
A neural network is a series of algorithms that aims to identify underlying relationships in a set of data through a process that is similar to the way the human brain functions.
Keras is an open-source library written in Python for advancing and evaluating deep learning models. It enables you to define and train neural network models in a few lines of code. In this post, we will learn how to build a neural network using Keras.
In this article, we will learn how to build a Neural Network using Keras.
How to do it?
Installing Keras:
To build a neural network using Keras, we will have to install it first. It provides utilities that make the complex process of building a neural network much easier.
Tensorflow and Keras are implemented in Ubuntu, using the following commands:
$pip install –no-cache-dir tensorflow-gpu==1.7
It is preferable to install a GPU-compatible version, as neural networks work considerably faster when they are run on top of a GPU. Because Keras is a high-level neural network API written in Python, it is capable of running on top of TensorFLow, CNTK, or Theano. The idea behind making it was to enable fast experimentation and can be installed as follows:
$pip install keras
Building Our First Model in Keras
Code file is available as – Neural_networks_multiple_layers.ipynb in GitHub.
- Represent a model that can be called sequentially to add further layers on top of it. The sequential method allows us to perform the model initialization exercise.
from keras.models import Sequential
model = Sequential()
- Add a dense layer to the model as it ensures the connection between various layers in a model. We are connecting the input layer to the hidden layer in the following:
model.add(Dense(3, activation=’relu’, input_shape=(1,)))
In the dense layer initialized with the preceding code, input shape to the model is ensured. Additionally, there will be three connections made to each input (three units in the hidden layer) and the activation thatneeds to beperformed in the hidden layer is the ReLu activation.
- Connect the hidden layer to the output layer.
model.add(Dense(1, activation=’linear’))
In this dense layer, we don’t need to specify the input shape, as the model would already infer the input shape from the previous layer. Also, given that each output is one-dimensional, our output layer has one unit and the activation that we are performing is the linear activation.
model.summary()
The model summary can be visualized as follows:

The preceding output confirms that there will be a total of six parameters in the connection from the input layer to the hidden layer – three weights and three bias terms – we have a lot of six parameters corresponding to the three hidden units. In addition, three weights and one bias term connect the hidden layer to the output layer.
- Now, we will be compiling the model. This ensures that we define the loss function and the optimizer to reduce the loss function and the learning rate corresponding to the optimizer.
from keras.optimizers import sgd
sgd = sgd(LR = 0.01)
In the preceding step, it is clear that the optimizer is the stochastic gradient descent and the learning rate is 0.01. Pass the predefined optimizer and its corresponding learning rate as a parameter and reduce the mean squared error value:
model.compile(optimizer=sgd,loss=’mean_squared_error’)
- Fit the model by updating the weights, so that its better fit.
model.fit(np.array(x), np.array(y), epochs=1, batch_size = 4, verbose=1)
The fit method expects that it receives two NumPy arrays: an input array and the corresponding output array. Note that epochs represent the number of times the total dataset is traversed through, and batch_size represents the number of data points that need to be considered in an iteration of updating the weights. Furthermore, verbose specifies that the output is more detailed, with information about losses in training and test datasets as well as the progress of the model training process.
- Extract weight values. The order in which the weight values are presented is obtained by calling the weights method on the top of the model, as follows:
model.weights
The order in which weights are obtained is as follows:

From the preceding output, we see that the order of weights is the three weights (kernel) and three bias terms in the dense_1 layer (which is the connection between the input to the hidden layer) and the three weights (kernel) and one bias term connecting the hidden layer to the dense_2 layer (the output layer).
Now that we understand the order in which weight values are presented, let’s extract the values of these weights:
model.get_weights()
Notice that the weights are presented as a list of arrays, where each array corresponds to the value that is specified in the model.weights output.
The output of the above lines of code is as follows:

You should notice that the output we are observing here matches with the output we obtained while hand-building the neural network
- Predict the output for a new set of input using the predict method:
x1 = [[5],[6]]
model.predict(np.array(x1))
Note that x1 is the variable that holds the values for the new set of examples for which we need to predict the value of the output. Similarly to the fit method, the predict method also expects an array as its input.
The output of the preceding code is as follows:

Note that, while the preceding output is incorrect, the output when we run for 100 epochs is as follows:
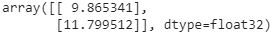
The preceding output will match the expected output (which are 10, 12) as we run for an even higher number of epochs.
In the above article, we summarized how to build neural networks with the help of Keras, illustrated in steps with references. This was a snippet taken from ‘Neural Networks with Keras Cookbook’ which deals with the neural network architectures such as CNN, RNN, and LSTM in Keras. It also helps you discover tricks for designing a robust neural network to solve real-world problems. If this interests you, and you wish to learn more about multiple advanced neural networks from scratch, this book could be the one for you.
{kind=link}