
Summary: The Gartner Magic Quadrant for Data Science and Machine Learning Platforms is just out and once again there are big changes in the leaderboard. Some major incumbents have fallen and some new challengers have emerged.
The Gartner Magic Quadrant for Data Science and Machine Learning Platforms is just out and once again there are big changes in the leaderboard. Say what you will about our profession but as a platform developer you certainly can’t rest on your laurels. Some traditional leaders have fallen (SAS, KNIME, H2Oai, IBM) and some challengers have risen (Alteryx, TIBCO, RapidMiner).
Blue dots are 2019, gray dots 2018. 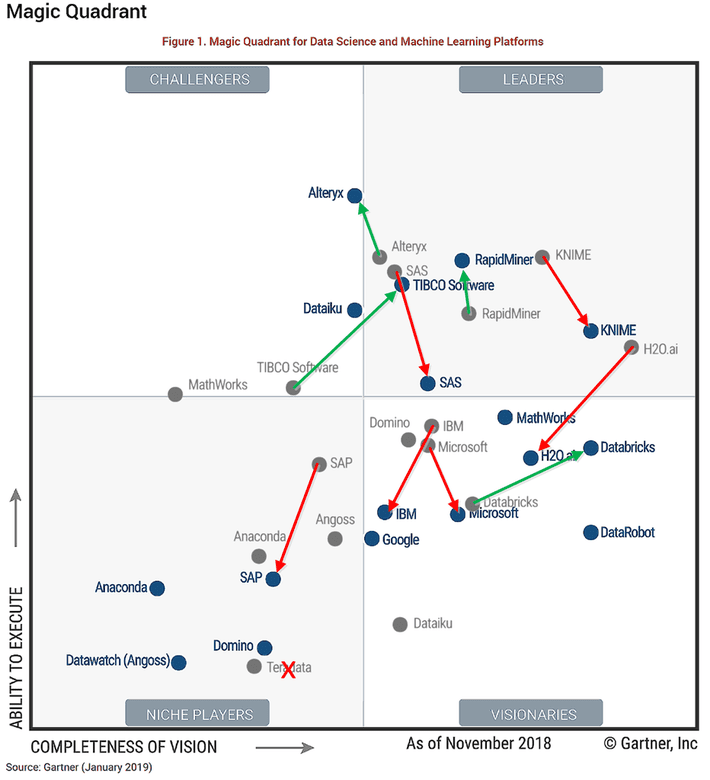
This year and last year saw big moves that seemed out of character with prior years when change had been more incremental. One possibility is that the scoring had changed or perhaps the nature of the offerings had evolved more rapidly than we thought. We started with a side-by-side comparison of the scoring criteria for last year and this.
Has the Scoring Changed?
Actually the scoring criteria are pretty consistent from last year. The emphasis is on platforms that are: “A cohesive software application that offers a mixture of basic building blocks essential for creating all kinds of data science solution, and for incorporating those solutions into business processes, surrounding infrastructure and products.”
In other words from ingest and blending through modeling, implementation, and refresh. Looks like we’re evolving toward ERPs for data.
There’s no bias in favor of those that offer ‘professional’ free form coding platforms, versus ‘augmented’ drag-and-drop, and even an entry from the fully automated machine learning (AML) group this year.
There is an appropriate increasing bias toward platforms that serve all the data functions in the company, from data scientist to data analyst to line of business manager. Some extra points if:
- You’re easy for citizen data scientist to use (think data viz),
- That your platform is fully integrated (not an agglomeration of open source and best of breed modules that only weakly fit together), and
- Points for collaboration tools since this has definitely become a team sport.
Machine Learning is the Focus – AI Gets Noticed but Not Scored
Gartner specifically calls out that this is about machine learning ML model building, not AI. Although AI continues to grow in importance, the vast majority of users create value with ML models.
Here are the Changes that Caught our Eye:
Alteryx continues its rapid rise to the top in ability to execute but almost falls out of the Leaders box. Strong as they are, Gartner dings them for appealing mainly to citizen data scientists and entry level data scientists.
TIBCO moves from Challenger to high level Leader. TIBCO has fully digested its acquisitions of Statistica and Alpine Data to offer a strong end-to-end platform with added points for IoT and real time data capture and scoring.
SAS remains a leader but continues to slip. The continuing criticism is that its offerings are so numerous as to be confusing and complex to deploy. However, it has an almost unassailable install base.
