

With more and more data being pushed online, the requirement of asynchronous web scraping services is at an all-time high. Many businesses are relying on the data-driven methodologies to drive their organizational goals. With synchronous web scraping, most of the usual demands of data can be met which generally revolve around small batches of data. Although the former part works well, web scraping still suffers from bad execution time in the case of scrapping high volume data.
In this blog, we are going to look at the problems being faced while scraping large chunks of data from online websites. Going ahead, we will further explore the asynchronous web scraping to make our python web scrappers quick and efficient for data-heavy web scraping.
Still doubtful about the legality of web scraping, this will help you in clearing some myths
What is Web Scraping
Web scraping, simply put, is a process of extracting content from a website. When the amount of content to be fetched is small, then manually copying content is one approach but when the size of required content increases, automatic web scraping is employed. There are a lot of tools available in the market for scraping content. Libraries like Beautiful Soup and Scrapy are few examples of scraping libraries available in the Python programming language.
Web scraping enables the user to collect data from online resources for their analysis and other requirements. Collected data is generally saved back in local storages or is pushed to databases for persistent storage.
Web scraping generally involves a code which opens a target website and extracts all the required content from it. Required information can generally be mentioned by the user beforehand.
Challenges in Web scraping
Web scraping is simple for users looking to retrieve data from online resources. But there is more to this story. What about the owners of the website looking to preserve their data from all the scraping happening around the web? Website owners tend to block web scraping activities on their websites. They do so by identifying and blocking the IP addresses requesting content from that website.
Also, normal web scraping is beneficial for most of the use cases but fails when the amount of extracted data is high as it is a very time-consuming process. There was an urgent need for a solution to extract a large amount of content from websites without compromising on the execution speed of the entire process. To cater to the before-mentioned limitations, the benefits of asynchronous programming are reaped to the full potential. In the next section, we will explore how asynchronous programming solves our issue of extracting large content quickly and efficiently
Overcoming challenges with asynchronous web scraping
In order to understand the role of asynchronous web scraping in making scraping process faster, we need to understand asynchronous programming first. Let us take a simple example from real life to understand it at an uber level.
Every time in the morning, when I leave for office, I need to do some chores like taking a bath, preparing my lunch, etc, before I am ready to leave. If I were to perform these tasks one by one, it used to consume almost 45 mins of mine every morning. I am always fine with this only when I am not getting late to work. So how do we optimize this?
A naive approach can be executing all the tasks in parallel. I can wake up and switch geyser on first. Rather than waiting for the geyser to heat the water up, I will rush to the kitchen and start preparing my lunch. As soon as the water is ready, I will come back and take my bath. In this case, we are able to utilize the extra wait time taken by the geyser and use that effectively to prepare lunch instead. Now the total activity took just 15 mins! This, in short, is the main essence of asynchronous programming.
Asynchronous web scraping allows us to process and collect data from a large number of web pages in parallel. Doing all the scrapping in parallel threads, allows us to save time. We, no longer, need to wait for scraping of one page to finish before we start scraping the other!
How does asynchronous web scraping work
The distinction between synchronous and asynchronous performance might at first appear somewhat different. Program performance is generally very simple in most high-level languages. The first row of source code begins with your program and then every row of code performed sequentially. The implementation of the synchronous program is somewhat like the above. You are running your program one line at a moment(line by line) Whenever a function is called, the execution of the program waits for this function to return to the next code line. But in case of asynchronous web scraping, your scraper runs in parallel processes to collect data from websites and does not wait for one code to finish its execution. The program starts performing other tasks when the wait time is present and as soon as it encounters the response from waiting tasks, its starts processing them.
Asynchronous web scraping using python
In this section, we will implement asynchronous web scraping using python. In order to show the difference between the synchronous and the asynchronous counterpart, we will implement both the codes and try to see the execution time difference.
We are using the Beautiful Soup library to scrape contents from the websites. We have gathered 10 weblinks having mobile phone data. Our aim here is to scrape all the data in the minimum time possible.
Let us start with the synchronous part first. Below is the code for initialising all the variables.
### Importing libraries ###from bs4 import BeautifulSoupimport grequestsimport requestsimport time/code>### Starting the timer ###start_time = time.time() |
### List of urls to scrape data from ###links = []Synchronous web scraping methodOnce we have all our variables set up, we can start scraping mobile phone data. All we have to do here is to iterate all the weblinks one by one and pull out the product name, price, and the offered discount. We are using the request library to fetch web content and the beautiful soup library to parse all the content and fetch our required listings. Below code performs the above-mentioned task
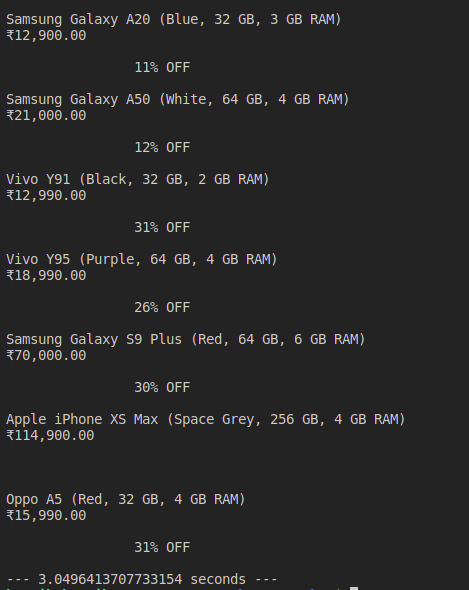
After running the above code, we can see the listings in the console of the command line. Fetching all the pages one by one and extracting our data out took roughly around 14 seconds. This is an example of asynchronous programming. In the next, section we will be implementing the asynchronous version
Asynchronous web scraping methodTo perform asynchronous web scraping, we will be using the GRequests library. It executes the parallel fetching of the data from all the web pages without waiting for one process to complete. GRequests allows you to use Requests with Gevent to make asynchronous HTTP requests easily. If you find it difficult to catch up these topics, try the quality video tutorials to ease the studies. Reliable video production companies are making these modes of videos to ease the process. Below is the asynchronous implementation for pulling data from 10 different websites.
You can easily see the effect of pulling data asynchronously after running the above program. The program took 3 seconds to fetch all data as compared to 14 seconds taken by the synchronous counterpart. We have saved almost 11 seconds here which is actually a big deal when are dealing with bulk data scraping.
|

{kind=link}