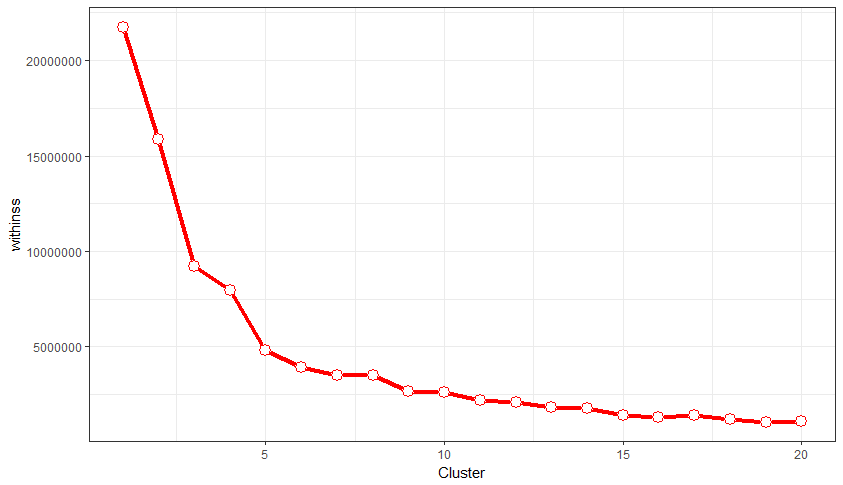
By looking at the above plot, it is evident that Sum of Squared Error (SSE) decreases with minimal change after cluster number 10 and there is no unexpected increase in the error distance. So, the best cluster to perform K-means for this dataset is 10.
The summary of CDR K-means model and its center calculated for each cluster is as follows:
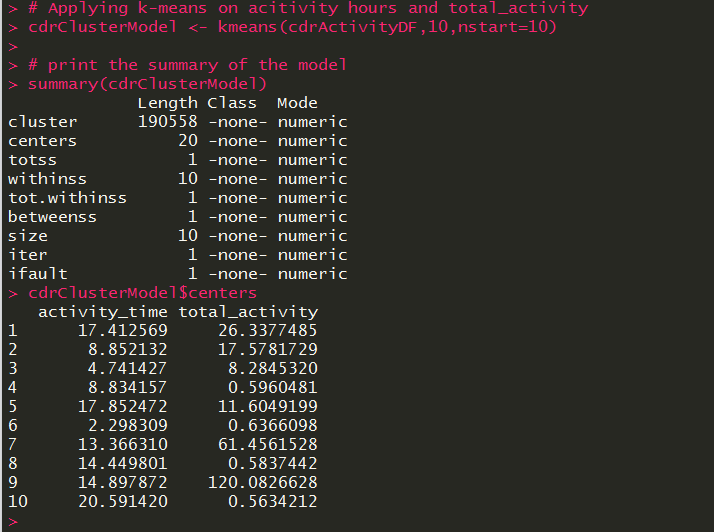
The heat map plot with cluster, activity hour, and total activity time is as follows:
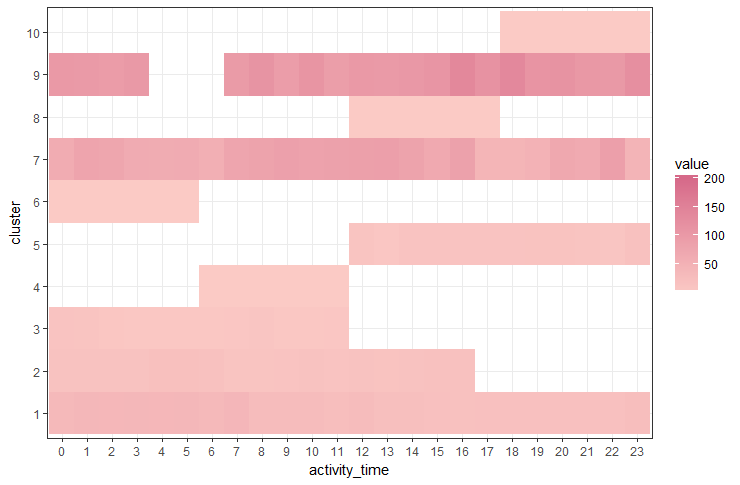
From the above plot, it is evident that the clusters 1, 7, and 9 have activity for all 24 hours and are the more revenue generating clusters. The clusters 1, 5, 7, 9, and 10 have activity in night hours. The cluster 5 has activity from 11.5 to 17 hours.
To read original post, click here
{kind=link}