

Among the many decisions youll have to make when building a predictive model is whether your business problem is either a classification or an approximation task. Its an important decision because it determines which group of methods you choose to create a model: classification (decision trees, Naive Bayes) or approximation (regression tree, linear regression).
This short tutorial will help you make the right decision.
Classification when to use?
Classification works by looking for certain patterns in similar observations from the past and then tries to find the ones which consistently match with belonging to a certain category. If, for example, we would like to predict observations:
- Is a particular email spam? Example categories: SPAM & NOT SPAM
- Will a particular client buy a product if offered? Example categories: YES & NO
- What range of success will a particular investment have? Example categories: Less than 10%, 10%-20%, Over 20%
Classification how does it work?
Classification works by looking for certain patterns in similar observations from the past and then tries to find the ones which consistently match with belonging to a certain category. If, for example, we would like to predict observations:
- With researched variable y with two categorical values coded blue and red. Empty white dots are unknown could be either red or blue.
- Using two numeric variables x1 and x2 which are represented on horizontal and vertical axes. As seen below, an algorithm was used which calculated a function represented by the black line. Most of the blue dots are under the line and most of the red dots are over the line. This guess is not always correct, however, the error is minimized: only 11 dots are misclassified.
- We can predict that empty white dots over the black line are really red and those under the black line are blue. If new dots (for example future observations) appear, we will be able to guess their color as well.
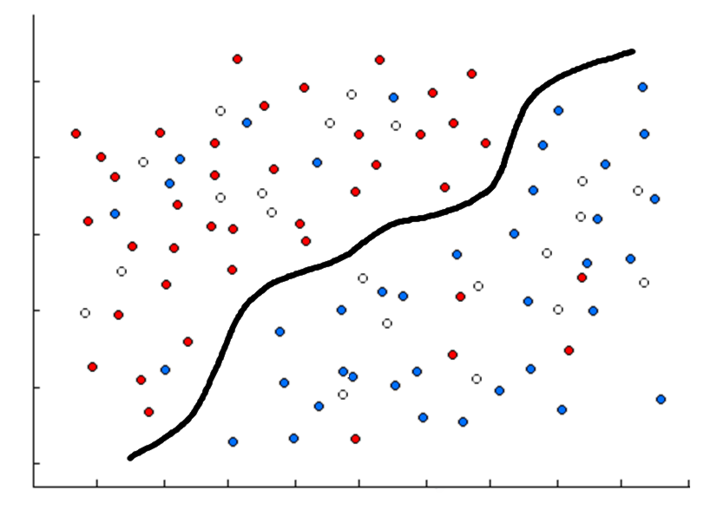
Of course, this is a very simple example and there can be more complicated patterns to look for among hundreds of variables, all of which is not possible to represent graphically.
Approximation when to use?
The approximation is used when we want to predict the probable value of the numeric variable for a particular observation. An example could be:
- How much money will my customer spend on a given product in a year?
- What will the market price of apartments be?
- How often will production machines malfunction each month?
Approximation how does it work?
Approximation looks for certain patterns in similar observations from the past and tries to find how they impact the value of a researched variable. If, for example, we would like to predict observations:
- With numeric variable y that we want to predict.
- With numerical variable x1 with value that we want to use to predict the first variable.
- With categorical variable x2 with two categories: left and right, that we want to use to predict the first variable.
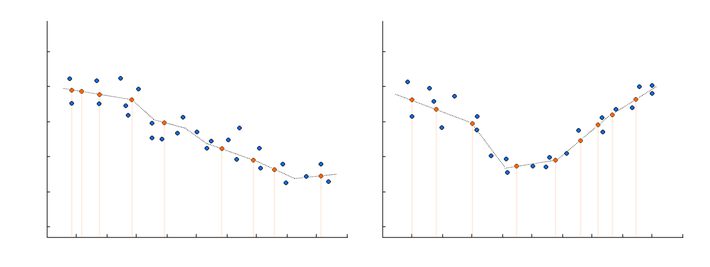
- Blue circles represent known observations with known y, x1, x2.
- Since we cant plot all three variables on a 2d plot, we split them into two 2d plots. The left plot shows how the combination of variables x1 and x2=left is connected to the variable y. The second shows how the combination of variables x1 and x2=right is connected to the variable y.
- The black line represents how our model predicts the relationship between y and x1 for both variants of x2. The orange circle represents new predictions of y on observation when we only know x1 and x2. We put orange circles in the proper place on the black line to get predicted values for particular observations. Their distribution is similar to blue circles.
- As can clearly be seen, distribution and obvious pattern of connection between y and x1 is different for both categories of x2.
- When a new observation arrives, with known x1 and x2, we will be able to make new predictions.
Discretization
Even if your target variable is a numeric one, sometimes its better to use classification methods instead of approximation, for instance, if you have mostly zero target values and just a few non-zero values. Change the latter to 1, in this case youll have two categories: 1 (positive value of your target variable) and 0. You can also split the numerical variable into multiple subgroups: apartment prices for low, medium, and high by the equal subset width, and predict them using classification algorithms. This process is called discretization.
Curious about proprietary technology?
Follow Algolytics on LinkedIn.
{kind=link}