
Guest blog by Francesco Gadaleta. Francesco is Data Scientist at Janssen Pharmaceutical Companies of Johnson & Johnson and a Science writer. He is committed to “A World Without Disease” paradigm shift in healthcare, leveraging Artificial Intelligence and Data Science to predict risk and intercepting diseases. He is focused on putting machine learning at the service of human beings.
Do you know why you can’t hear the ugly ahem sounds on the podcast Data Science at Home?
Because we remove them. Actually not us. A neural network does.
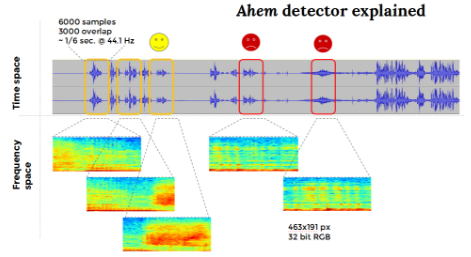
Let me introduce the ahem detector, a deep convolutional neural network that is trained on transformed audio signals to recognize “ahem” sounds. The network has been trained to detect such signals on the episodes of Data Science at Home, the podcast about data science at worldofpiggy.com/podcast.
PROJECT DESCRIPTION
Slides and technical details are provided provided here.
Before getting to the details, a few concepts should be clarified.
Two sets of audio files are required, very similarly to a cohort study:
-
a negative sample with clean voice/sound and
-
a positive one with “ahem” sounds concatenated
While the detector works for the aforementioned audio files, it can be generalized to any other audio input, provided enough data are available. The minimum required is ~10 seconds for the positive samples and ~3 minutes for the negative cohort. The network will adapt to the training data and can perform detection on different spoken voice.
HOW DO I GET SET UP?
Once the training audio files are provided, just load the training set and train the network with the code in the ipython notebook. Make sure to create the local folder that has been hardcoded in the script files below. Build training/testing set before running the script. Execute first
% python make_data_class_0.py
% python make_data_class_1.py A GPU is recommended as, under the conditions specific to this example at least 5 epochs are required to obtain ~81% accuracy.
HOW DO I CLEAN A NEW DIRTY AUDIO FILE?
A new audio file must be trasformed in the same way of training files. This can be done with
% python make_data_newsample.py
Then follow the script in the ipython notebook that is commented enough to proceed without particular issues. The whole project is on github
Enjoy!
{kind=link}