
By Siddartha Mani
Few would argue with the statement that Hadoop HDFS is in decline. In fact, the HDFS part of the Hadoop ecosystem is in more than just decline – it is in freefall. At the time of its inception, it had a meaningful role to play as a high-throughput, fault-tolerant distributed file system. The secret sauce was data locality.
By co-locating compute and data on the same nodes, HDFS overcame the limitations of slow network access to data. The implications, however, are well known at this point. By co-locating data and compute, for every storage node added, a compute node must be added. Given that data growth rapidly outpaced the need for compute growth, a massive imbalance resulted. Compute nodes sat idle. Multiple analyst firms report clients with CPU utilization in the single digits for larger instances.
This is further exacerbated by HDFS’s limitations and replication scheme. Hadoop vendors limit the capacity per data node to a maximum of 100 TB and only support 4 TB or 8 TB capacity drives. For instance, in order to store 10 petabytes of data, 30 petabytes of physical storage is needed (3x replication). This would require a minimum of 300 nodes of storage and 300 nodes of compute.
Needless to say, this is highly inefficient.
The solution to this problem is to disaggregate storage and compute, so that they can be scaled independently. Object storage utilizes denser storage servers such as the Cisco UCS S3260 Storage Server or the Seagate Exos AP 4U100. These boxes can host more than a petabyte of usable capacity per server as well as 100 GbE network cards. Compute nodes, on the other hand, are optimized for MEM and GPU intensive workloads. This architecture is a natural fit for cloud-native infrastructure where the software stack and the data pipelines are managed elastically via Kubernetes.
While cloud-native infrastructure is more scalable and easier to manage, it is only part of the story – in the same way that cost is only part of the story. The other part is performance.
One of the reasons that HDFS has survived is that competing architectures can’t deliver its performance at scale.
That is no longer true. Modern, cloud-native object storage has shattered the perception of what is possible on the performance front. This post demonstrates that by comparing the performance of Hadoop HDFS and MinIO using the most proven Hadoop benchmarks: Terasort, Sort and Wordcount. The results demonstrate that object storage is on par with HDFS in terms of performance – and makes a clear case for disaggregated Hadoop architecture.

What makes this comparison interesting and meaningful is that MinIO and HDFS were both operating in their native environments (disaggregated and aggregated respectively).
The MinIO benchmarks were performed on AWS bare-metal storage-optimized instances (h1.16xlarge) with local hard disk drives and 25 GbE networking. The compute jobs ran on compute-optimized instances (c5d.18xlarge) connected to storage by 25GbE networking.
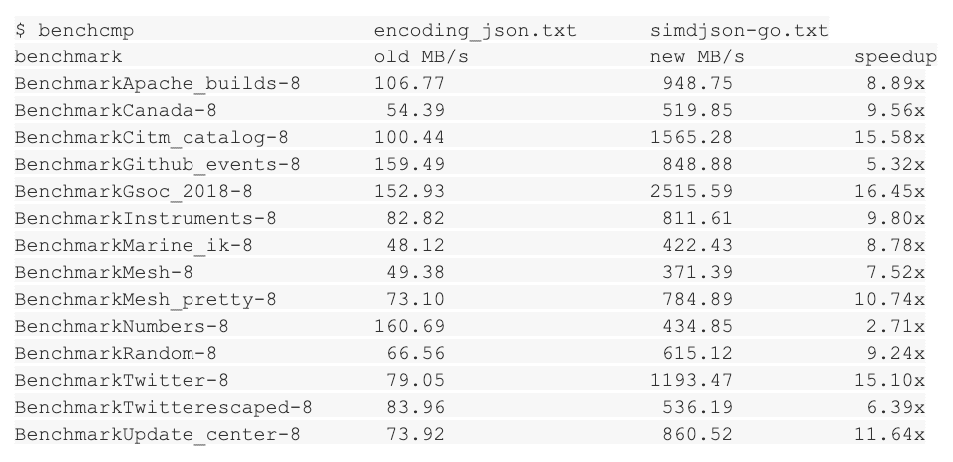
Disaggregated storage and compute architecture for MinIO
The HDFS benchmarks were performed on AWS bare-metal instances (h1.16xlarge) with local hard disk drives and 25 GbE networking. MapReduce on HDFS has the advantage of data locality and 2x the amount of memory (2.4 TB).

