
In many fields of science, it is important to understand the relevance of new theories or hypotheses in a description of experimental data, assuming that such data are already well represented by predictions of some well-accepted theory. A popular statistical method for setting upper limits (also called exclusion limits) on model parameters of a new theory is based on the CLs method.
Let us show how to set an exclusion limit in case of a counting experiment. We will use particle physics, as an example of hardcore science, where a new theory is considered to be excluded at the 95% confidence level (CL) if CLs = 0.05, and at more than the 95% CL if CLs< 0.05, assuming the presence of a signal that represents a new theory.
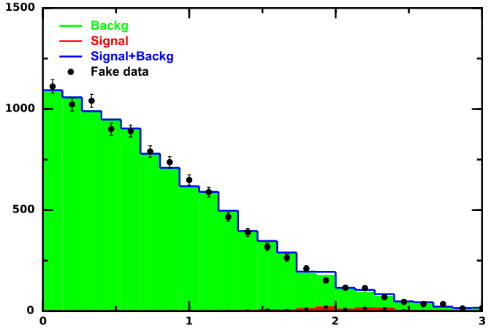
In this small tutorial, we will set the exclusion limits at the 95% CL on empirical distributions (“histograms”). We will use 3 histograms: (1) first histogram represents counts of actual measurements, (2) second histogram is the prediction of a well-established theory, (3) third distribution is a prediction (“signal”) from some new theory. We will use the DataMelt program for this task that allows to use the Python language together with the Java scientific libraries.
Let us generate these histograms using one-tailed Gaussian distributions. The first histogram includes 10,000 events distributed according to one-tailed Gaussian distribution with the standard deviation 1. The second histogram represents our expectation for a known theory (“background”). The latter histogram has a similar shape and the number of events. The third histogram (“signal”) corresponds to the prediction of a new theory. We assume that the new theory contributes to the tail of the experimental data (near x=2). We want to find the maximum number of events of signal (which is a parameter of this new theory) which can be reliable excluded, assuming that the given experimental data is already well described by the well-established theory.
Read full article, with Python code, here.
{kind=link}