
Why would a data scientist use Kafka Jupyter Python KSQL TensorFlow all together in a single notebook?
There is an impedance mismatch between model development using Python and its Machine Learning tool stack and a scalable, reliable data platform. The former is what you need for quick and easy prototyping to build analytic models. The latter is what you need to use for data ingestion, preprocessing, model deployment and monitoring at scale. It requires low latency, high throughput, zero data loss and 24/7 availability requirements.
This is the main reason I see in the field why companies struggle to bring analytic models into production to add business value. Python in practice is not the most well-known technology for large scale and performant, reliable environments. However, it is a great tool for data scientist and a great client of a data platform like Apache Kafka.
Therefore, I created a project to demonstrate how this impedance mismatch can be solved. A much more detailed blog post about this topic will come on Confluent Blog soon. In this blog post here, I want to discuss and share my Github project:
“Making Machine Learning Simple and Scalable with Python, Jupyter No…“. This project includes a complete Jupyter demo which combines:
- Simplicity of data science tools (Python, Jupyter notebooks, NumPy, Pandas)
- Powerful Machine Learning / Deep Learning frameworks (TensorFlow, Keras)
- Reliable, scalable event-based streaming technology for production deployments (Apache Kafka, Kafka Connect, KSQL).
If you want to learn more about the relation between the Apache Kafka open source ecosystem and Machine Learning, please check out these two blog posts:
- How to Build and Deploy Scalable Machine Learning in Production wit…
- Using Apache Kafka to Drive Cutting-Edge Machine Learning
Let’s quickly describe these components and then take a look at the combination of them in a Jupyter notebook.
Python, Jupyter Notebook, Machine Learning / Deep Learning
Jupyter exists to develop open-source software, open-standards, and services for inte…. Therefore, it is a great tool to build analytic models using Python and machine learning / deep learning frameworks like TensorFlow.
Using Jupyter notebooks (or similar tools like Google’s Colab or Hortonworks’ Zeppelin) together with Python and your favorite ML framework (TensorFlow, PyTorch, MXNet, H2O, “you-name-it”) is the best and easiest way to do prototyping and building demos.
However, building prototypes or even sophisticated analytic models in a Jupyter notebook with Python is a different challenge than building a scalable, reliable and performant machine learning infrastructure. I always refer to the great paper Hidden Technical Debt in Machine Learning Systems for this discussion:
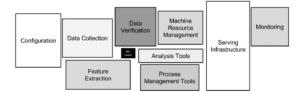
Think about use cases where you CANNOT go into production without large scale. For instance, connected car infrastructures, payment and fraud detection systems or global web applications with millions of users. This is where the Apache Kafka ecosystem comes into play.
Apache Kafka and KSQL
Apache Kafka is an open-source stream-processing software platform developed by Linkedin and donated to Apache Software Foundation. It is written in Scala and Java. The project aims to provide a unified, high-throughput, low-latency streaming platform for handling and processing real-time data feeds.
Confluent KSQL is the streaming SQL engine that enables real-time data processing against…. It provides an easy-to-use, yet powerful interactive SQL interface for stream processing on Kafka; without the need to write code in a programming language such as Java or Python. KSQL is scalable, elastic, fault-tolerant. It supports a wide range of streaming operations, for example data filtering, transformations, aggregations, joins, windowing, and sessionization.
Check out these slides and video recording from my talk at Big Data Spain 2018 in Madrid if you want to learn more abo….
