
In the past year I have also worked with Deep Learning techniques, and I would like to share with you how to make and train a Convolutional Neural Network from scratch, using tensorflow. Later on we can use this knowledge as a building block to make interesting Deep Learning applications.
The pictures here are from the full article. Source code is also provided.
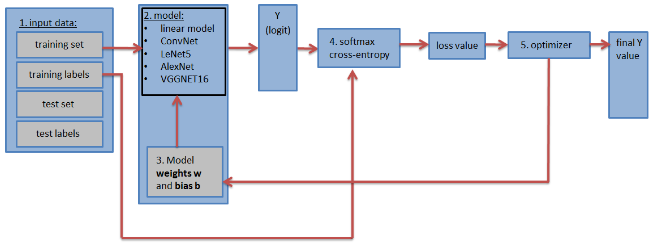
Before you continue, make sure you understand how a convolutional neural network works. For example,
- What is a convolutional layer, and what is the filter of this convolutional layer?
- What is an activation layer (ReLu layer (most widely used), sigmoid activation or tanh)?
- What is a pooling layer (max pooling / average pooling), dropout?
- How does Stochastic Gradient Descent work?
The contents of this blog-post is as follows:
1. Tensorflow basics:
- Constants and Variables
- Tensorflow Graphs and Sessions
- Placeholders and feed_dicts
2. Neural Networks in Tensorflow
- Introduction
- Loading in the data
- Creating a (simple) 1-layer Neural Network:
- The many faces of Tensorflow
- Creating the LeNet5 CNN
- How the parameters affect the outputsize of an layer
- Adjusting the LeNet5 architecture
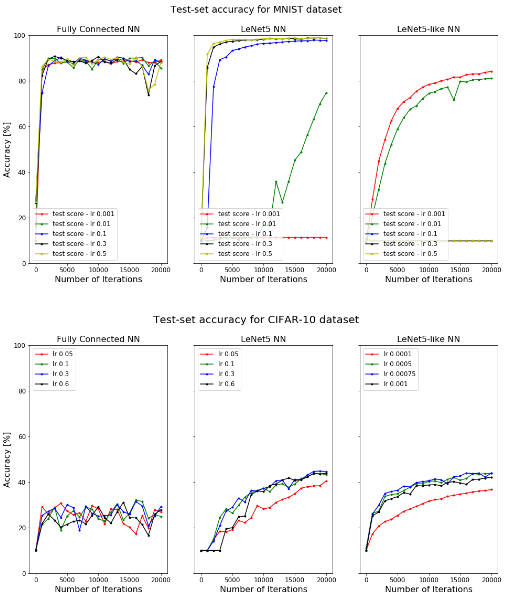
- Impact of Learning Rate and Optimizer
3. Deep Neural Networks in Tensorflow
- AlexNet
- VGG Net-16
- AlexNet Performance
4. Final words
To read this blog, click here. The code is also available in my GitHub repository, so feel free to use it on your own dataset(s).
{kind=link}