IBM that was the exalted leader in 2017 has slipped for two straight years completely out of the leader box to be ranked as a mid-tier player. They confused the market with three separate DS platforms that are now down to two (the Data Science Experience having been folded into Watson Studio), but flagship SPSS still gets dinged in many areas.
RapidMiner gained slightly and KNIME slipped slightly but both are still strongly in the Leader box.
Databricks was new on the stage last year and has scored a big improvement in the visionary quadrant. Perhaps better known as a premier distributor of Spark 2.0, they are now clearly in the end-to-end analytic platform space.
Teradata was dropped altogether this year. Word is they are completely revamping their ML platform and will try again next year.
New and Startling
Two adds are particularly noteworthy.
Google is now recognized as an end-to-end platform instead of just an ecosystem of components. As Google develops they will be tough to beat for breadth, scalability, and speed. Depending on how you think about it, the fact that all this is pretty much restricted to their cloud and not on prem is either a pro or a con. Can Amazon be far behind?
DataRobot certainly takes the prize as the best established automated machine learning platform (AML) having poured lots of its VC money into gaining market share. The entry criteria are at least $5 Million in 2017 revenue and either 150% YoY growth or 200 paying end user organizations. The AML field is now crowded with competent but much smaller competitors and it’s good to see the AML segment recognized through DataRobot’s success. It’s worth noting though that DataRobot does not feature a full extract and prep front end and is usually paired with data prep platforms like Trifacta. Can an acquisition be far behind?
Love the One You’re With
Gartner goes out of its way to point out that a Leader may not be your best choice and that many organizations might find value in niche players more suited to their needs (FICO comes to mind for financial services).
Then again the Gartner methodology for ranking, while certainly sound is not the only way to pick winners. In fact Gartner publishes a completely different ranking “Best Data Science and Machine-Learning Platforms Software of 2018 as Reviewed by Customers”.
This is based on November 2018 data just as is the magic quadrant but the ranking here is done by current users.
In total there were 1,859 reviews submitted for 37 different DS platforms, many too small to be included in the Magic Quadrant. It’s a 5 point scale. Some of the major platforms had over 300 user reviews while several of the smaller platforms had only 1. Here are the top 17 (I’ve eliminated more or less arbitrarily any that didn’t have at least 40 reviews – about 2% of submissions.)
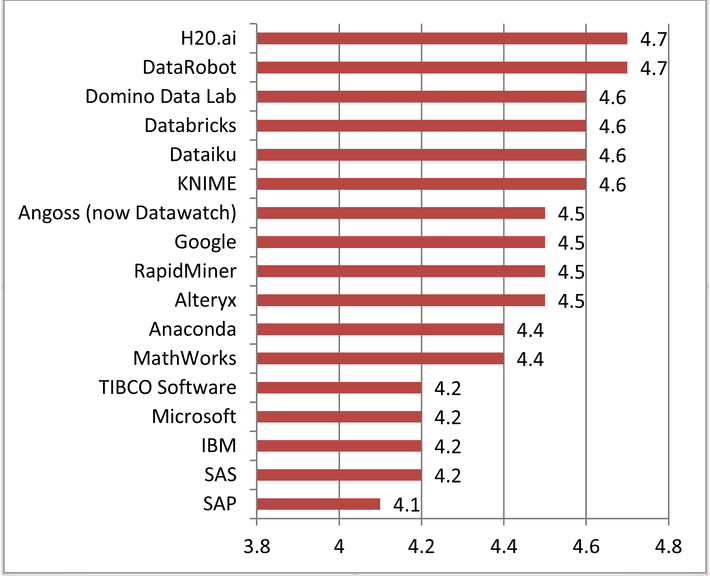
The ranking is significantly different than Gartner’s Magic Quadrant. On the other hand all of these were rated by their users within 6 tenths of a point of each other. Seems these users thought all these platforms were pretty good – so love the one you’re with.
Both Gartner reports have much richer detail which you may want to investigate. The Magic Quadrant is available from several of the platforms that did well this year. I got mine here. Likewise the Customer Review can be found here.
Other articles by Bill Vorhies
About the author: Bill is Editorial Director for Data Science Central. Bill is also President & Chief Data Scientist at Data-Magnum and has practiced as a data scientist since 2001. He can be reached at:
{kind=link}