Kafka + Jupyter + Python to solve the hidden technical dept in Machine Learning
To solve the hidden technical dept in Machine Learning infrastructures, you can combine the benefits of ML related tools and the Apache Kafka ecosystem:
- Python tool stack like Jupyter, Pandas or scikit-learn
- Machine Learning frameworks like TensorFlow, H2O or DeepLearning4j
- Apache Kafka ecosystem including components like Kafka Connect for integration and Kafka Streams or KSQL for real time stream processing and model inference
The following diagram depicts an example of such an architecture:
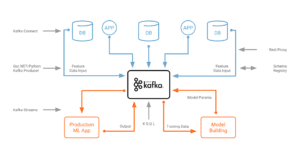
If you want to get a better understanding of the relation between the Apache Kafka ecosystem and Machine Learning / Deep Learning, check out the following material:
- Blog Post: How to Build and Deploy Scalable Machine Learning in Production wit…
- Slide Deck: Apache Kafka + Machine Learning => Intelligent Real Time Applica…
- Slide Deck: Deep Learning at Extreme Scale (in the Cloud) with the Apache Kafk…
- Video Recording: Deep Learning in Mission Critical and Scalable Real Time Applicatio…
- Blog Post: Using Apache Kafka to Drive Cutting-Edge Machine Learning – Hybrid …
Example: Kafka + Jupyter + Python + KSQL + TensorFlow
Let’s now take a look at an example which combines all these technologies like Python, Jupyter, Kafka, KSQL and TensorFlow to build a scalable but easy-to-use environment for machine learning.
This Jupyter notebook is not meant to be perfect using all coding and ML best practices, but just a simple guide how to build your own notebooks where you can combine Python APIs with Kafka and KSQL.
Use Case: Fraud Detection for Credit Card Payments
We use a test data set of credit card payments from Kaggle as foundation to train an unsupervised autoencoder to detect anomalies and potential fraud in payments.
Focus of this project is not just model training, but the whole Machine Learning infrastructure including data ingestion, data preprocessing, model training, model deployment and monitoring. All of this needs to be scalable, reliable and performant.
Leveraging Python + KSQL + Keras / TensorFlow from a Jupyter Notebook
The notebook walks you through the following steps:
- Integrate with events from a Kafka stream,
- Preprocess data with KSQL (transformations, aggregations, filtering, etc.)
- Prepare data for model training with Python libraries, i.e. preprocess data with Numpy, Pandas and scikit-learn
- Train an analytic model with Keras and TensorFlow using Python API
- Predict data using the analytic model with Keras and TensorFlow using Python API
- Deploy the analytic model to a scalable Kafka environment leveraging Kafka Streams or KSQL (not part of the Jupyter notebook, but links to demos are shared)
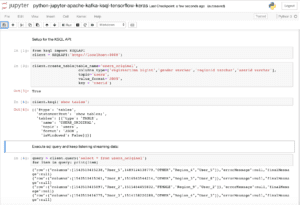
Here is a screenshot of the Jupyter notebook where use the ksql-python API to
- Connect to KSQL server
- Create first KSQL STREAM based on Kafka topic
- Do first SELECT query
Check out the complete Jupyter Notebook to see how to combine Kafka, KSQL, Numpy, Pandas, … to integrate and preprocess data and then train your analytic model.
Why should a Data Scientist use Kafka and KSQL at all?
Yes, you can also use Pandas, scikit-learn, TensorFlow transform, and other Python libraries in your Jupyter notebook. Please do so where it makes sense! This is not an “either … or” question. Pick the right tool for the right problem.
The key point is that the Kafka integration and KSQL statements allow you to
- Use the existing environment of the data scientist which he loves (including Python and Jupyter) and combine it with Kafka and KSQL to integrate and continuously process real time streaming data by using a simple Python Wrapper API to execute KSQL queries.
- Easily connect to streaming data instead of just historical batches of data (maybe from last day, week or month, e.g. coming in via CSV files).
- Merge different concepts like streaming event-based sensor data coming from Kafka with Python programming concepts like Generators or Dictionaries which you can use for your Python data tools or ML frameworks like Numpy, Pandas or scikit-learn
- Reuse the same logic for integration, preprocessing and monitoring and move it from your Jupyter notebook to large scale test and production systems.
Check out the complete Jupyter notebook to see a full example which combines Python, Kafka…. In my opinion, this is a great combination and valuable for both, data scientist and software engineers.
I would like to get your feedback. Do you see any value in this? Or does it not make any sense in your scenarios and use cases?
{kind=link}