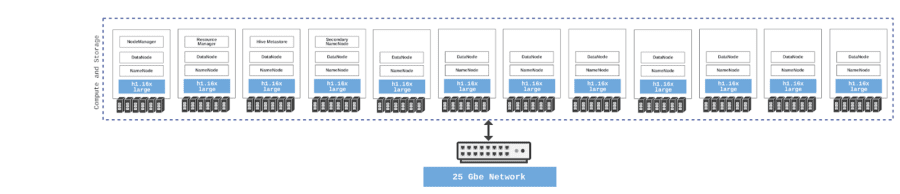
Co-located storage and compute architecture for Hadoop HDFS
The software versions for each were as follows:
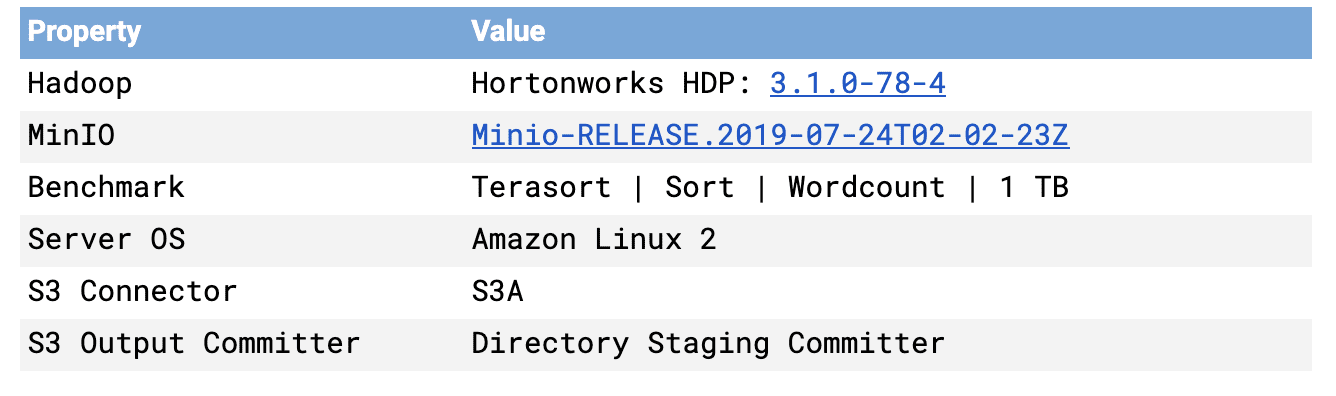
The HDFS instance required considerable tuning – the details of which are covered in the full benchmark paper.
Discussed in some detail is the use of the S3A committer as well as the evaluation of Netflix’s Directory staging committer and the Partitioned staging committer, as they do not require rename operations. The Magic committer was also evaluated.
It was found that the Directory staging committer was the fastest among the three and it was used in the benchmarking.
Benchmarking was divided into two phases: data generation and benchmarking tests.
In the data generation phase, the data for the appropriate benchmarks were generated. Even though this step is not performance-critical, it was still evaluated to assess the differences between MinIO and HDFS.

Note that the data generated for the Sort benchmark can be used for Wordcount and vice-versa.
In the case of Terasort, the HDFS generation step performed 2.1x faster than MinIO. In the case of Sort and Wordcount, the HDFS generation step performed 1.9x faster than MinIO.
During the generation phase, the S3 staging committers were at a disadvantage, as the committers stage the data in RAM or disk and then upload to MinIO. In the case of HDFS and the S3A Magic committer, the staging penalty does not exist.
Despite the disadvantage during the generation phase, the rest of the benchmarking tilted strongly in favor of MinIO’s disaggregated approach.
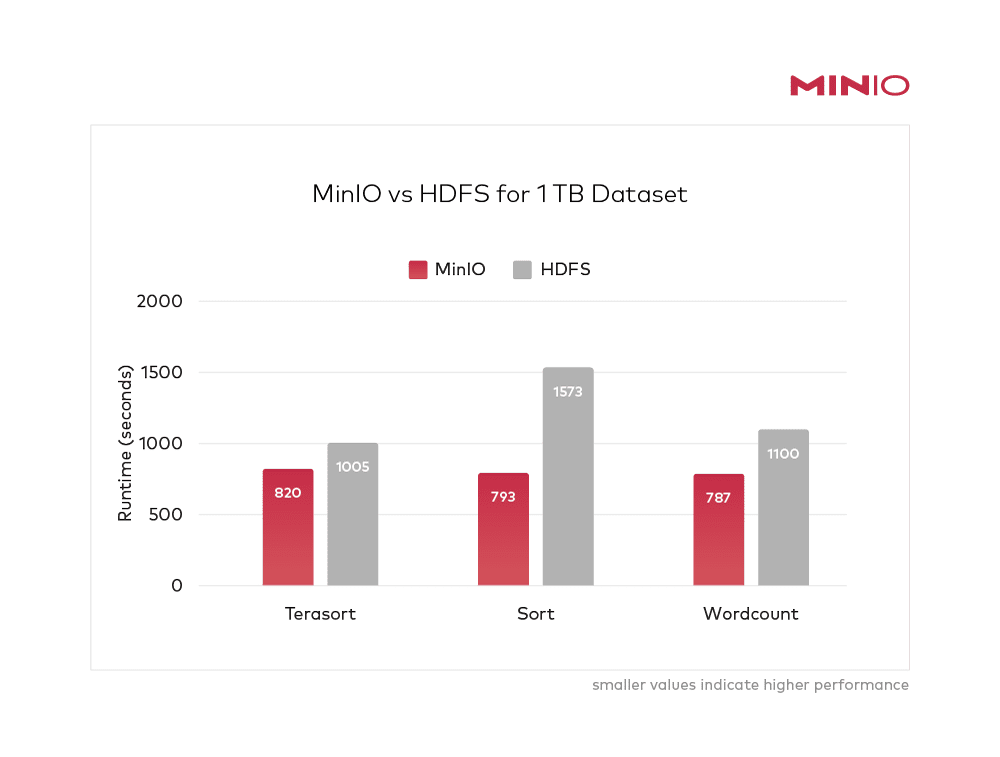

These results are significant on a number of fronts.
First, this is well, well beyond the performance capabilities normally attributed to object storage. This is an industry that is defined by cheap and deep archival and backup storage with brand names like Glacial. Faster than Hadoop performance is unheard of.
Second, this completely changes the economics of advanced analytics at scale. Hadoop’s TCO challenges are well known, but with MinIO the price/performance curve is totally different. The cost component is a fraction of Hadoop, the people cost a fraction of Hadoop, the complexity is a fraction of Hadoop and the performance a multiple. For most enterprises, getting close on performance would be enough to get them to migrate to a disaggregated architecture – this is more, far more.
Third, modern object storage is, well, modern. It has a modern API (Amazon S3) it was designed for a world with containers and orchestration and best-of-breed microservices. This world, microservices, Kubernetes and containers, is a vibrant, growing ecosystem – a far cry from the shrinking Hadoop ecosystem. This means a future and innovation for those who are on the cloud-native train.
It should be noted that this also draws a line for the legacy appliance vendors in the object storage space. Cloud native is not in their DNA. They are stuck in their low gear.
So what makes MinIO fast? There are five primary elements:
- We only serve objects. We built the platform from the ground up to solve just that problem and to do it better than anyone else. We didn’t bolt object onto a file or block architecture. Multiple layers cause complexity. Complexity causes latency.
- We don’t employ a metadata database. Object and metadata are written together in a single, atomic operation. Other approaches have multiple steps and multiple steps cause latency.
- We employ SIMD (Single Instruction Multiple Data) acceleration. By writing the core parts of MinIO in assembly language (SIMD extensions) we are hyperfast on commodity HW.
- We combine GO + Assembly language to deliver C-like performance by targeting them to the task.
- We are relentless in the pursuit of simplicity. The result is that features such as inline erasure code, bitrot protection, encryption, compression, strict consistency and synchronous I/O are deminimis from a performance perspective.
The net result is a shift in the way that enterprise will consume object storage. No longer will they look at it solely as the destination for older data, but as the hot tier for advanced analytics, Spark, Presto, Tensorflow and others.
{kind=link}